- @qq_60245590
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Dify 项目结构近期有变化导致 requirements.txt被替代为~/dify/api 目录下 pyproject.toml 文件,这说明 Dify 后端现在采用了新的 Python 包管理方式(PEP 517/518 标准),通常用 pip 或 poetry、uv、pipx 等工具来安装依赖。如果 api 目录下没有 .env.example,你可以手动创建 .env 文件,内容参考前述
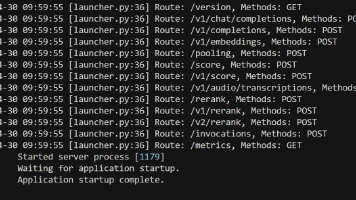
【代码】langchain Agent——RAG。
Xshell安装Ubuntu (Xshell连接前,确保已安装ssh)下一步记得 勾选 记住用户名 记住密码。ctr + C 退出ping命令。选择适合自己电脑大小的分辨率。vim按安装同上述步骤。执行 ifconfig。安装 ssh vim。
分析用户“1000113200000151566”常去的加油站点和通常的加油时间;数据集介绍:该表记录了用户在11月和12月一天24小时内的加油信息,包括:持卡人标识(cardholder)、卡号(cardno)、加油站网点号(nodeno)、加油时间(opetime)、加油升数(liter)、金额(amount)统计17:30~18:30期间加油的人数和平均加油量,以及该时间段的加油总量在一天中

2.torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;1.torchvision.datasets: 一些加载数据的函数及常用的数据集接口;4.torchvision.utils: 其他的一些有用的方法。

3. 使用 `image_dataset_from_directory` 函数加载数据集,并设置了一些参数,如 `validation_split`(指定验证集比例)、`subset`(选择训练集或验证集)和 `seed`(随机数种子),以及图像的大小。2. 定义了图像的批处理大小 `batch_size`,以及图像的高度 `img_height` 和宽度 `img_width`。`val_los

Dify 项目结构近期有变化导致 requirements.txt被替代为~/dify/api 目录下 pyproject.toml 文件,这说明 Dify 后端现在采用了新的 Python 包管理方式(PEP 517/518 标准),通常用 pip 或 poetry、uv、pipx 等工具来安装依赖。如果 api 目录下没有 .env.example,你可以手动创建 .env 文件,内容参考前述
下面是一个完整的指南,介绍如何在 VSCode 中使用 Continue 插件配合 vLLM 和 QWenCoder 来部署自动写代码的脚本。
scripts/vllm_infer.py 是 LLaMA-Factory 团队用于批量推理(inference)的脚本,基于 vLLM 引擎,支持高效的并行推理。它可以对一个数据集批量生成模型输出,并保存为 JSONL 文件,适合大规模评测和自动化测试。
GELU(x) = xΦ(x) ≈ 0.5x(1 + tanh[√(2/π)(x + 0.044715x³)])# 近似计算。timeit.timeit(lambda: nn.ReLU()(x), number=100)# 约0.12秒。timeit.timeit(lambda: nn.GELU()(x), number=100)# 约0.18秒。self.activation = nn.ReLU