




- @linjie_830914
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对抗蒸馏框架概述:我们基于高级闭源LLM的基础上提炼一个学生LLM,该LLM具有三个角色:教师、裁判和生成器。有三个迭代阶段:模仿阶段,对于一组指令,将学生的响应与老师的响应对齐;区分阶段,识别出难指令;生成阶段,根据识别出的难指令,产生新的难指令以增加对学生模型的挑战。

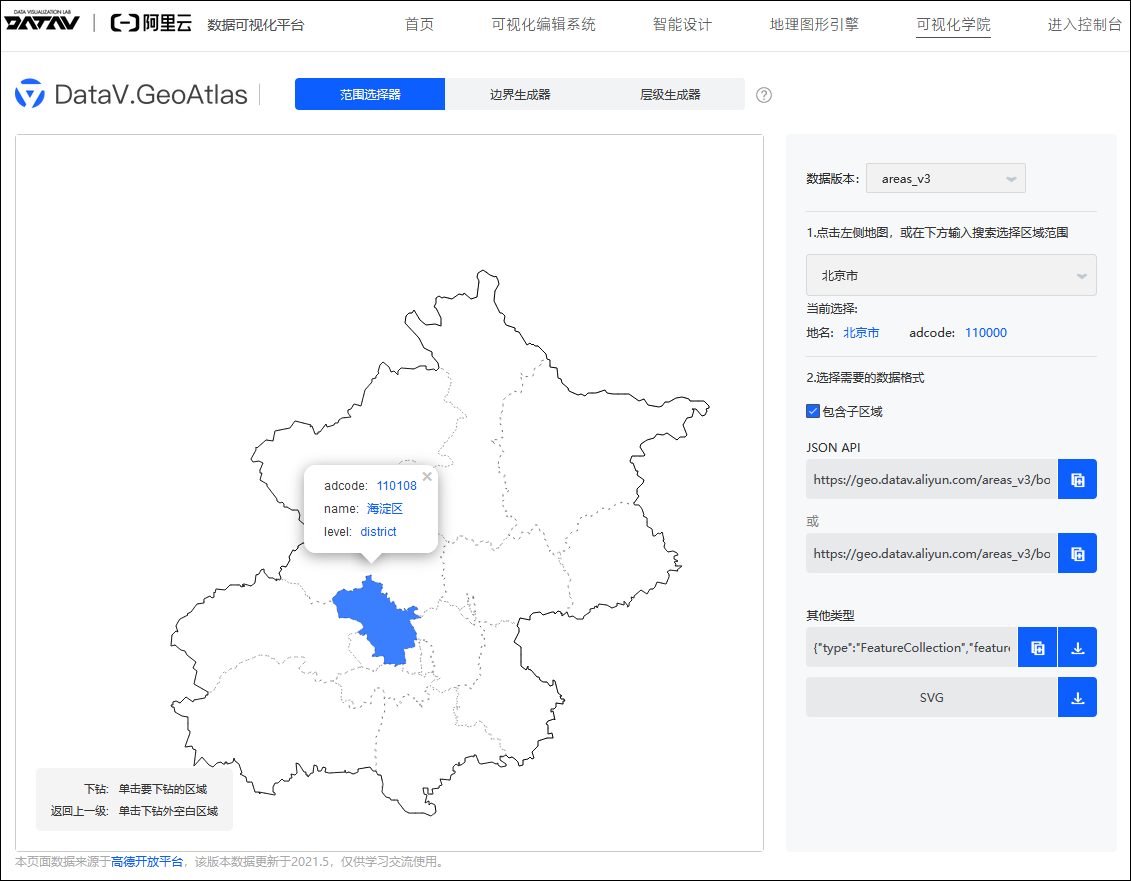
通过http://datav.aliyun.com/tools/atlas 可以下载到全国省市区县级的行政区划边界数据(GeoJSON格式)。国家地理信息公共服务平台 天地图 https://www.tianditu.gov.cn/ 【省级节点】中,部分省份提供了乡镇街道的边界数据。https://map.vanbyte.com 提供了免费的省市县3级行政边界数据(GeoJSON格式)、省市县乡4
本文介绍了OpenClaw 2026 ERP系统针对大型企业部署100+AI智能体的五步管理方法:需求盘点→架构设计→灰度试点→全量推广→持续运营。详细阐述了每阶段的执行要点,包括分层架构设计、资源调度策略、灰度验证流程和运营指标体系。该系统提供多租户隔离、工作流编排、全链路审计等核心能力,将AI智能体管理从技术问题转化为可量化评估的治理流程,帮助企业实现Agent集群的高效部署和持续优化。
文章目录第三部分、创建hadoop用户第三部分、创建hadoop用户1、创建一个名字为hadoop的普通用户[root@bigdata-senior01 ~]# useradd hadoop[root@bigdata-senior01 ~]# passwd hadoop2、 给hadoop用户sudo权限注意:如果root用户无权修改sudoers文件,先手动为root用户添加写权限。[root@
CPM全称Chinese Pretrained Model,Bee是该系列模型的第二个里程碑版本。CPM-Bee模型是基于CPM-Ant模型继续训练得到。后者是2022年5月到9月训练的大语言模型。而CPM-Bee则是从2022年10月13日开启训练,相比之前,模型在很多任务上做了优化,包括文字填空、文本生成、问答等。这是一个基于transformer架构的自回归模型,在高质量的中英文数据集上训练
本篇文章共 25027 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embedding到BERT - 二十三岁的有德本文的主题是预训练语言模型的前世今生,会大致说下 NLP 中的预训练技术是一步一步如何发展到 Bert 模型的,从中可以很自然地看到 Bert 的思路是如何逐渐形成的,Bert 的历史沿革是什么,继承了什么,创新了什么,为什么效果那么好,

用Rag技术搭建一个本地的个人助手,使用的是AnythingLLM+DeepSeek的组合。体验下来,这个只能作为或体验之类的,很难真正实现一个工程性需求。

本篇文章共 25027 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embedding到BERT - 二十三岁的有德本文的主题是预训练语言模型的前世今生,会大致说下 NLP 中的预训练技术是一步一步如何发展到 Bert 模型的,从中可以很自然地看到 Bert 的思路是如何逐渐形成的,Bert 的历史沿革是什么,继承了什么,创新了什么,为什么效果那么好,
CPM全称Chinese Pretrained Model,Bee是该系列模型的第二个里程碑版本。CPM-Bee模型是基于CPM-Ant模型继续训练得到。后者是2022年5月到9月训练的大语言模型。而CPM-Bee则是从2022年10月13日开启训练,相比之前,模型在很多任务上做了优化,包括文字填空、文本生成、问答等。这是一个基于transformer架构的自回归模型,在高质量的中英文数据集上训练
通过上述的讲解,对图像预训练做个总结(可参照上图):对于一个具有少量数据的任务 A,首先通过一个现有的大量数据搭建一个 CNN 模型 A,由于 CNN的浅层学到的特征通用性特别强,因此在搭建一个 CNN 模型 B,其中模型 B 的浅层参数使用模型 A 的浅层参数,模型 B 的高层参数随机初始化,然后通过冻结或微调的方式利用任务 A 的数据训练模型 B,模型 B 就是对应任务 A 的模型。这其实是
