




- @weixin_43707042
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
windows远程连接linux服务器进行操作,有多种方式。可以借助ssh客户端,MobaXtermfinalshell等,这两个我觉得是不错的软件。当然如果需要在服务器编写代码,我还是建议使用vscode这个神奇的工具。怎么用vscode远程连接服务器代码呢?

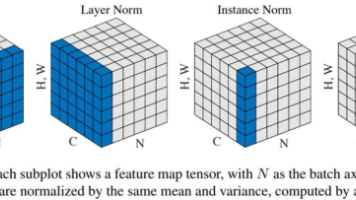
本文记录总结pytorch中四种归一化方式的原理以及实现方式。方便后续理解和使用。
新电脑配置pytorch深度学习环境,附录有安装包哦
解决vscode的python3.6调试问题
本文介绍了PyTorch3D库的安装方法。由于直接pip install pytorch3d会失败,提供了两种解决方案:使用conda安装(conda install pytorch3d -c pytorch3d)或通过pip安装Git仓库。重点解决了pip安装时可能遇到的"ModuleNotFoundError: No module named 'torch'"问题,这是由于
本文记录总结pytorch中四种归一化方式的原理以及实现方式。方便后续理解和使用。
本文记录总结pytorch中四种归一化方式的原理以及实现方式。方便后续理解和使用。
这个错误提示表明脚本文件中的文件夹路径存在问题,导致无法找到指定的文件夹。其中的 \r 字符表示回车符,可能是由于脚本文件在不同操作系统或文本编辑器之间的换行符差异导致的。其实就是将文件中的\r\n 转换为\n。另外需要注意的是:尽量手动输入文件夹路径:因为如果其他地方复制了文件夹路径,粘贴可以会有不可见的特殊字符干扰。linux系统下的文本编辑器好像换行符也是\r\n,因此我在ubuntu下写s

使用windows写了一个QT+Opencv的测试程序,想使用ubuntu系统跑,但是发现linux系统中运行QT不太顺利。出现“qt.qpa.plugin: Could not load the Qt platform plugin “xcb“

colmap常用于多视图重建,即利用多个相机多个视图 或单个相机多个视图重建3D信息,获取相机内外参,其构建的点云是3DGS\4DGS 多视角渲染的初始化条件。但官方仅提供windows系统的cuda版本,如果linux/ubuntu要安装cuda版本用于加速重建,或密集重建,需要自己编译。由于自己在此踩了比较多的坑,因此记录一下。