




- @brownxd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Augment Code入门教程摘要Augment Code是一款基于AI的智能编程助手,提供代码生成、重构和补全功能。它支持VSCode和JetBrains IDE插件安装,提供两种工作模式:Agent模式:自动化执行代码生成、优化和测试,适合大型项目Chat模式:对话式交互解决问题,适合快速开发教程演示了如何使用Agent模式自动创建Spring Boot项目,包括:读取本地文件理解项目现状制
Agno 是一个 Python 框架,用于构建具有共享内存、知识和推理能力的多智能体系统。
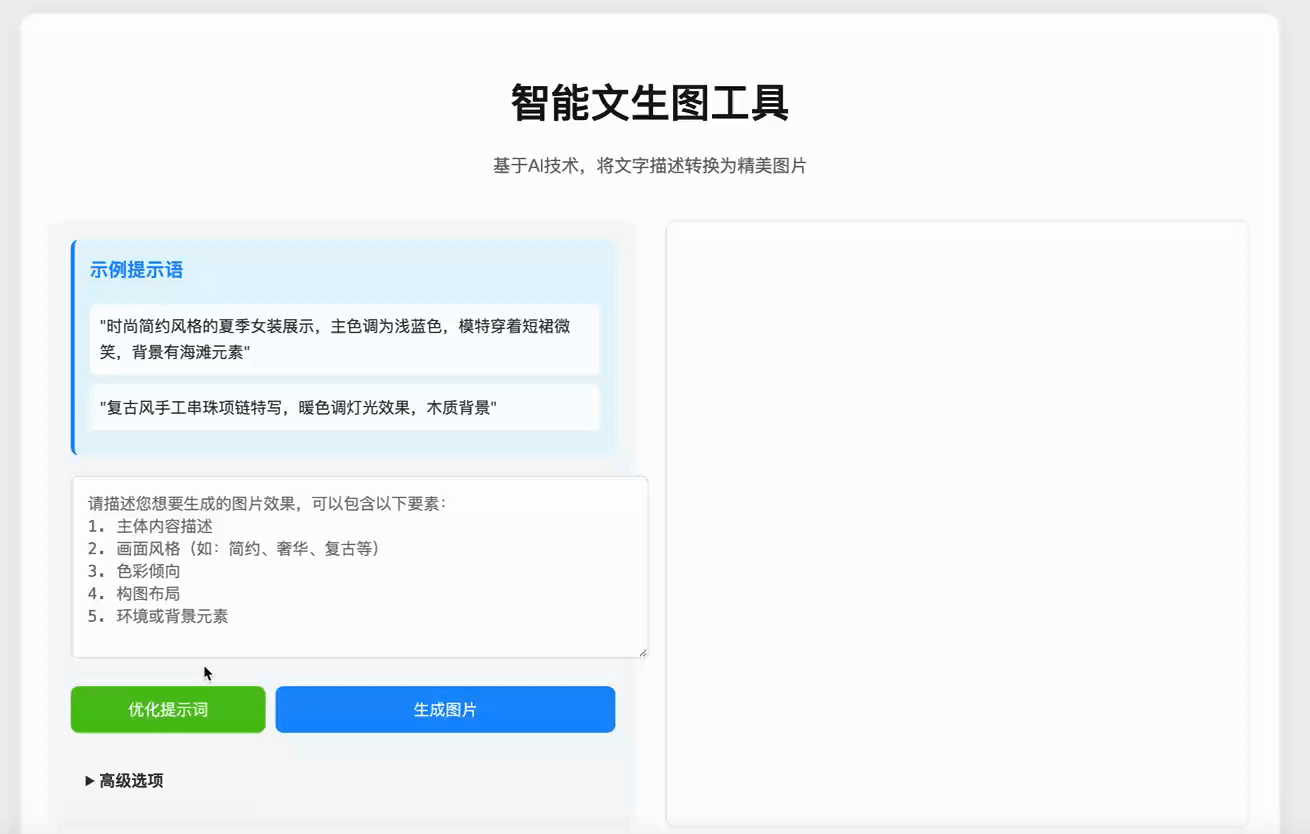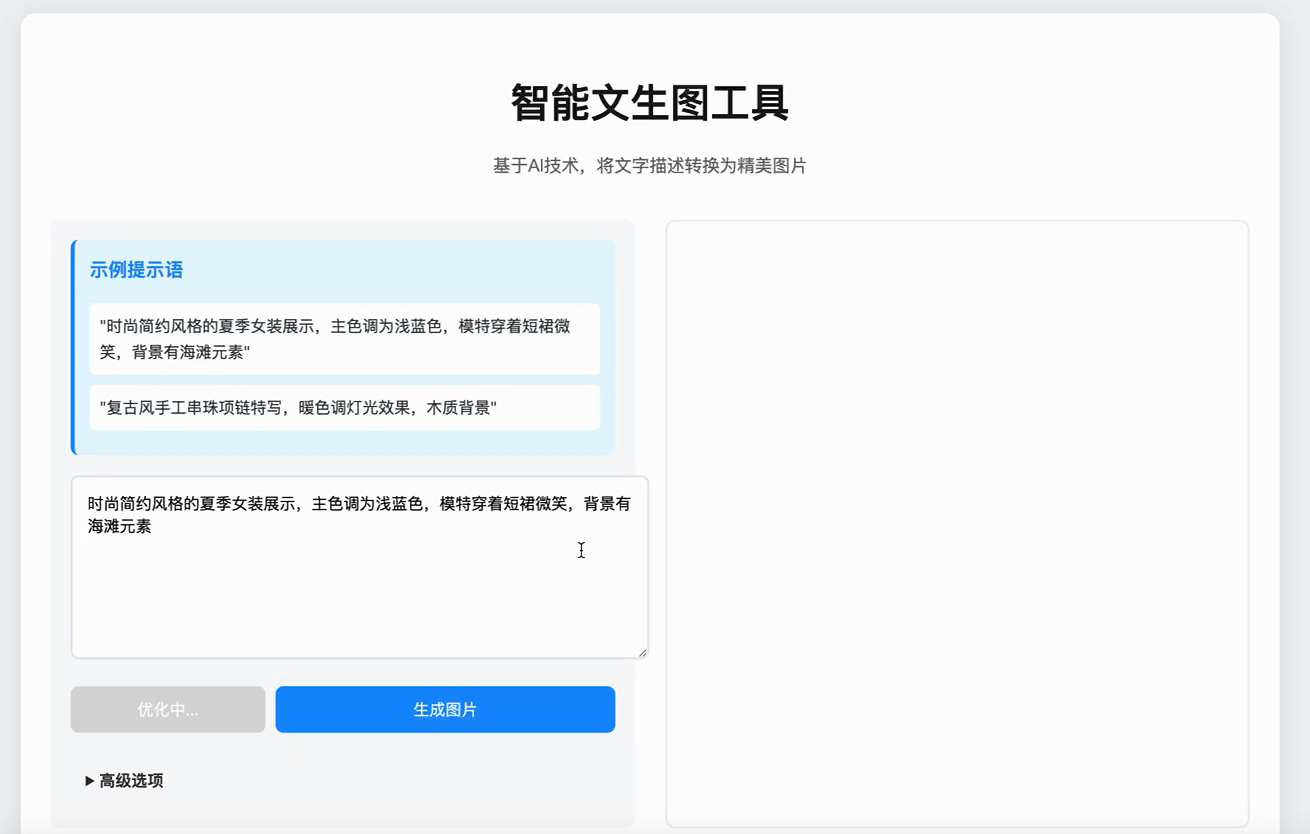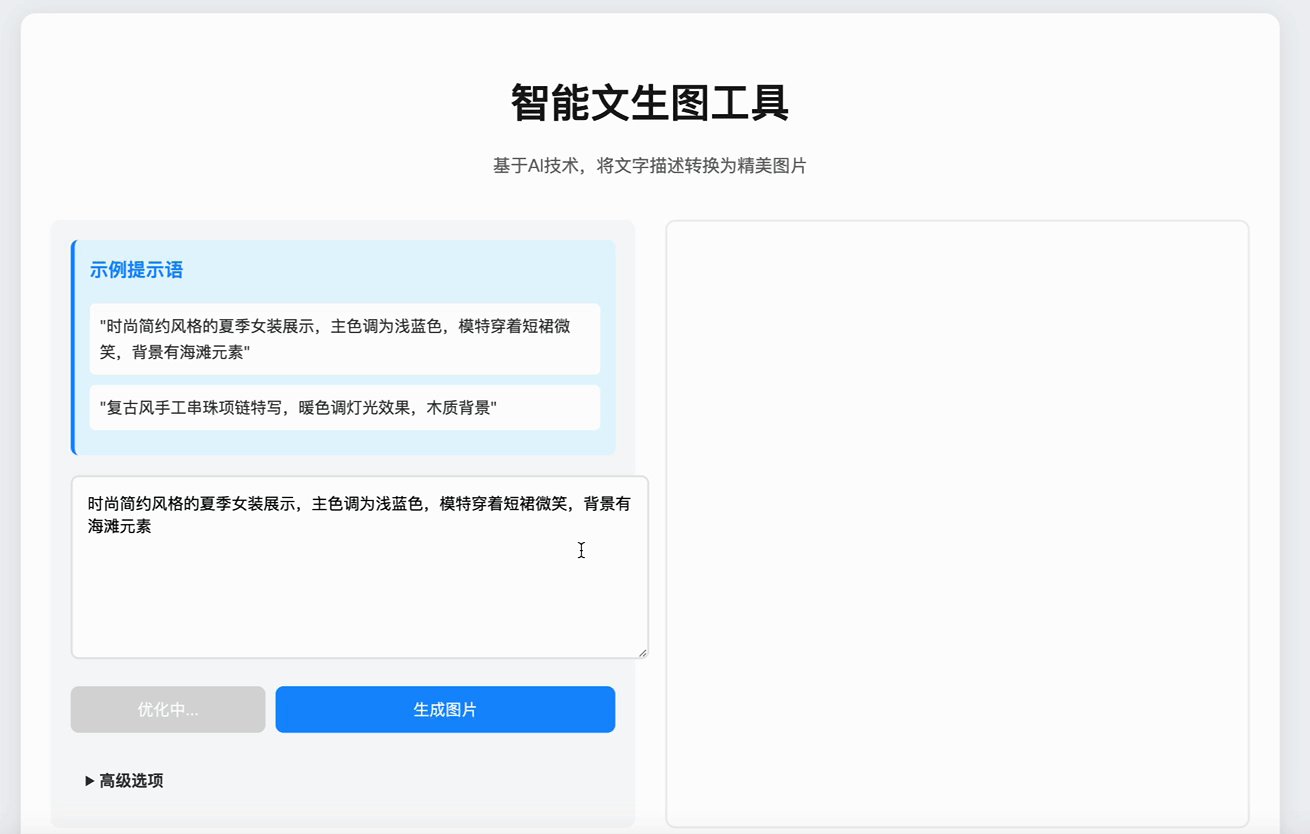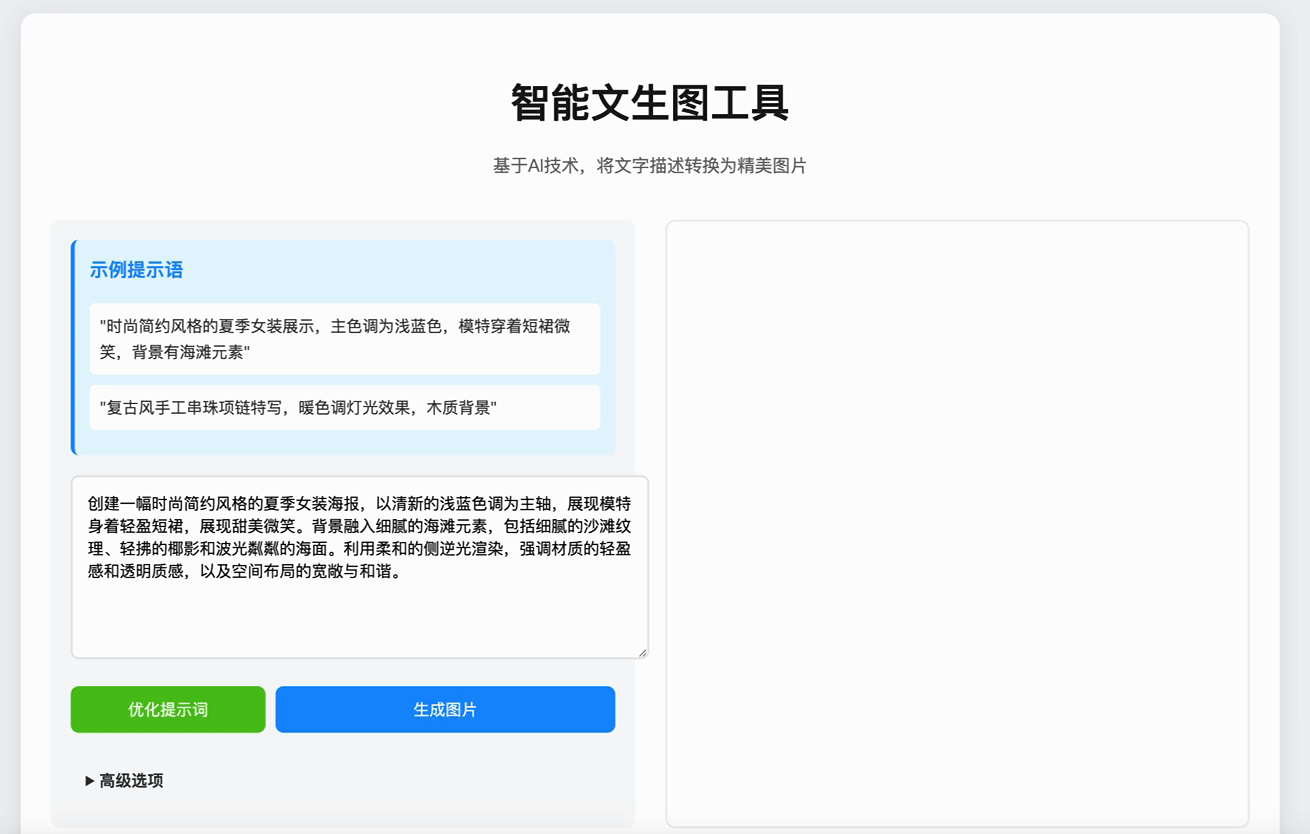
