登录社区云,与社区用户共同成长
邀请您加入社区
一、概述Node2vec算法通过调用word2vec算法,把网络中的节点映射到欧式空间,用向量表示节点的特征。Node2vec算法通过回退参数 P 和前进参数 Q 来生成从每个节点出发的随机步,带有BFS和DFS的混合,回退概率正比于1/P,前进概率正比于1/Q。每个节点出发生成多个随机步,反映出网络的结构信息。适用场景:Node2vec算法适用于节点功能相似性比较、节点结构相似性比较、社团聚类等
NLP语言模型NLP语言模型包括概率语言模型和神经网络语言模型统计语言模型:N-gram神经网络语言模型:word2vec,fasText,GloveN-gram基于概率的判别模型,输入为一句话输出为这句话的概率,即单词的联合概率特点:某个词的出现依赖于其他若干个词,获得的信息越多预测越准确。n-gram本身是指一个由n个单词组成的集合,各单词之间有先后顺序且不要求单词...
将句子的概率分解为各个单词条件概率的乘积,如果文本较长, 条件概率的估算会非常困难(维数灾难),所以就规定当前词只和它前面的n个词有关,与更前面的词无关,每一个词只基于其前面N个词计算条件概率 —— N-gram语言模型,一般N取1到3之间。词的静态表征,不能解决同义词问题,如水果中的“苹果”和苹果公司的“苹果”,词向量表示是一样的,而实际上这两词的意思完全不一样。,来作为我们每个词的向量表示(词
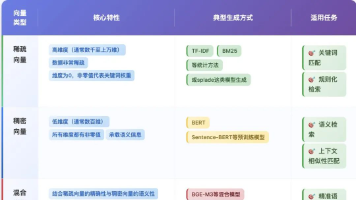
文章是"向量数据库POC指南"系列之二,重点讲解在大模型落地过程中如何科学选择embedding模型。文章介绍了embedding的本质、三类向量特性对比、评估模型的八大要素(如上下文窗口、分词方式、向量维度等),并对Word2Vec、BERT、BGE-M3等主流模型进行了分析。最后提供了实施建议,强调应根据业务场景选择最适合的模型,而非追求单一最优解。
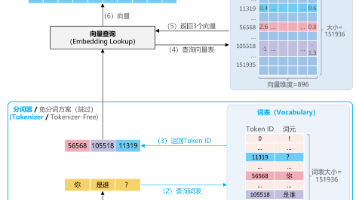
本文解析了大模型生成内容的技术流程:首先通过分词将输入转为TokenID,再经词嵌入转换为高维向量;随后通过多Decoder层进行语义编码,利用自注意力机制捕捉上下文;最后由LMHead生成概率分布,通过迭代采样逐词输出完整回答。整个过程展现了LLM如何基于数学计算模拟语言理解,而非真正"理解"语义。文章提供了相关技术文档供深入学习。
