登录社区云,与社区用户共同成长
邀请您加入社区
C#凭借.NET生态系统在现代软件开发中展现出卓越的跨平台能力。通过.NET 6及更高版本的统一平台,开发者可使用C#构建Windows、Linux、macOS的桌面应用,以及iOS和Android的移动应用(通过MAUI框架)。在企业级应用领域,C#与ASP.NET Core的结合为微服务架构和云原生应用提供强大支持,其高性能的Kestrel服务器和内置依赖注入容器极大提升了开发效率。.NET运
这种机制确保了异常安全,即使在代码执行过程中抛出异常,资源也能被正确回收,避免了传统手动管理中的资源泄漏问题。现代C++的内存管理艺术在于,通过智能指针将资源管理的负担从开发者的大脑中转移给类型系统和标准库。这种思维转变,结合恰当的实践,能够显著减少内存错误,写出更健壮、更清晰的C++代码。智能指针的引入,正是C++标准库为了自动化这一过程、提升代码安全性与可维护性而提供的强大工具,它代表着一种资
从性能角度看,RAII通常没有额外运行时开销,因为资源管理逻辑在编译时确定,其析构函数调用是确定性的,甚至可以被编译器优化。观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。在C++中,策略模式通常通过将算法实现为单独的类,并共享一个公共接口来实现。对于性能敏感的场景,可以考虑使用基于模板的策略模式,在编译时绑定具体策略,从而实现零
本文详细介绍了在超分辨率重建后,如何使用Python正确计算SSIM和PSNR指标,避免常见的ValueError错误。通过解析win_size、channel_axis和data_range等核心参数,提供了一套完整的配置流程和skimage示例代码,帮助开发者高效评估图像质量。
回顾超分辨率重建的发展历程,我们仿佛见证了一场从“魔法”到“科学”的进化。早期的插值法像是一种粗糙的猜测,基于重建和稀疏编码的方法像是精心的手工艺品,而深度学习则赋予了这一领域真正的“智能”。从SRCNN的开疆拓土,到ESRGAN的感知真实,再到SSR-SIM的物理融合,每一次技术突破都在拓展着超分辨率重建的能力边界。今天,这项技术已经从实验室走向真实世界,在安防监控、医学影像、科学发现、文化传承
《数据挖掘》是由汉斯出版社主办的RCCSE中文OA核心期刊(ISSN 2163-145X/2163-1468),聚焦数据结构、数据安全、知识工程等计算机信息系统相关研究。期刊为季刊,审稿周期约2周,要求投稿5000-8000字中文论文(含中英文标题、摘要、关键词),需包含完整的研究框架和参考文献。文章处理费1900元(学生作者享6折优惠),被维普、万方等数据库收录。投稿需通过指定模板(官网可下载)
基于GAN的小目标检测算法总结(2)——MTGAN1.前言2.MTGAN2.1 算法简介2.1.1 核心idea2.1.2网络组成2.1.2.1 base detectors2.1.2.2 生成器2.1.2.3 判别器2.1.3 总体的损失函数2.1.3.1生成器损失函数2.1.3.2判别器的损失函数2.1.4 训练过程2.1.5 测试流程3.一点看法1.前言 这里是基于GAN的小目标检测算法系列
AI算力卡,无线图传,机箱副屏,手机副屏,带屏拓展坞,MINILED算法,电竞高刷方案,视频信号转换方案,AR/VR显示方案,便携显示器方案,液晶屏驱动方案,DLP投影方案AI算力卡,AI视觉算力卡,AI显示算力卡,人工智能算力卡,边缘计算算力卡,边缘算力卡,车载算力卡,工业算力卡
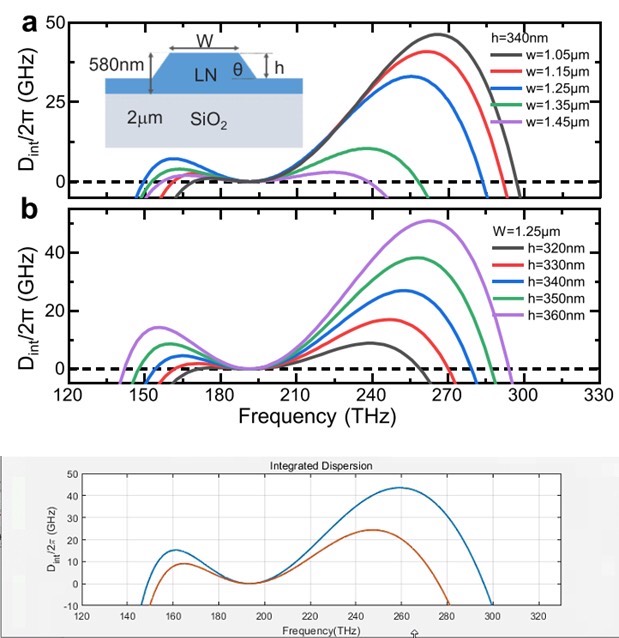
Lumerical Mode联合Matlab计算铌酸锂微环的Integrated Dispersion,可用于分析其在超连续谱、光频梳方面的高阶色散在光电子领域,铌酸锂微环因其独特的光学特性,在超连续谱和光频梳等前沿应用中展现出巨大潜力。而深入理解其色散特性,尤其是高阶色散,对于优化这些应用至关重要。今天咱们就来讲讲如何借助 Lumerical Mode 和 Matlab 联合计算铌酸锂微环的 I
