




- @futureflsl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
访问 Cherry Studio 官网 或 GitHub 仓库,选择对应操作系统的安装包(支持 Windows/macOS/Linux),如果下载不下来可以尝试国内镜像gitee.com/FIRC/fircfiles/blob/master/cherrystudio。点击下一步,选择自己需要安装目录注意不要有空格和中文路径。双击安装包运行,按向导选择安装路径和语言(默认中文)。完成安装后,启动客
标注类别名称:["Alligator crack","Longitudinal crack","Oblique crack","Obliquecrack","Pothole","Repair","Transverse crack"]格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不

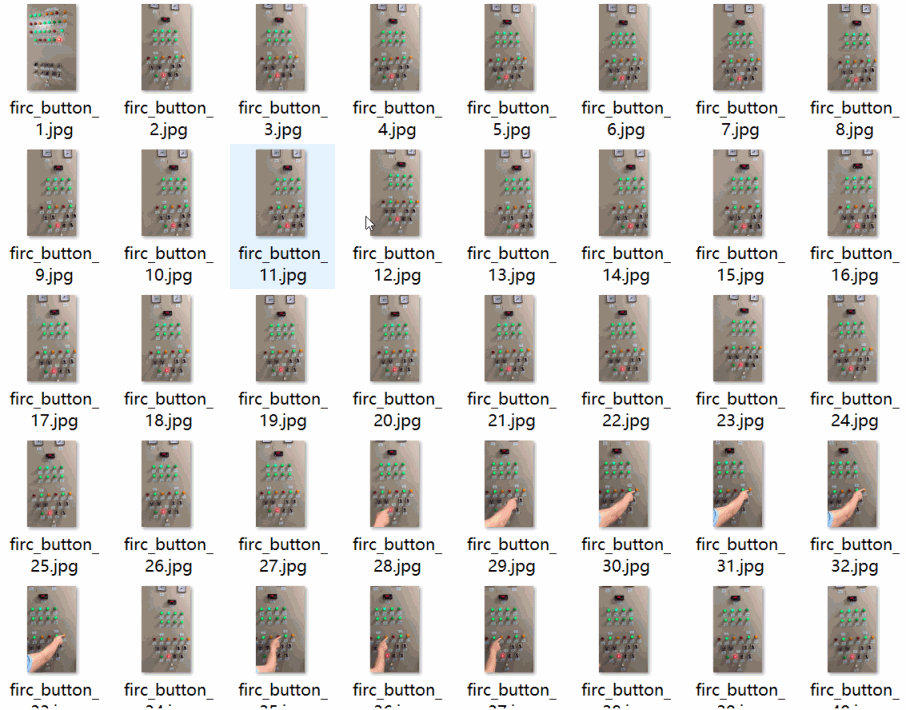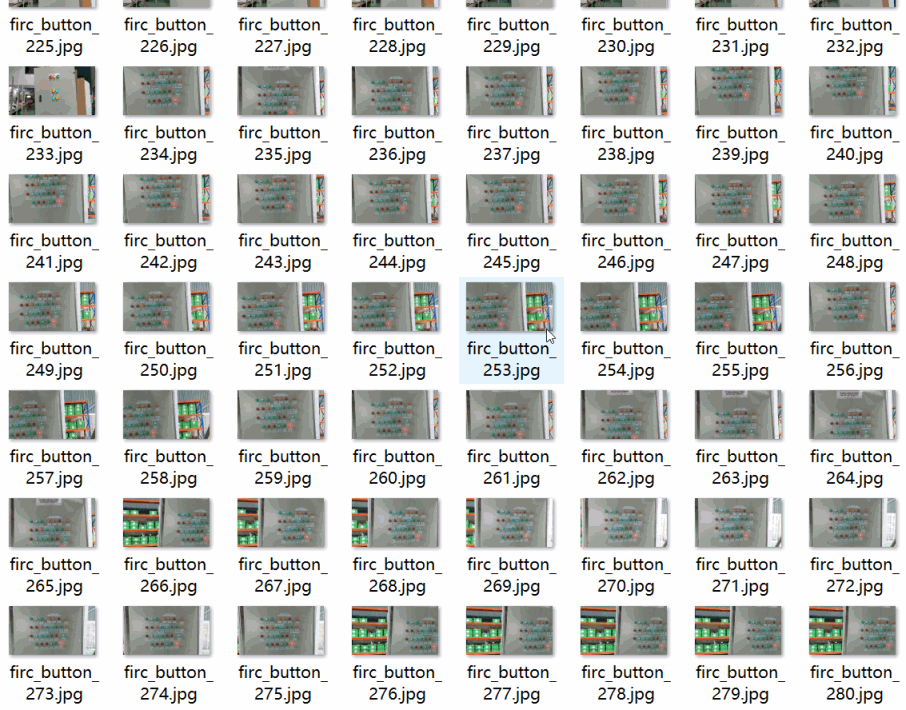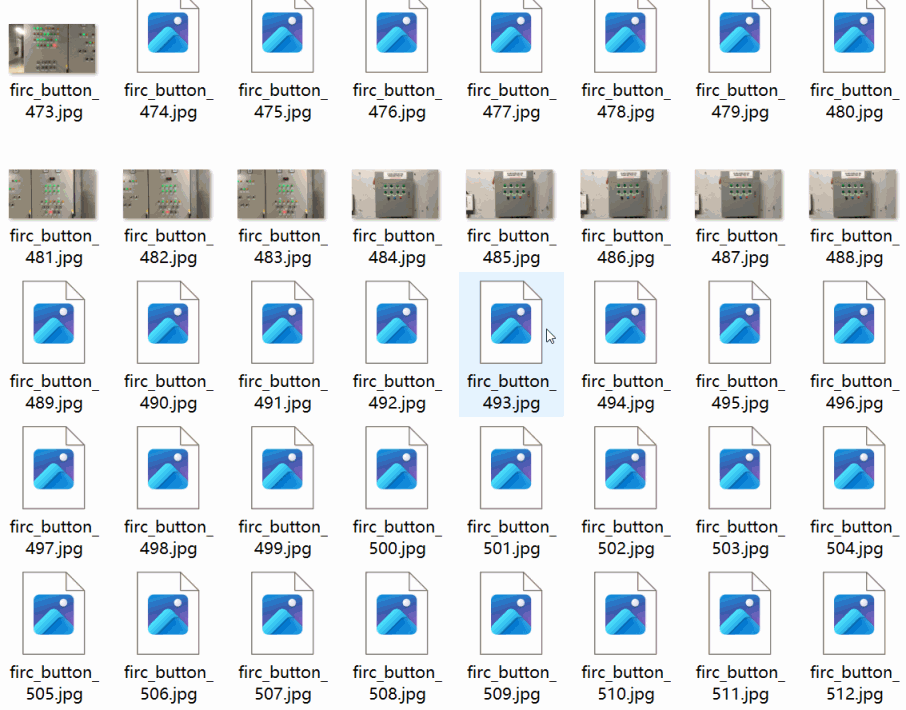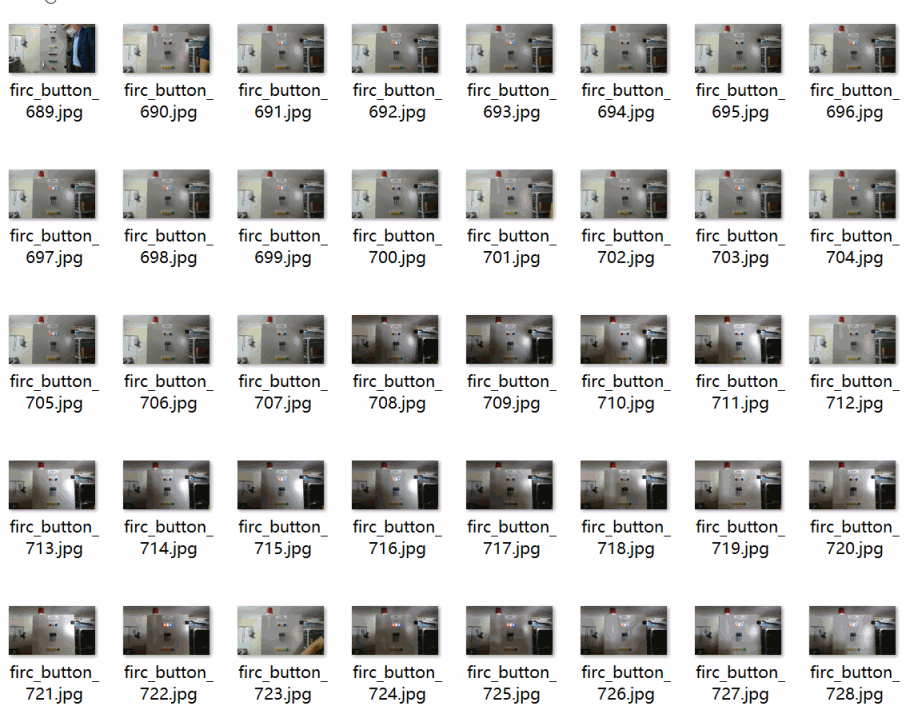
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。图片数量(jpg文件个数):769。标注数量(xml文件个数):769。标注数量(txt文件个数):769。标注类别名称:["button"]button 框
重要说明:数据集里面包含一个yolov5-7.0训练的s的pytorch模型,训练了150epoch,一共有3个类别{0: 'pedestrians', 1: 'riders', 2: 'partially-visible persons'},注意数据集只提供一个类别person。格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml

