




- @m0_64768308
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
指标,是反映某种事物或现象,描述在一定时间和条件下的规模、程度、比例、结构等概念,通常由指标名称和指标数值组成.简单计数型指标:指可通过重复加1这一数学行为而获得数值的指标,如UV(Unique Visit , 独立访客数)、PV(Page View,页面浏览量)复合型指标:由简单计数型指标经四则运算后得到的,如跳出率、购买转化率,MAU月活跃用户数,CTR=点击UV/曝光UV,用户留存率=继续的
边缘计算着重要解决的问题,是传统云计算(或者说是中央计算)模式下存在的高延迟、网络不稳定和低带宽问题。边缘计算起源于广域网内搭建虚拟网络的需求,运营商们需要一个简单的、类似于云计算的管理平台,于是微缩板的云计算管理平台开始进入了市场,从这一点来看,边缘计算其实是脱胎于云计算的。)的不断发展,人们发现这一平台有着管理成千上万边缘节点的能力,且能满足多样化的场景需求,经过不同厂商对这一平台不断改良,并
Knox方法基于临界空间和时间距离量化时空相互作用。测试统计量X是那些相距小于临界空间和时间距离的案例对的计数。当存在交互时,成对的案例将彼此接近,并且测试统计将很大。Knox设计了这种方法来考虑潜伏期。潜伏期是从暴露到症状出现之间的时间。如果你怀疑一种潜伏期为3天的疾病,将时间临界距离设置得足够长,以允许症状出现,比如4天或5天。ST-DBSCAN 以地理位置距离作为半径,时间范围作为高,在空间
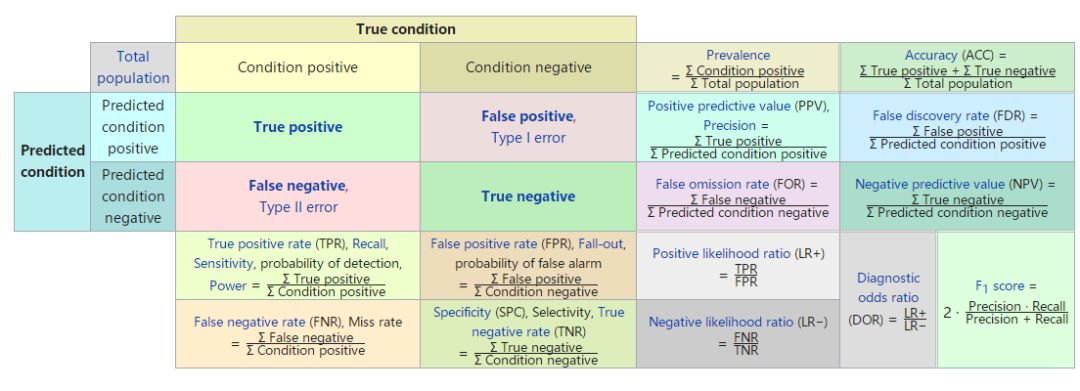
Ⅰ. 分类问题常用精度 Accuracy混淆矩阵查准率(准确率)查全率(召回率)PR曲线与AP、mAPF值ROC曲线与AUC值Ⅱ. 回归拟合R2决定系数平均绝对误差(MAE mean absolute error)均方误差(MSE mean squared error)均方根误差(RMSE root mean squared error)Ⅲ. 聚类模型评估1. 簇内误差平方和SSE....
推荐模型如何进行推荐将取决于您拥有的数据类型。如果您只拥有过去发生的交互数据,您可能有兴趣使用协作过滤。如果您有描述用户及其与之交互过的物品的数据(例如,用户的年龄、餐厅的菜系、电影的平均评价),您可以通过添加内容和上下文过滤,对当前给定这些属性下新交互的可能性进行建模。推荐系统中最为主流与经典的技术之一是(Collaborative Filtering),它是基于这样的假设:用户如果在过去对某些
异常检测实际案例:网络安全中的攻击检测,金融交易欺诈检测,疾病侦测,和噪声数据过滤等。时间序列的异常又分为点异常和模式异常。对于一个新观测值进行判断:离群点检测: 训练数据包含离群点,即远离其它内围点。离群点检测估计器会尝试拟合出训练数据中内围点聚集的区域, 会忽略有偏离的观测值。新奇点检测: 训练数据未被离群点污染,我们对新观测值是否为离群点感兴趣。在这个语境下,离群点被认为是新奇点。离群点检测
结合起来交付给用户使用。企业的运营管理、决策分析都将基于云平台展开,人们将会过起一种“云上的日子”。它是一个系统、总体的概念、业务与技术融合的一体化概念,这一点对认识云很重要。从技术的角度来说,是将企业所有的服务器、存储等基础设施以及网络整合到统一的云平台上。在“云的世界”里,将。早期的云计算就是虚拟化主机上的分布式计算,现阶段的云计算,已经不单单是一种分布式计算,而是。等计算机技术混合演进并跃升
对称加密方法使用单个加密密钥来加密和解密数据。对这两个操作使用单个键使其成为一个简单的过程,因此称为“对称”。对称加密的最突出特征是其过程的简单性。这种加密的这种简单性在于使用单个密钥进行加密和解密。AES代表“高级加密系统”,是最广泛使用的加密算法之一,并且是DES算法的替代方法。AES也称为Rijndael,在2001年经NIST批准后成为一种加密标准。与DES不同,AES是一组分组密码,由不
指标,是反映某种事物或现象,描述在一定时间和条件下的规模、程度、比例、结构等概念,通常由指标名称和指标数值组成.简单计数型指标:指可通过重复加1这一数学行为而获得数值的指标,如UV(Unique Visit , 独立访客数)、PV(Page View,页面浏览量)复合型指标:由简单计数型指标经四则运算后得到的,如跳出率、购买转化率,MAU月活跃用户数,CTR=点击UV/曝光UV,用户留存率=继续的
先确保Hadoop是否安装:Apache Hadoop官网下载地址注意对应版本号配置环境变量HADOOP_HOME后cmd检查版本和是否配置成功:Hadoop version此外,windows本地运行需要winutils.exewinutils:由于hadoop主要基于linux编写,winutil.exe主要用于模拟linux下的目录环境。当Hadoop在windows下运行或调用远程Hado