




- @purple_love
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。如下图:在CNN的训练过程总,由于每一层的参数都是不断更新的,会导致下一次输入分布发生变化,这样就需要在训练过程中花费时间去设计参数。在后续提出的BN算法中,由于每一层都做了归一化处理,使得每一层的分布相对稳定,而且实验证明该算法加速了模型的收敛过程,所以被广泛应用到较深的模型中。🔥计算机视觉、图像处理、

内容识别填充(译注: Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。

记录yolov5从环境搭建到测试全过程。
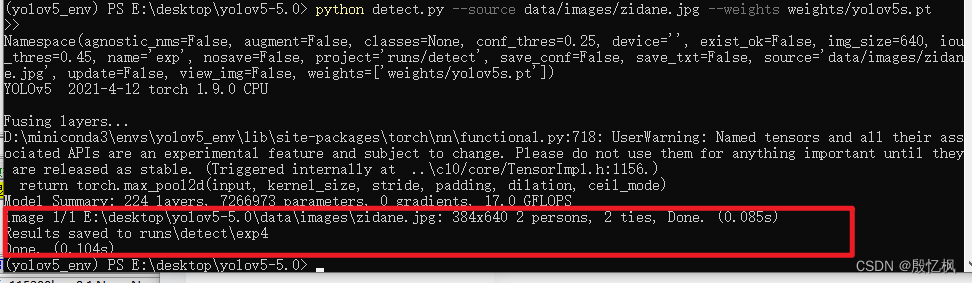
1.路沿检测步骤图39 基于Hough变换的直线(路沿)检测步骤2.路沿检测问题与解决2.1 图像处理方式的选择本实验最初尝试使用实验一的均值与中值滤波对图像进行预处理,效果不佳。在后续选择与Canny算子相适配的高斯滤波,在Hough变换前加入对比度增强,解决了此问题。故**在实际问题中应该根据算法与数据选择相应的图像处理方式**。2.2 参数设置问题无论是Canny算子的高低阈值,还是Houg

python用户画像数据分析系统

🔥计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,远程协助,代码定制,私聊会回复!

本文不会介绍具体的去水印算法实现流程,仅介绍大体的思路,供学习之用。去水印是为了得到不带水印的图片,图片的大小并不会改变,也就是说需要一个算法,输入是带水印的图片,输出是不带水印的图片,输入和输出的图片分辨率相同。很容易想到计算机视觉的一个类似的任务-语义分割。语义分割算法可以端到端的对图片每个像素点进行分类,它的输出是各个类别的概率图,但是去水印要求输出的是图片,所以我们可以采用语义分割模型,并

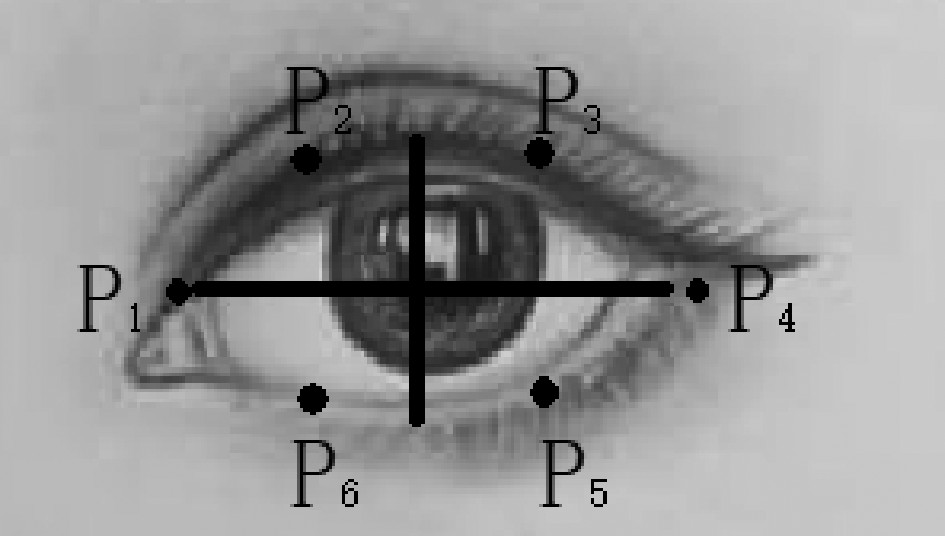
为了有效监测驾驶员是否疲劳驾驶、避免交通事故的发⽣,本项目利⽤⼈脸特征点进⾏实时疲劳驾驶检测的新⽅法。对驾驶员驾驶时的⾯部图像进⾏实时监控,⾸先检测⼈脸,并利⽤ERT算法定位⼈脸特征点;然后根据⼈脸眼睛区域的特征点坐标信息计算眼睛纵横⽐EAR来描述眼睛张开程度,根据合适的EAR阈值可判断睁眼或闭眼状态;最后基于EAR实测值和EAR阈值对监控视频计算闭眼时间⽐例(PERCLOS)值度量驾驶员主观疲劳
深度学习作为机器学习领域内新兴并且蓬勃发展的一门学科, 它不仅改变着传统的机器学习方法, 也影响着我们对人类感知的理解, 已经在图像识别和语音识别等领域取得广泛的应用。 因此, 本文在深入研究深度学习理论的基础上, 将深度学习应用到水果图像识别中, 以此来提高了水果图像的识别性能。

基于深度学习实现语义分割算法系统
