
写文章




- @qq_44665283
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
经典神经网络(14)T5模型原理详解及其微调(文本摘要)
经典神经网络(14)T5模型原理详解及其微调(文本摘要)

OCR经典神经网络(三)LayoutLM v2算法原理及其在发票数据集上的应用(NER及RE)
OCR经典神经网络(三)LayoutLM v2算法原理及其在发票数据集上的应用(NER及RE)

OCR经典神经网络(二)文本检测算法DBNet算法原理及其在icdar15数据集上的应用
OCR经典神经网络(二)文本检测算法DBNet算法原理及其在icdar15数据集上的应用

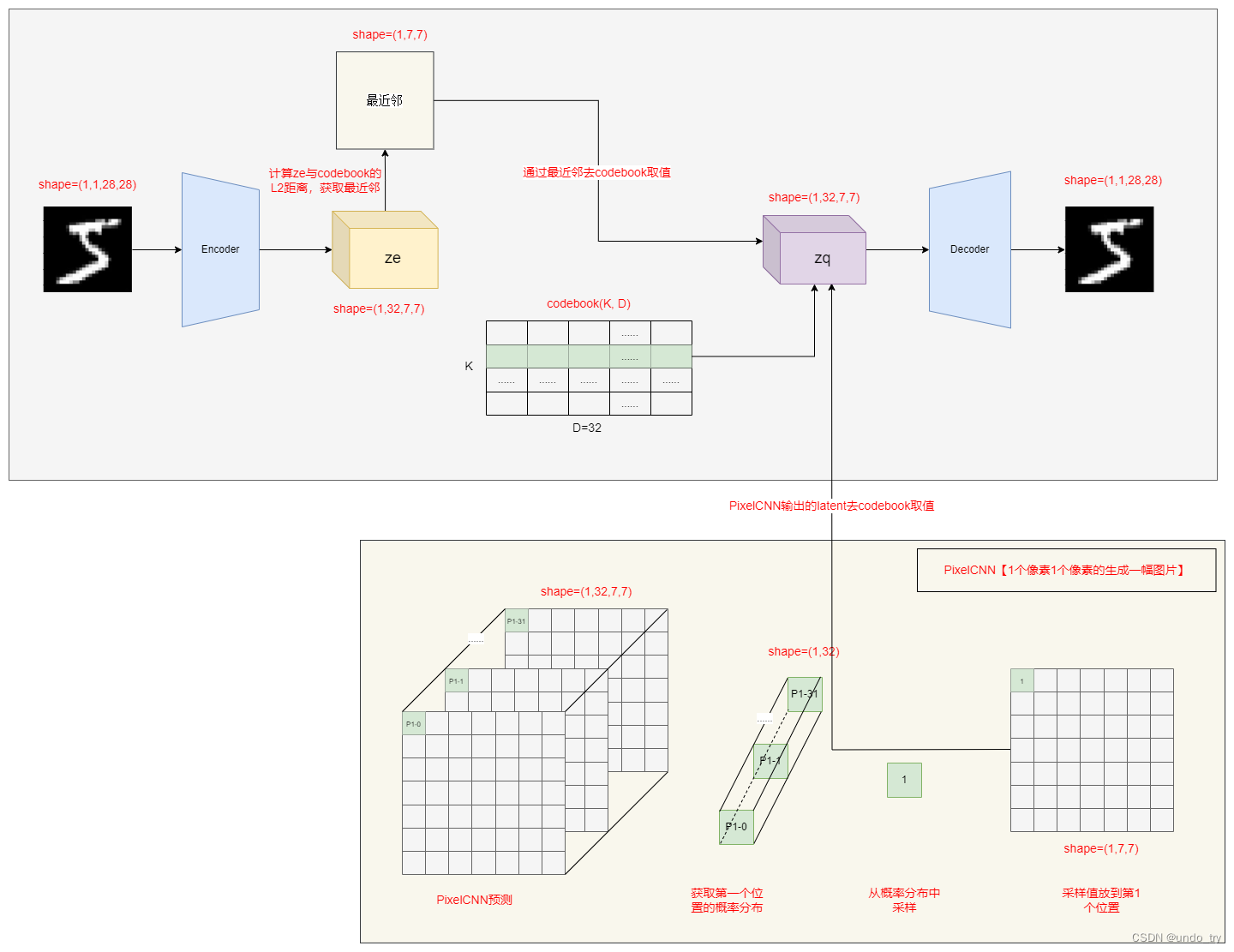
经典神经网络(11)VQ-VAE模型及其在MNIST数据集上的应用
经典神经网络(11)VQ-VAE模型及其在MNIST数据集上的应用
Pytorch常用的函数(十)交叉熵损失函数nn.BCELoss()、nn.BCELossWithLogits()、nn.CrossEntropyLoss()详解
Pytorch常用的函数(九)交叉熵损失函数nn.BCELoss()、nn.BCELossWithLogits()、nn.CrossEntropyLoss()详解
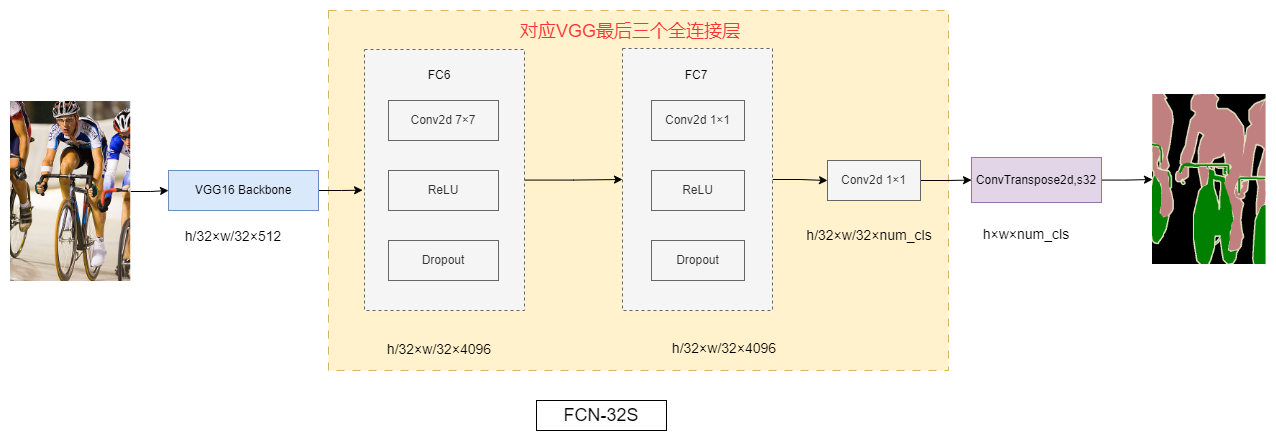
经典语义分割(一)全卷积神经网络FCN
经典语义分割(一)全卷积神经网络FCN
Transformers基本组件(二)快速入门Datasets、Evaluate、Trainer
Transformers基本组件(二)快速入门Datasets、Evaluate、Trainer
经典循环神经网络(一)RNN及其在歌词数据集上的应用
经典循环神经网络(一)RNN及其在歌词数据集上的应用
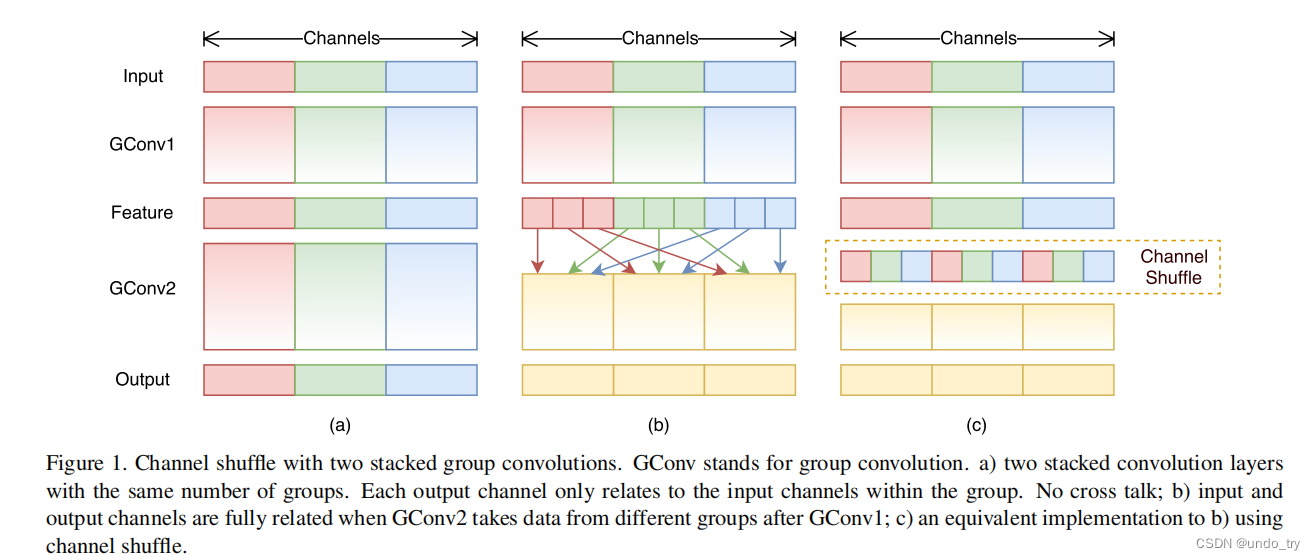
经典轻量级神经网络(3)ShuffleNet V1及其在Fashion-MNIST数据集上的应用
经典轻量级神经网络(3)ShuffleNet V1及其在Fashion-MNIST数据集上的应用
经典轻量级神经网络(2)MobileNetV2及其在Fashion-MNIST数据集上的应用
经典轻量级神经网络(2)MobileNetV2及其在Fashion-MNIST数据集上的应用