- @weixin_43327597
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
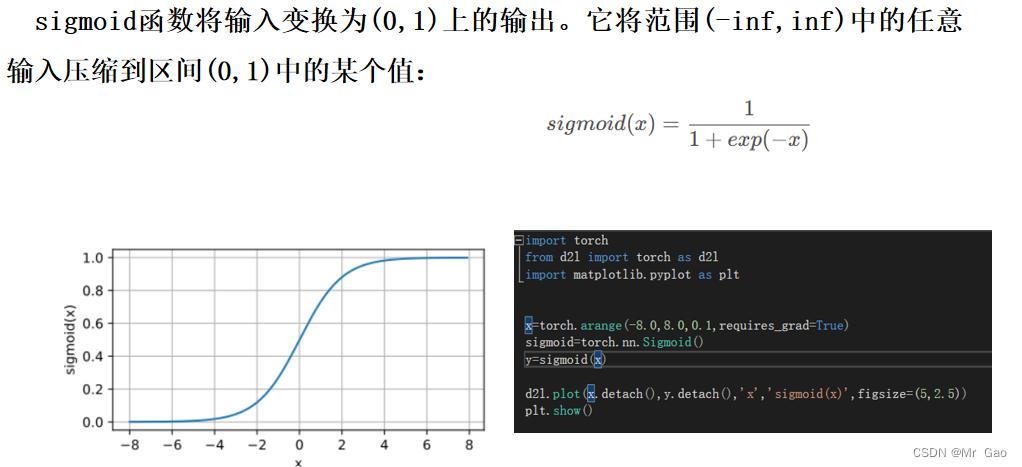
万能近似定理: ⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。我们可以通过两个 sigmoid 函数 (y = sigmoid(w⊤x + b)) ⽣成⼀个 tower,如图:使用PyTorch库来执行数值计算,首先通过 torch.
当然,这种方法比较麻烦,每次我们运行exe文件都需要那三个配置文件,这显然是麻烦的,所以我们可以把那三个文件放入我们的系统变量检索环境中,这样,运行exe文件的时候我们就可以不用在配置缓解了,可以直接运行,注:这一步新手对这个操作可能不太懂,谨慎操作。对于很多小伙伴应该都是学习c++/c,当然很多人其实只是一直在自己的集成开发环境中不断编写代码然后运行并解决相应的任务,但是其实这样自己的代码可移植

centos 7 下 安装 eclipse之前博主已经写过了两篇博客,分别是配置,jdk,hadoop,和hdfs 文件系统上传文件,下面,我们就是配置eclipse 集成开发环境,进行mapreduce 程序的编写配置java jdk 这个博主之前已经写过可以看这片博客https://blog.csdn.net/weixin_43327597/article/details/108834870下
神经网络的万能近似定理万能近似定理: ⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。我们可以通过两个 sigmoid 函数 (y = sigmoid(w⊤x + b)) ⽣成⼀个 tower,如图:我们构造多个这样的 tower 近似
特征选择的三种方法• 包装方法(wrapper method)是“围绕”着特定的预测模型建立的。每个特征子集用来训练一个模型。训练得到的模型的泛化性能可以为该子集评分。包装方法是计算密集型的,但通常为特定模型提供表现最佳的特征集。• 过滤方法(filter method)使用代理度量而不是错误率为特征子集评分。常用的度量包括互信息和相关系数。许多过滤器提供特征的排名,而不是一个明确的最佳特征子集。
模拟行走机器人-c语言机器人在一个无限大小的 XY 网格平面上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令 commands :-2 :向左转 90 度-1 :向右转 90 度1 <= x <= 9 :向前移动 x 个单位长度在网格上有一些格子被视为障碍物 obstacles 。第 i 个障碍物位于网格点obstacles[i] = (xi, yi
python pytorch实现RNN,LSTM,GRU,文本情感分类

神经网络的万能近似定理万能近似定理: ⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。我们可以通过两个 sigmoid 函数 (y = sigmoid(w⊤x + b)) ⽣成⼀个 tower,如图:我们构造多个这样的 tower 近似
【代码】python-opencv 人脸68点特征点检测。

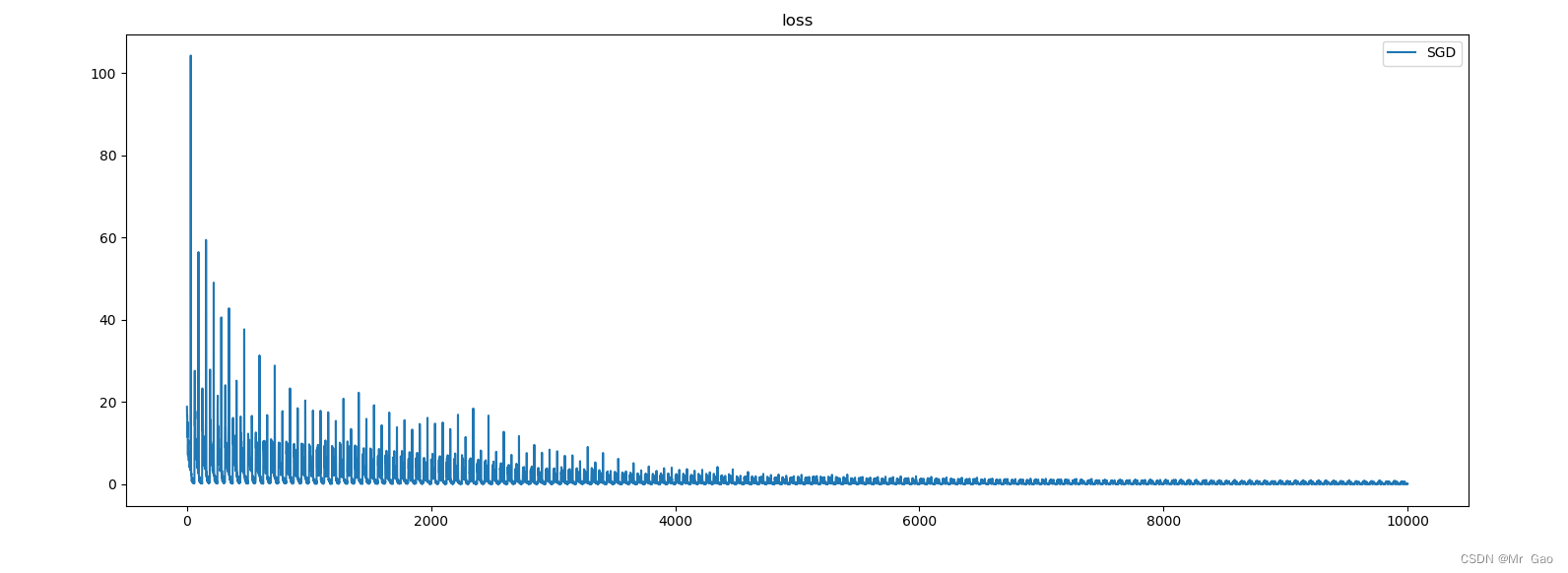
下面这个代码大家可以学习学习,这个代码难度最大的在于反向传播推导, 博主推了很久,整个过程都是纯算法去实现的,除了几个激活函数,可以学习一下下面的代码。我下面这个代码还是很严谨的,从数据集生成,损失函数,网络结构、梯度求导,优化器等等组件都实现了。