




- @weixin_44109827
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. 数据集2. 实现2.1 代码from sklearn.datasets import fetch_20newsgroupsfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.naive_bayes
结果:R2:EVS:结论: 虽然我们在加利福尼亚房子价值数据集上的MSE相当小,但我们的 却不高,这证明我们的模型比较好地拟合了数据的数值,却没有能正确拟合数据的分布。
一共有20640个实例,其中total_bedrooms的缺失值有20640-20433=207个,除了ocean_proximity以外,其他属性都是数值型。整个数据集的分布:分层采样完测试集的分布:P.S.这是我看《机器学习实战:基于Scikit-Learn和TensorFlow》的读书笔记,代码都是跟着书上一步步自己敲得,如果需要代码,可以私信我。
前言:我的问题是这样的,在b站跟着博主一起在Anaconda环境下安装gpu版本的pytorch,步骤都是一样,但是最后利用torch.cuda.is_available()验证的时候,返回值一直都是False。在虚拟环境中利用conda list 查看已下载的pytorch的信息,显示的是cpu版本的,这样安装卸载几个来回,终于在csdn上找到了答案,问题已经成功解决。我参考的文章地址是:Pyt
dropna()是pandas库中的一个函数,用于删除DataFrame中的缺失值。具体来说,该函数会返回一个新的DataFrame,其中已经将包含删除了缺失值的行或列。
【代码】【深度学习实战】使用卷积神经网络(LeNet-5)对mnist数据集进行多分类。
1. 数据集特征值目标值共569个样本,30维特征。2.代码实现2.1 未调参时的代码及结果# 获取数据集data = load_breast_cancer()# 建模rfc = RandomForestClassifier(n_estimators=100, random_state=90) # 交叉验证rfc_score = cross_val_score(rfc, data.data, da
【机器学习实战】对加州住房价格数据集进行回归预测(线性回归、决策树、随机森林)
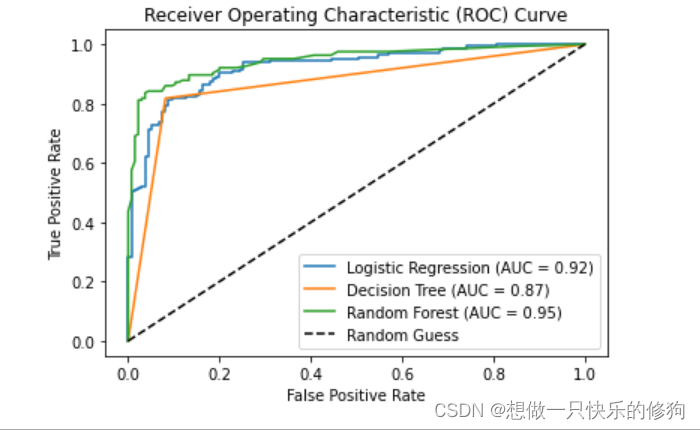
【代码】【机器学习实战】分类算法评估之ROC曲线绘制(多模型对比)
结果:R2:EVS:结论: 虽然我们在加利福尼亚房子价值数据集上的MSE相当小,但我们的 却不高,这证明我们的模型比较好地拟合了数据的数值,却没有能正确拟合数据的分布。