




- @flying_1314
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出HyFormer,一种统一混合Transformer架构,用于工业推荐系统中的长序列建模和异构特征交互。HyFormer通过查询解码和查询提升两个核心模块交替优化,实现序列与非序列特征的深度双向交互。实验表明,HyFormer在十亿级工业数据集上优于传统两阶段模型,AUC提升0.17%,计算效率更高,并在抖音搜索平台在线A/B测试中显著提升用户观看时长1.11%,降低查询修改率0.236%
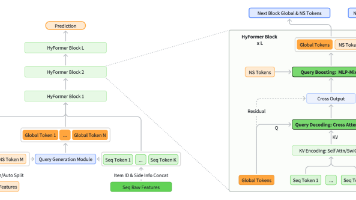
本文系统介绍了生成式推荐系统的技术全景与发展路线。首先概述了从传统判别式推荐向生成式推荐的范式变革,指出其核心优势在于端到端统一、语义理解增强和灵活泛化能力。随后详细梳理了技术演进的三个阶段(生成式协同过滤、LLM驱动、工业级框架)和七大核心技术分支,并提供了按学习路线分类的经典论文清单(包括基础序列模型、语义ID、工业框架等)。文章还设计了阶梯式学习路径(从基础到前沿约14周),最后展望了202
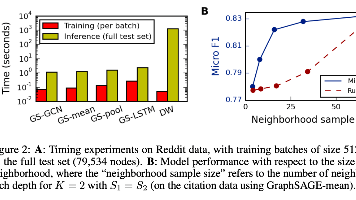
本文介绍了GraphSAGE在图节点分类任务上的实验研究。通过在引文数据、Reddit帖子和蛋白质相互作用三个数据集上的测试,结果表明GraphSAGE显著优于随机分类器、逻辑回归和DeepWalk等基线方法。实验比较了四种聚合函数变体,发现LSTM和池化聚合器表现最佳,其中池化聚合器在效率上更具优势。理论分析表明GraphSAGE能有效学习局部图结构,仅需有限次迭代即可逼近目标精度。该框架无需任
本文系统研究了图神经网络(GNN)及其门控变体GG-NN/GGS-NN的理论基础与应用前景。通过对比传统逻辑推理方法,揭示了GNN通过权重学习隐式掌握背景知识的机制。实验表明GGS-NN在图结构任务中展现出优越性能,但也存在长程依赖建模、非结构化输入处理等局限。理论分析部分证明了线性/非线性条件下信息传播的收缩特性,解释了GNN在长距离依赖中的固有约束。与RNN/LSTM的对比实验突显了GNN在非

本文介绍了图注意力网络(GAT)在直推式和归纳式学习任务中的评估结果。在三个标准引文网络数据集(Cora、Citeseer、Pubmed)和蛋白质相互作用(PPI)数据集上的实验表明,GAT模型在所有任务中均达到或超越当前最优性能。通过采用注意力机制,GAT能够为邻居节点分配差异化权重,在Cora和Citeseer上比GCN提升1.5-1.6%,在PPI数据集上比GraphSAGE提升20.5%。

本文提出消息传递神经网络(MPNN)框架,统一了多种图结构数据学习模型,并将其应用于分子性质预测。MPNN通过消息传递和顶点更新两阶段处理图数据,保持图同构不变性。在QM9数据集13个量子化学性质预测任务中,11个达到DFT计算精度,5个仅基于拓扑结构即实现化学精度。研究展示了MPNN在分子建模中的潜力,为药物发现和材料科学提供了有效工具。未来工作将探索更大分子规模和高精度数据集的适用性。
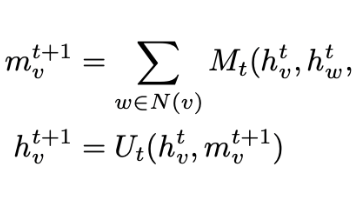
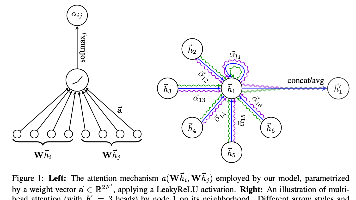
本文介绍了图注意力网络(GAT)的核心架构及其技术优势。GAT通过引入注意力机制,在计算节点特征时动态分配不同权重,解决了传统图神经网络的一些局限性。文章详细阐述了单图注意力层的实现,包括输入特征转换、注意力系数计算和多头注意力机制。GAT具有计算高效、可并行化、能处理有向图等优点,其时间复杂度与GCN相当。相比现有方法,GAT能隐式分配节点重要性,不依赖全局结构信息,适用于归纳学习任务。文章还探
本文提出了一种基于小批量随机梯度下降的GraphSAGE图神经网络算法,重点阐述了其小批量前向传播机制和邻域采样策略。算法通过分层采样和聚合实现高效计算,支持节点分类等任务。实验部分详细说明了PPI、Reddit和WoS数据集的构建方法,以及超参数调优策略。理论分析证明了池化聚合器在特定条件下能够学习节点聚类系数,并讨论了嵌入方法的对齐问题和正交不变性特性。实验结果表明,该方法在不同数据集上表现良

GraphSAGE是一种基于图神经网络的归纳式表示学习方法,其核心在于通过采样和聚合邻居特征实现层次化表征学习。算法采用K层迭代结构,每层节点聚合其邻域信息并更新表示。该方法支持均值、LSTM和池化三种聚合器架构,具有对称性和可训练性。参数学习通过随机梯度下降优化基于图结构的损失函数,使相邻节点表示相似。GraphSAGE与Weisfeiler-Lehman同构测试存在理论关联,通过固定大小邻居采

《图注意力网络(GAT)技术解析》摘要: GAT提出了一种基于自注意力机制的新型图神经网络架构,通过掩码注意力层突破传统图卷积方法的局限。该模型使节点能自适应关注邻居特征,动态分配差异化权重,无需复杂矩阵运算或完整图结构信息。采用多头注意力机制替代传统卷积操作,显著降低计算复杂度,支持端到端学习节点关系。实验表明,GAT在Cora等四个基准数据集上均达到SOTA水平,尤其在蛋白质相互作用数据集中展