Embedding阶段使用Doc2Vec生成词向量,并用随机森林进行baseline训练
从Word2Vec到FastTextWord2Vec在深度学习中的应⽤⽂本⽣成(Word2Vec + RNN/LSTM)⽂本分类(Word2Vec + CNN)文本生成神经网络:一堆公式组成的非线性回归模型普通神经网络[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5L4DEtMn-1653990033441)(E:/A%20wangdanxu/%E6%9D%82%E
【自然语言处理】实验2布置:Word2Vec & TransE案例
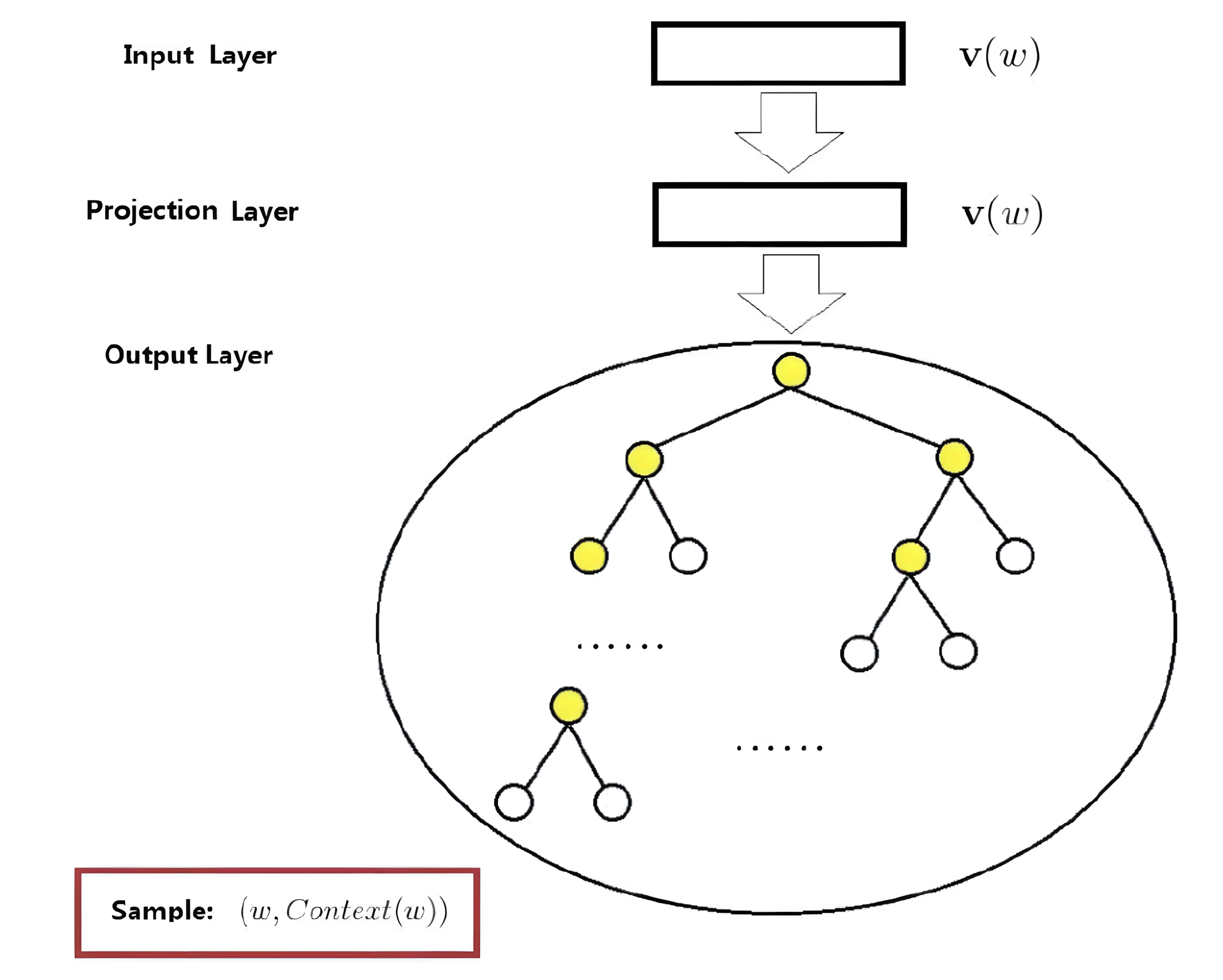
本章我们详细解释了 word2vec 的 CBOW 模型,(具体实现可以参考书中代码)。CBOW模型基本上是一个2层的神经网络,结构非常简单。
博主这次做的实验很难,但是想法很好,我觉得基础不好的可能都看不懂我的题目,在这篇博客里,博主会附上我得代码,大家可以好好学习一下。注:word2vecdata.txt为文本其中吗,每一个问一个句子。这个实验分如下几个部分。训练部分代码如下,同时。
word2vec+xgboost分类代码+文本分类计算机毕设+论文完整的
python使用的编码格式,防止源码中出现中文或其他语言时出现的乱码问题。#coding:utf-8在开头定义一些变量,并赋给变量初始值(初始值是自己定义的,可以随项目要求任意赋值)。# 每条新闻最大长度MAX_SEQUENCE_LENGTH = 100# 词向量空间维度EMBEDDING_DIM = 200# 验证集比例VALIDATION_SPLIT = 0.16# 测试集比例TEST_SPL
1. 改进一:Embedding层;2. 改进二:Negative Sampling(负采样):多分类到二分类的实现、负采样、采样方法、负采样的实现;3. 改进版word2vec的学习:CBOW模型的实现、CBOW模型的学习代码、CBOW模型的评价;4. word2vec相关的其他话题:应用例、单词向量的评价方法......
