- @zcyzcyjava
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近上网,发现自己的百度搜索每次搜索之后都自动跳到www.baidu.com/?tn=~~~~_hao_pg 这样带有尾巴的搜索页 ,感觉非常恼怒,这些人为了推广自己的主页,不择手段。
在这项工作中,我们首次提出了语义图像生成和编辑的统一方法,利用预先训练的图像-文本联合编码器(本文指clip)来引导图像生成模型。我们的方法是通过使用多模态编码器来定义一个损失函数,评估(文本,图像)对的相似性,并反向传播到图像生成器的潜在空间。

从开放领域的文本提示中生成和编辑图像是一项具有挑战性的任务,到目前为止,需要昂贵的和经过专门训练的模型。我们为这两项任务展示了一种新的方法,它能够通过使用多模态编码器来指导图像的生成,从具有显著语义复杂性的文本提示中产生高视觉质量的图像,而无需任何训练。我们在各种任务上证明了使用CLIP来指导VQGAN产生的视觉质量比之前不太灵活的方法如minDALL-E、GLIDE和Open-Edit更高。
本文将逐渐介绍近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
内存分配不足:需要160MB,,但GPU只剩下135.31MB,
当我们在Github上下载一篇论文的代码后,我们如何在自己的数据集上进行复现呢?这是在百度爬的十分类的服装数据集,其中train文件夹下每类大概300张,val文件夹下每类大概100张,总共在4000张左右。
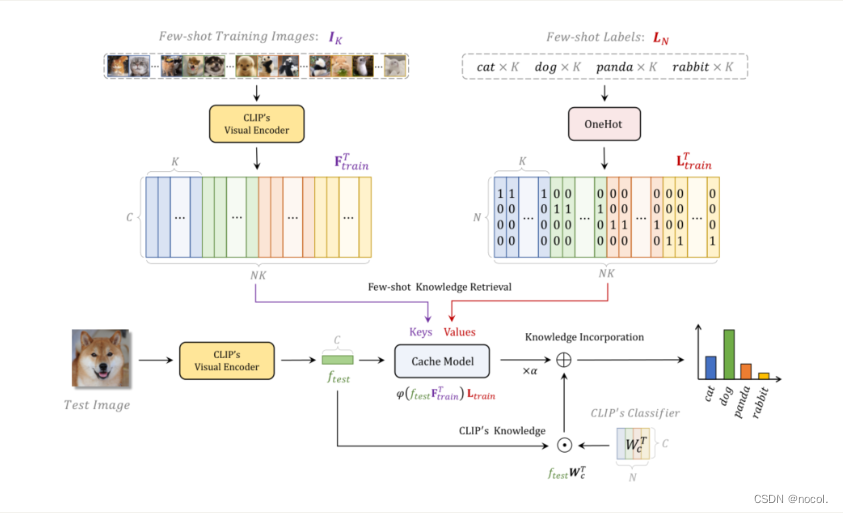
Tip-Adapter通过一个键值缓存模型从几张照片的训练集中构建适配器,并通过特征检索更新CLIP中编码的先验知识。此外,在此基础上,通过对缓存模型的微调,Tip-Adapter的性能可以进一步提升到ImageNet上的最先进水平,比现有的方法少10倍的epochs,这既有效又高效。.........
在使用URL下载或跑模型的时候,报错urllib.error.URLError: URL访问问题,可能是是浏览器的问题,也可能是是URL。1.关闭VPN,报错消失。
之后我们通过Xshell连接这个远程服务器,主机端口就是你开的服务器的共有ip地址,密码就是上面修改过后的密码,用户名是root,端口号默认22。按照下图指示选择(其中预装应用Lamp可选可不选,后期可以在宝塔面板自定义安装)之后重置实例密码(后续Xshell连接会用到),重启生效。之后点击用户身份验证,输入用户名,密码,连接成功。在浏览器输入外网地址,在弹框中输入用户名和密码。进入阿里云官网,打
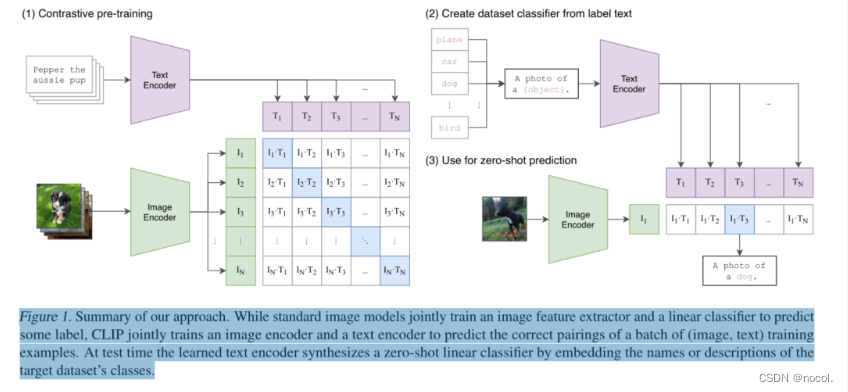
CLIP使用的预训练方法:预测哪个标题与哪个图片相配这一简单的预训练任务是一种高效且可扩展的方式,可以在从互联网上收集的4亿对(图片、文本)数据集上从头开始学习SOTA图片表征。在预训练之后,自然语言被用来引用所学的视觉概念(或描述新的概念),使模型能够zero-shot地转移到下游任务中。......