超分辨率重建要求模型在极低计算开销下兼顾高频细节还原与低频结构稳定性,这本质上是对特征空间建模能力与通道语义判别能力的协同优化。传统注意力机制如CBAM、SE因全局池化或忽略空间维度,易导致梯度压缩与伪影;而Transformer类方法又难以满足边缘端<5ms延迟约束。C2PSA通过局部统计驱动的空间门控实现精准纹理感知,DML则以无参动态混合机制,依据输入特征梯度分布实时调节细节增强强度,二者结
计算机视觉中的图像增强技术正经历从传统算法到深度学习的范式转变。基于卷积神经网络和Transformer的现代架构通过端到端学习,能够有效建模图像退化与高质量内容间的复杂映射关系。在图像去雨任务中,多尺度特征融合和注意力机制帮助网络识别不同形态的雨纹;超分辨率重建则利用残差学习和频域约束恢复高频细节。这些技术在监控视频增强、医学影像分析等领域展现巨大价值。以SwinIR为代表的轻量化Transfo
超分辨率重建(SR)作为计算机视觉基础任务,核心挑战在于平衡高频细节恢复与实时推理效率。传统YOLO系列虽具备强检测能力,但其特征融合机制对像素级纹理建模不足,难以满足车牌识别、医学影像等SR场景的亚像素精度需求。C2PSA(跨阶段部分空间注意力)通过语义引导的空间门控与通道自适应重加权,精准强化局部结构响应;DML(动态混合层)则基于输入内容实时调节多路特征贡献,实现非线性通道适配。二者协同构建
超分辨率重建技术是计算机视觉领域的重要研究方向,旨在从低分辨率图像恢复高分辨率细节。其核心原理是通过深度学习模型学习低分辨率到高分辨率的映射关系,但传统方法在超出训练尺度时会出现质量骤降。CASR框架创新性地采用循环单网络架构和超像素分布对齐技术,通过分解超大倍率放大为多个安全步幅,有效解决了跨尺度分布偏移问题。该技术在医疗影像增强、卫星图像重建等场景展现出显著优势,如乳腺X光片放大20倍仍能保持
生成式AI(GenAI)正从概念演示走向气象业务核心环节,其本质是通过结构化场生成能力,弥补传统统计模型在物理一致性与多尺度建模上的根本缺陷。原理上,它不再预测单点值,而是联合约束纳维-斯托克斯方程、质量守恒与位涡守恒等物理规律,实现符合大气动力学的三维场生成。技术价值在于将数值模式输出转化为高分辨率、低延迟、可解释的业务产品,显著提升强对流识别、集合预报不确定性量化与稀疏观测重建能力。典型应用场
本文介绍了如何在HarmonyOS 7.0(API 26)应用中接入图像超分辨率重建功能。该功能通过AI技术将低分辨率图像重建为更清晰的版本,适用于老照片修复、截图增强等场景。文章详细说明了权限配置、分析器创建(含超时保护机制)、图库图片选择及超分处理的关键代码实现,并提供了完整的Demo示例。重点解决了首次调用需联网下载模型、真机运行限制等常见问题,帮助开发者快速集成这一图像增强能力。
本文介绍了如何在星图GPU平台上自动化部署Qwen-Image-Edit-2511-Unblur-Upscale镜像,实现老照片的智能修复与高清放大。该AI工具通过去模糊、超分辨率重建等技术,可快速恢复模糊照片的清晰细节,特别适用于修复家庭老照片、历史文档等珍贵影像资料,让模糊记忆重现生机。
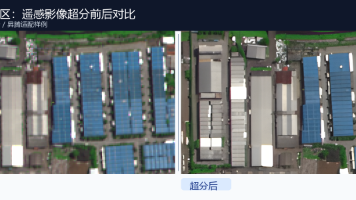
本文围绕遥感影像超分技术,介绍了超分与普通图像放大的区别、典型应用场景、效果评估方法,以及在鲲鹏 + 昇腾国产算力环境下的工程化适配流程。文章重点讨论了 GeoTIFF 大幅面影像分块推理、重叠拼接、ONNX 转 OM、昇腾算子兼容性和 PyTorch/CUDA 模型迁移等关键问题,适合关注遥感智能解译、国产算力部署和超分一体机方案的技术团队参考。
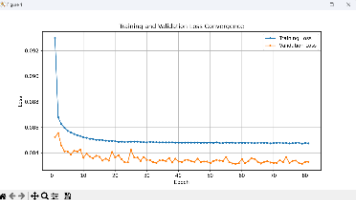
摘要:本文复现了SRCNN、ESPCN、FSRCNN三种轻量级超分算法,并针对农业图像超分任务进行了优化改进。使用7000张农田图像构建数据集,通过高斯模糊(7×7,σ=1.6)+4倍下采样+高斯噪声(σ=0.01)模拟退化过程。在ESPCN中引入简化版SE注意力模块(压缩比8),采用MSE+SSIM组合损失函数。项目提供完整实现方案,包括数据预处理、模型训练(300轮)、评估(PSNR/SSIM