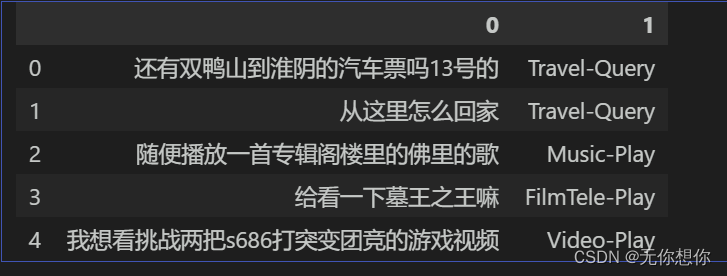
device(type='cuda')010还有双鸭山到淮阴的汽车票吗13号的Travel-Query1从这里怎么回家Travel-Query2随便播放一首专辑阁楼里的佛里的歌Music-Play3给看一下墓王之王嘛FilmTele-Play4我想看挑战两把s686打突变团竞的
本文介绍自然语言处理(NLP)的概念及其面临的问题,进而介绍词向量和其构建方法(包括基于共现矩阵降维和Word2Vec)。
运行下面的代码时,发生了pandas与numpy的版本冲突问题,在网上查了不少资料,看pandas的哪个版本与numpy的哪个版本是相对应的。问题还是无法解决,最后是另外建立一个新的虚拟环境,安装numpy、pandas,运行下面的代码就没有再出现pandas与numpy的版本冲突问题了。之所以没有用新的虚拟环境运行代码,是因为其他模块,如torch、torchtext、portalocker、n
四、如何表示一个词语的意思4.1.NLP概念术语 这里我将引入几个概念术语,便于大家理解及阅读NLP相关文章。语言模型(language model,LM),简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率。标准定义:对于语言序列w1,w2,...,wnw_1,w_2,...,w_nw1,w2,...,wn语言模型就是计算该序列的概率,即:P...
基于word2vec+lstm+attention的英文文本分类 完整代码+数据可直接运行
¶在正式介绍之前,我们先来科普一下Word2Vec,Word2vec是2013年被Mikolov提出来的词向量训练算法,在论文连续词袋模型CBOW和Skip-gram,如图4所示。图4 CBOW和Skip-gram的对比图4中使用了这句话作为例子:Pineapples are spiked and yellow,在这句话中假设中心词是spiked,这个单词的上下文是其他单词:Pineapples
以上是文本识别基本代码。
使用Word2Vec进行文本识别
什么是Word2Vec?Word2Vec是从巨大量文本中以无监督学习(从无标注数据中学习预测模型)的方式,被大量广泛的用于自然语言处理的算法技术。Word2Vec本质是通过用词向量的方式来表征词的语义信息来学习文本,通过创立一个嵌入空间使得语义上相似的单词在该空间内距离也相近。而Embedding其实就是映射空间,将文本中的词从原先所属的空间内映射到新的多维空间中,就是把原先的词所在的空间嵌入到新
1. 训练模型读取训练数据并使用jieba分词,可以准备自己想要训练的语料,import osimport jieba# 读取训练数据pos_file_list = os.listdir('data/pos')neg_file_list = os.listdir('data/neg')pos_file_list = [f'data/pos/{x}' for x in pos_file_list]n
【代码】使用Gensim训练Word2vec模型。
python实现word2vec,测试模型相似度
Word2Vec之Skip-Gram模型(原理)
从经典NNLM出发,从其局限处一步步讨论到Word2Vec;主要介绍了Word2Vec中4种实现方式,计算梯度,理解流程
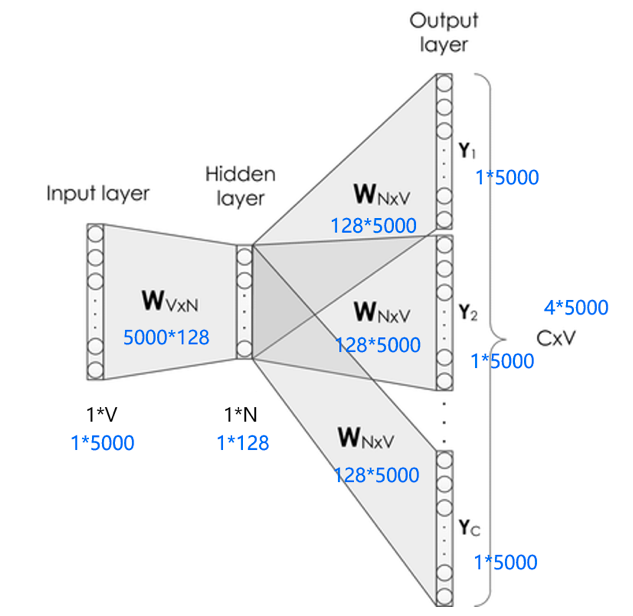
Word2Vec是word to vector的简称,字面上理解就是把文字向量化,也就是词嵌入 的一种方式。它的核心就是建立一个简单的神经网络实现词嵌入。其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括 CBOW和Skip-gram模型。
【代码】NLP 使用Word2vec实现文本分类。
id=16705本篇实验报告所记录的内容仅为写报告时(2021/04/23)的情况,可能与实际实验时(2021/04/18)结果有出入。(详细记录实验过程中发生的故障和问题,进行故障分析,说明故障排除的过程及方法。根据具体实验,记录、整理相应的数据表格、绘制曲线、波形等)安装并导入工具包:本实验主要使用到的工具包有 gensim 包,jieba 包,numpy 包和 r e 包等。基于 word2
✍🏻作者简介:机器学习,深度学习,卷积神经网络处理,图像处理🚀B站项目实战:https://space.bilibili.com/364224477😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+🤵♂代码获取:@个人主页目录一、实验背景二、相关算法2.1Word2vec2.2支持向量机2.3随机森林三、实验数据3.1 数据说明3.2评价标准四、实验步骤五、实验
word2vec模型训练
词法数据库(上一篇提到)- 问题• 手动构建‣ 昂贵的‣ 人工标注可能存在偏差和噪声• 语言是动态的‣ 生词:俚语、术语等。‣ 新感官• Internet 为我们提供了大量文本。 我们可以用它来获得词义吗?...
人工智能(Artificial Intelligence, AI)指通过计算机系统模拟人类智能的技术,涵盖学习、推理、感知、决策等能力。其核心目标是构建能够执行复杂任务的系统,包括自然语言处理、图像识别、自动驾驶等。由于您尚未提供具体的编程语言和代码要求,以下是一个通用的示例模板,展示如何根据需求生成代码。
将文本转化为向量try:continuereturn vec# 这段代码定义了一个函数 average_vec(text),它接受一个包含多个词的列表 text 作为输入,并返回这些词对应词向量的平均值。该函数# 首先初始化一个形状为 (1, 100) 的全零 numpy 数组来表示平均向量# 然后遍历 text 中的每个词,并尝试从 Word2Vec 模型 w2v 中使用 wv 属性获取其对应的
3万文本,trainvaltest622.
1.背景介绍自然语言处理(NLP)是计算机科学与人工智能的一个分支,研究如何让计算机理解、生成和翻译人类语言。情感分析是自然语言处理的一个重要子领域,旨在从文本中自动识别情感倾向,例如判断文本是否为积极、消极或中性。情感分析有广泛的应用,如社交媒体监控、客户反馈分析、品牌声誉评估等。在本文中,我们将从Bag-of-Words(BoW)模型到Word2Vec这两种主要方法,深入探讨情感分析的...
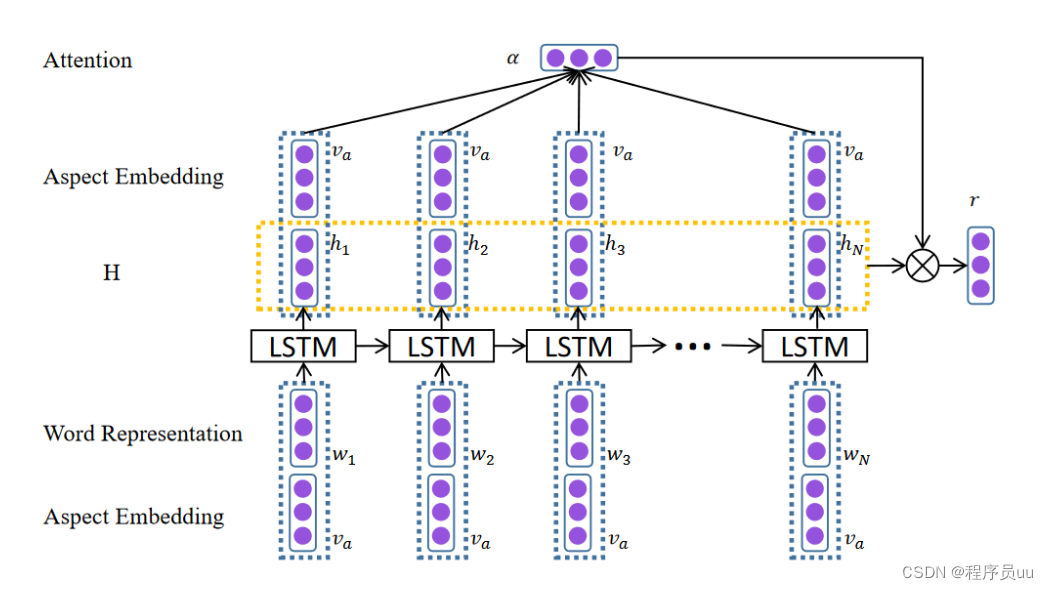
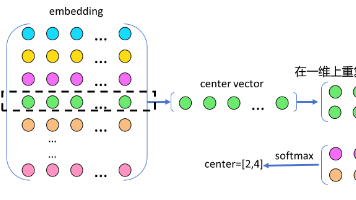
Word2Vec模型解析:CBOW与Skip-gram是两种高效的词向量训练方法,分别通过上下文预测目标词和目标词预测上下文来实现词嵌入学习。CBOW使用平均池化处理上下文信息,适合高频词和完形填空任务;Skip-gram采用双嵌入层和负采样技术,更擅长处理低频词。两者都基于分布式假设,将语义相似的词映射到相近的向量空间位置。代码实现展示了两种模型的结构差异和训练方法,包括完形填空功能示例。实验结
np.save("data/NYT_CoType/word2vec.vectors.npy", word_vectors.vectors)
word2vec
——word2vec
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net




 魔乐社区
魔乐社区


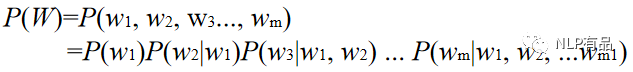

 北京朝阳AI社区
北京朝阳AI社区

 讯飞AI开发者社区
讯飞AI开发者社区
































 深开鸿 技术专区
深开鸿 技术专区
 2048 AI社区
2048 AI社区



 天启AI社区
天启AI社区


