




- @m0_56255097
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器学习的目标是对计算机编程,以便使用样本数据或以往的经验来解决给定的问题。已经有许多机器学习的成功应用,包括分析以往销售数据来预测客户行为,人脸识别或语音识别,优化机器人行为以便使用最少的资源来完成任务,以及从生物信息数据中提取知识的各种系统。

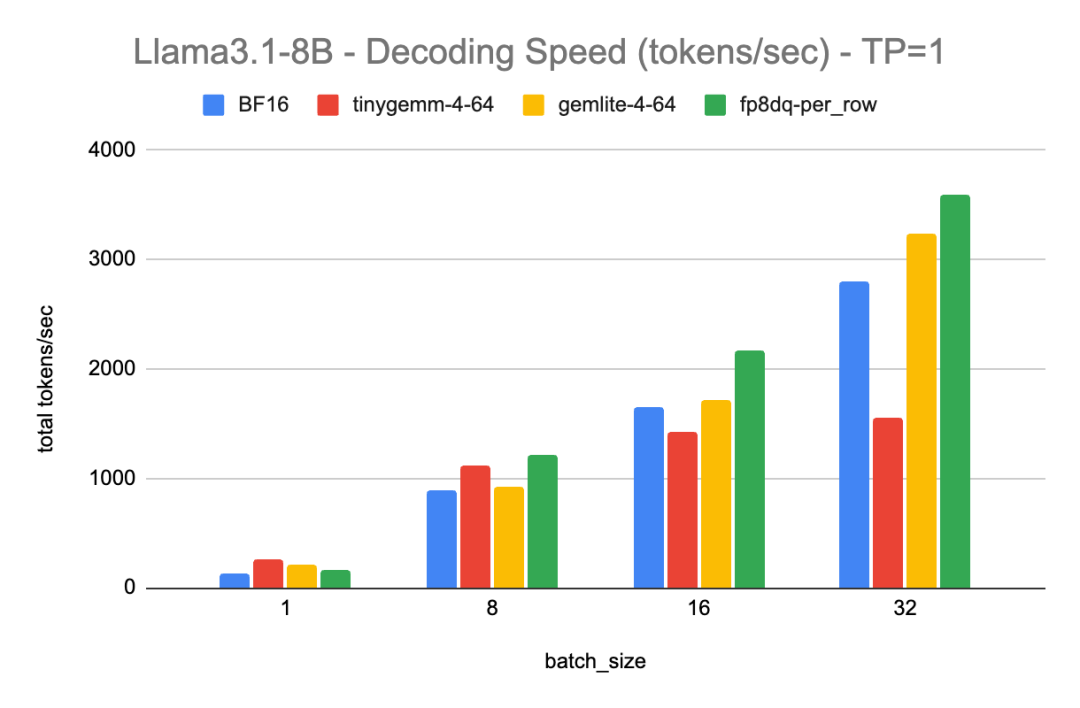
大型语言模型(LLMs)通常对计算资源需求极高,需要大量的内存、计算能力和功耗才能高效运行。量化技术通过将权重和激活值从 16 位浮点数降低到更低的比特率(如 8 位、4 位、2 位),从而实现显著的加速和内存节省,同时还支持更大的 batch size。现有的低精度推理方案在小 batch size 场景下表现良好,但存在以下问题:当 batch size 增大时,性能下降对量化类型的限制,例如
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

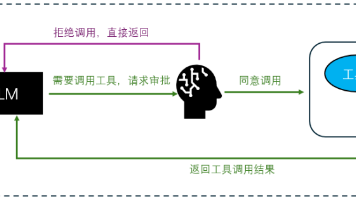
人机交互(Human-in-the-loop, HITL)指智能体为了向人类索要执行权限或额外信息而主动中断,并在获得人类反馈后继续执行的过程。LangChain 的人机交互功能可以通过内置中间件 HumanInTheLoopMiddleware实现。触发人机交互后,HITL 会将当前状态保存到 checkpointer 检查点中,并等待人类回复。获得回复后,再将状态从检查点中恢复出来,继续执行任
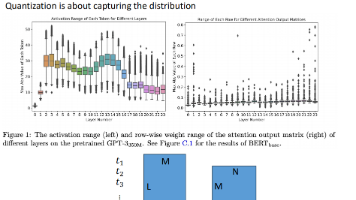
一句话定义量化是什么?量化是指将模型中原本以高精度表示的权重和激活值映射为低比特离散值的过程,以在几乎不损失模型性能的前提下,大幅降低计算与存储开销。
随着智能设备的普及和物联网技术的飞速发展,我们正迎来一个全新的智能互联时代。在这个时代,设备之间的界限变得模糊,而用户体验的无缝连接成为了新的追求。华为的鸿蒙系统(HarmonyOS)正是为这个时代而生的操作系统,它不仅为用户带来了全新的智能体验,也为开发者提供了无限的开发可能。

随着华为鸿蒙系统的兴起,一个全新的生态体系迅速壮大,随之而来的是人才市场热火朝天。春节后首周,鸿蒙相关职位招聘同比增长163%,求职者也猛增349%。这显示出鸿蒙生态快速发展,对人才需求量大增。

AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