在上一小节中,我们学习了 Spring AI 中聊天客户端的使用方法,当然 AI 大模型的能力远远不至于回答你的问题,包括文生图、音频转文字、文字转音频等等功能在后面的章节中都会慢慢学习到。那么这一小节,我们将学习 Spring AI 中非常强大的功能:文生图,通过这种技术完成一个新的案例:电商广告图片生成器。我们先来看下最终的效果以及本章实现的系统具备的功能:一、提示词优化 : 提示词是文生图的
技术点解决的问题直观理解Query/KV RMSNorm注意力分数可能过大,导致训练不稳定先把参与匹配的向量“归一归”,避免分数失控Partial RoPE长上下文位置编码成本和稳定性问题只在部分维度上放位置信息,减少干扰Attention Sink有些 head 当前不需要强行关注任何历史块给注意力一个“空挡”,不相关时可以少看或不看Grouped Output Projection多 head

Mermaid 在线图表导出器是基于 Next.js 和 React 构建的 Web 工具,支持创建和导出 Mermaid 图表。核心功能包括代码编辑器、实时预览、多种主题切换及 SVG 导出,支持流程图、时序图等多种图表类型。采用 TypeScript 确保代码质量,Tailwind CSS 实现响应式设计,并部署在 Vercel 平台。该项目既可作为现代前端开发的学习案例,也能满足日常图表制作
Lazygit是一款基于Go开发的GitGit终端用户界面(TUI),旨在简化Git操作。它提供可视化界面管理Git仓库,支持文件暂存、提交、分支管理等基础功能,并包含交互式变基、Cherry-pick等高级操作。Lazygit采用分层架构设计,包含用户界面层、控制器层、命令层等模块,通过Gocui框架实现终端交互。支持跨平台(Linux/macOS/ keywordWindows),可通过Hom
PyTorch深度学习房价预测项目摘要 本项目基于PyTorch框架构建了一个多层感知机(MLP)模型,用于预测加州房价。项目从数据预处理、特征工程到模型训练和优化提供了完整解决方案。数据集包含47,439个训练样本和31,626个测试样本,涵盖41个房屋特征。 核心亮点: 采用5层神经网络架构(33→256→128→64→32→1),包含批标准化和Dropout层 实现特征筛选、缺失值处理、异常
《nano-agentscope:一个极简AI Agent框架的实现解析》摘要 本文介绍了一个极简版AI Agent框架nano-agentscope的设计与实现。该框架将Agent拆解为LLM+状态+工具+循环控制的核心要素,通过5个可替换模块(Msg、Memory、Formatter、Model、Toolkit)构建ReAct循环执行器。其特色在于:1)采用内部统一消息协议隔离SDK差异;2)
本文详细解析了MiniMind框架的监督微调(SFT)全流程,主要内容包括: 整体流程概述:从初始化到模型评估的完整训练流程,包括参数解析、模型加载、数据准备、训练循环等关键步骤。 核心技术实现: 对话模板处理:将原始对话转换为ChatML标准格式 损失掩码机制:仅对助手回复部分计算损失 预训练模型加载:支持标准模型和MoE架构切换 专用损失计算:应用损失掩码并保持MoE辅助损失 数据格式规范:采
简单来说,深度学习(Deep Learning)就是更复杂的神经网络(Neural Network)。那么,什么是神经网络呢?我们通过一个简单的房价预测例子来理解神经网络的基本概念。