- @liaomin416100569
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
神经网络是一种基于生物神经系统结构和功能特点而设计的人工神经网络模型,具有很强的自适应性和非线性映射能力。神经网络由多个神经元(或称节点)组成,这些神经元通过连接权重相互连接,构成多层的网络结构。每个神经元接收到来自其它神经元的信号,并将这些信号加权线性组合后通过激活函数进行非线性转换,最终输出给下一层神经元或输出层。学习机器学习后,学习神经网络可以帮助你更深入地理解模式识别和人工智能领域的基础知
你手机上的 App Store 是什么?一个装各种应用的地方——需要点外卖装美团,需要打车装滴滴,需要看视频装 B 站。OpenClaw 的 Skills 系统就是你 AI 助手的 App Store。每个 Skill 是一组文件,通常包括:SKILL.md — 技能说明书(告诉 AI 这个技能做什么、怎么用)配置文件 — API Key、连接参数等脚本文件 — 具体的执行逻辑(如果需要
首先老话重谈说下OpenClaw 是什么,你就知道什么是通道。OpenClaw它是一个完整的 AI Agent 运行平台,他能做什么:是 OpenClaw 这个开源 AI 智能体网关与外部聊天 / 通讯平台之间的,负责把不同平台的消息格式统一、完成认证与消息收发,让你在常用聊天软件里直接使用 AI 助手openclawlab.com。
本文严格参照 OpenClaw 官方安装文档(),完成 OpenClaw 基础安装;后续通过 ClawHub 技能市场()安装高下载量技能,完成功能测试,全程提供可直接复制的命令,适配 macOS/Linux/Windows 系统,新手可直接跟随操作。
你手机上的 App Store 是什么?一个装各种应用的地方——需要点外卖装美团,需要打车装滴滴,需要看视频装 B 站。OpenClaw 的 Skills 系统就是你 AI 助手的 App Store。每个 Skill 是一组文件,通常包括:SKILL.md — 技能说明书(告诉 AI 这个技能做什么、怎么用)配置文件 — API Key、连接参数等脚本文件 — 具体的执行逻辑(如果需要
首先老话重谈说下OpenClaw 是什么,你就知道什么是通道。OpenClaw它是一个完整的 AI Agent 运行平台,他能做什么:是 OpenClaw 这个开源 AI 智能体网关与外部聊天 / 通讯平台之间的,负责把不同平台的消息格式统一、完成认证与消息收发,让你在常用聊天软件里直接使用 AI 助手openclawlab.com。
skywalking简介SkyWalking:一个开放源码,从微服务和云本地基础设施可观测性平台,收集、分析、聚合和可视化数据。提供了一种简便的方法让你看清你的分布式系统,可以看清整个微服务的调用链路。它是一个现代,专门为云本机,容器和分布式系统提供监控的APM(应用性能管理(Application Performance Management))。service map面对以上图情况, ...
构建5*3数组,只是分配了空间未初始化#这里产生个0-1之间的tensor张量,并且初始化print(x1)自己创建的数据集没有做任何维度的转换。for input,label in dsLoader: #四条数据分成了2批,循环两次。
通过linux的虚拟网络隔离,来模拟熟悉交换机,路由器,网卡,网桥等物理设备间的关系和区别。网桥:是一种虚拟设备,可以将 Linux 内部多个网络接口连接起来,一个网络接口接收到网络数据包后,会复制到其他网络接口中,Bridge 是二层设备,仅用来处理二层的通讯。Bridge 使用 MAC 地址表来决定怎么转发帧(Frame)。Bridge 会从 host 之间的通讯数据包中学习 MAC 地址。
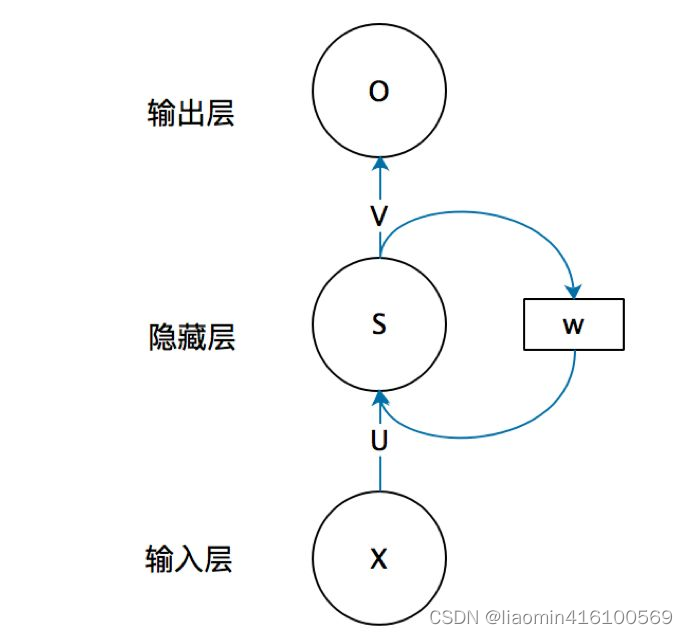
循环神经网络(Recurrent Neural Network,RNN)是一种具有循环连接的神经网络结构,被广泛应用于自然语言处理、语音识别、时序数据分析等任务中。相较于传统神经网络,RNN的主要特点在于它可以处理序列数据,能够捕捉到序列中的时序信息。RNN的基本单元是一个循环单元(Recurrent Unit),它接收一个输入和一个来自上一个时间步的隐藏状态,并输出当前时间步的隐藏状态。在传统的