数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["break","lack","scratch"]图片数量(jpg文件个数):2978。标注数量(xml文件个数):2978。标注数量(txt

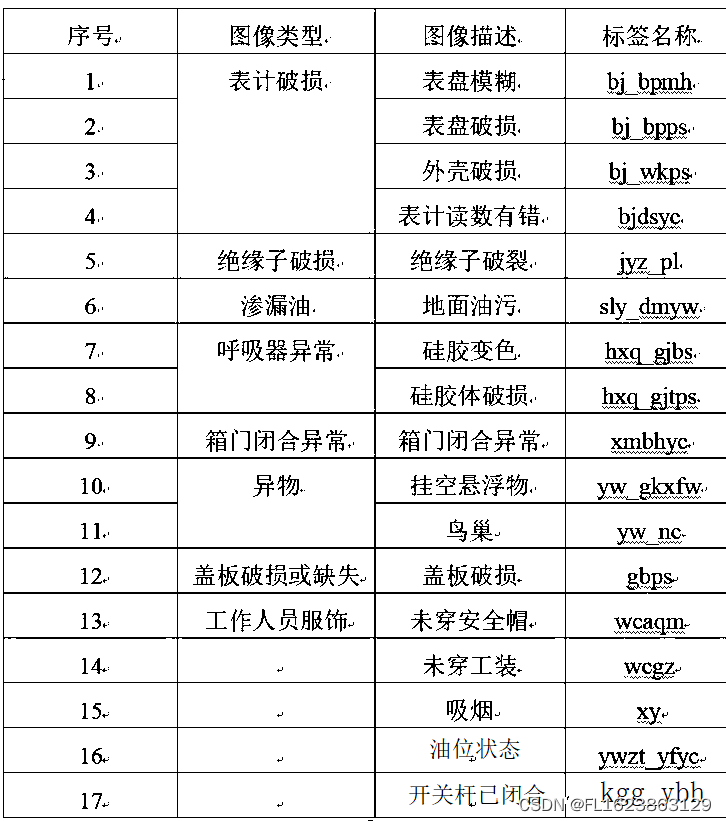
标注类别名称:[“bj_bpmh”,“bj_bpps”,“bj_wkps”,“bjdsyc”,“gbps”,“hxq_gjbs”,“hxq_gjtps”,“jyz_pl”,“kgg_ybh”,“sly_dmyw”,“wcaqm”,“wcgz”,“xmbhyc”,“xy”,“yw_gkxfw”,“yw_nc”,“ywzt_yfyc”]格式:Pascal VOC格式+YOLO格式(不包含分割路径的tx
格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注。标注类别名称:["bolt","bulk"]图片数量(jpg文件个数):2220。标注数量(xml文件个数):2220。标注数量(txt文件个数):2220。使用标

¶文本识别模块是OCR(光学字符识别)系统中的核心部分,负责从图像中的文本区域提取出文本信息。该模块的性能直接影响到整个OCR系统的准确性和效率。文本识别模块通常接收文本检测模块输出的文本区域的边界框(Bounding Boxes)作为输入,然后通过复杂的图像处理和深度学习算法,将图像中的文本转化为可编辑和可搜索的电子文本。文本识别结果的准确性,对于后续的信息提取和数据挖掘等应用至关重要。
PaddleOCR是由百度研发的一款OCR(Optical Character Recognition,光学字符识别)开源工具,它基于飞桨深度学习开源框架,旨在打造一套丰富、领先且实用的OCR工具库,以打通数据准备、模型训练、压缩和推理部署的全流程。
登录提示: