




- @u010503464
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ppo算法作为强化学习领域out of art的算法,如果你要学习强化学习的话 ppo会是你最常用的算法。openai早已把ppo 作为自己的默认算法,所以我希望你能认真学完ppo算法并为自己所用。
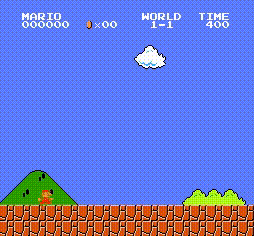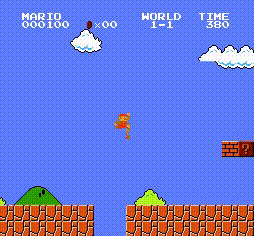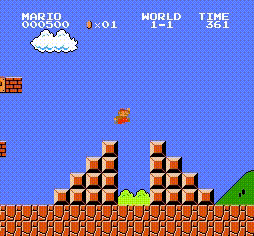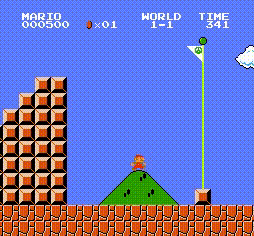
一个动作执行后,环境会返回四个变量(obj:新的状态(对照前面环境初始化的状态理解)、reward:指定该动作获得的奖励值(在游戏中的得分)、done:回合是否结束(你控制的小人是不是死了,对应回合结束)、info:额外信息(该游戏较简单,info为空))是{1,2,3,4,5,6,7,8}中的一个数字,表示世界 是{1,2,3,4}中的一个数字,表示一个世界中的阶段 是{0,1,2,3}中的一个

DCGAN 是第⼀个全卷积 GAN,⿇雀虽⼩,五脏俱全,最适合新⼈实践。DCGAN的⽣成器和判别器都采⽤了4层的⽹络结构。⽣成器⽹络结构如上图所⽰,输⼊为1×100的向量,然后经过⼀个全连接层学习,reshape为 4×4×1024的张量,再经过4个上采样的反卷积⽹络层,⽣成64×64的图,各层的配置如下:判别器输⼊64×64⼤⼩的图,经过4次卷积,分辨率降低为4×4的⼤⼩,每⼀个卷积层的配置如下

生成对抗网络(GANs)是当今计算机科学领域最有趣的想法之一。两个模型通过对抗过程同时训练。一个生成器(“艺术家”)学习创造看起来真实的图像,而判别器(“艺术评论家”)学习区分真假图像。训练过程中,生成器在生成逼真图像方面逐渐变强,而判别器在辨别这些图像的能力上逐渐变强。当判别器不再能够区分真实图片和伪造图片时,训练过程达到平衡。
在前上采样框架中首先使用反卷积来完成上采样是一种很自然的操作,但是它计算复杂度较大,因此SRCNN的作者后来将该上采样过程放置在网络最后端,通过一个反卷积来学习该上采样过程,将其命名为FSRCNN框架。而Twitter图片与视频压缩研究组则采用了与反卷积完全不同的上采样思路,提出了ESPCN模型,其中核心思想是亚像素卷积(sub-pixel convolution),完整流程示意图如下:

import os# 生成器损失定义self.mse_loss = nn.MSELoss() # MSE损失self.tv_loss = TVLoss() # TV平滑损失# 对抗损失# 感知损失# 图像MSE损失# TV平滑损失# TV平滑损失生成器损失总共包含4部分,分别是对抗网络损失,逐像素的图像MSE损失,基于VGG模型的感知损失,用于约束图像平滑的TV平滑损失。

一个动作执行后,环境会返回四个变量(obj:新的状态(对照前面环境初始化的状态理解)、reward:指定该动作获得的奖励值(在游戏中的得分)、done:回合是否结束(你控制的小人是不是死了,对应回合结束)、info:额外信息(该游戏较简单,info为空))是{1,2,3,4,5,6,7,8}中的一个数字,表示世界 是{1,2,3,4}中的一个数字,表示一个世界中的阶段 是{0,1,2,3}中的一个
import os# 生成器损失定义self.mse_loss = nn.MSELoss() # MSE损失self.tv_loss = TVLoss() # TV平滑损失# 对抗损失# 感知损失# 图像MSE损失# TV平滑损失# TV平滑损失生成器损失总共包含4部分,分别是对抗网络损失,逐像素的图像MSE损失,基于VGG模型的感知损失,用于约束图像平滑的TV平滑损失。
计算机体系结构(国防科大)-实验一-WinDLX流水线
查看进程PID的几种方法记录-20230328