文章摘要:GIS/遥感软件国产化适配面临底层依赖、数据组件和算法环境等核心挑战。适配前需明确软件类型(WebGIS、遥感处理、三维平台等),重点检查操作系统依赖、数据库兼容性、GIS组件支持及AI算力环境。建议按步骤梳理架构、搭建环境、验证功能并测试性能。厂商应提前准备安装包、部署文档等材料以缩短适配周期。国产化适配关键在于确保核心功能、数据能力和算法结果的稳定性,而非简单安装。SAT-CLOUD
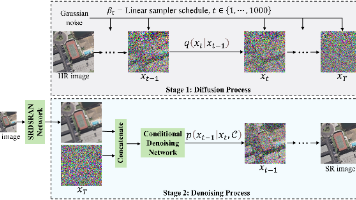
本章以遥感影像的数据特点和内容输出质量为切入点,通过在生成式扩散模型的逆向过程中嵌入引导影像的高维先验信息,提出了一种基于条件引导的扩散模型遥感影像超分辨率重建方法,能够生成伪影更少、清晰度更高的影像样本,并具有良好的语义准确性。我们提出了一种基于卷积神经网络条件引导的扩散模型遥感影像超分辨率方法,结合设计的端到端策略,在包含多种遥感场景的三个遥感影像数据集和真实场景遥感影像数据上进行验证,该方法
本文介绍了论文查重与降重的适用范围及AI学术检测平台功能,主要涵盖: 适用范围 学业论文:本硕博毕业论文(知网/维普查重)、课程论文 期刊发表:中英文期刊投稿、会议论文、综述文章 科研文书:课题申报、职称论文、专利说明书等 AI学术检测平台服务 提供AI生成内容检测、文献查重、图像筛查、参考文献真伪验证 特色:多模型信号分析、海量数据比对、学术诚信全流程监控 优势:早发现风险、规范学术成果、维护科
本文聚焦2026年AI超分辨率重建技术,从技术原理到代码实战完整讲解图片高清化API的落地方法。文章首先解释超分辨率与传统插值放大的本质区别,对比在线工具、API接口、本地部署三大方案的适用场景与成本差异。随后通过证照照片变清晰的实测案例展示API实际效果,并附上Python、Java、PHP、C#四种语言的完整调用代码,帮助开发者快速完成接入。结合市场增长数据和场景化选型指南,为不同业务量级的企
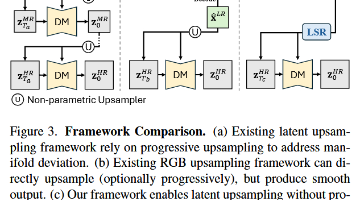
本文提出了一种名为LSRNA(Latent Super-Resolution with Noise Alignment)的新框架,旨在解决扩散模型生成高分辨率图像时的效率瓶颈和结构一致性问题。该方法创新性地将超分辨率过程从像素空间转移到隐空间,通过轻量级隐空间超分网络快速提升分辨率,并设计噪声对齐机制解决分布不匹配问题。实验表明,LSRNA在保持生成质量的同时,将4K图像生成速度提升至现有方法的3
近年来,基于Swin Transformer、扩散模型(Diffusion)以及频域引导的方法,已经能让4倍低分辨率(LR)MRI恢复到接近高分辨率(HR)的解剖细节,同时去除Rician噪声(MRI特有的噪声分布)。在低SNR(SNR<5dB)时,Restormer能恢复出肉眼可见的皮层细节。在通道维度而非空间维度做自注意力,大大降低计算量,并能建模全局色彩/亮度偏差——这对MRI的偏置场噪声很
本文提出了一种基于潜在扩散模型(LDM)的三维脑部MRI超分辨率方法,旨在解决临床MRI扫描中常见的低分辨率问题。传统深度学习方法在输入分布变化时需要重新训练,而本文方法通过LDM构建强大的三维图像先验,避免了这一问题。具体而言,本文提出了两种策略:InverseSR(LDM)和InverseSR(Decoder),分别适用于高稀疏性和低稀疏性的超分辨率场景。实验结果表明,LDM提供的先验能够有效
红外超分,Transformer(HAT)擅长长距离依赖,Mamba擅长线性复杂度高效建模——那能不能两个都用上?NTIRE 2026遥感红外超分第四名I2WM&JNU给出了肯定答案。他们采用HAT-L和MambaIRv2-L双模型独立训练,推理时HAT-L用TLC增强局部细节,MambaIRv2-L用自集成提升稳定性,最后加权融合。
超分辨率重建
——超分辨率重建
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 DAMO开发者矩阵
DAMO开发者矩阵





 脑启社区
脑启社区


 MCP技术社区
MCP技术社区
 2048 AI社区
2048 AI社区

 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 AI硬件创业社区
AI硬件创业社区
 AtomGit开源社区
AtomGit开源社区
 openEuler 社区
openEuler 社区