登录社区云,与社区用户共同成长
邀请您加入社区
一、ESP32 与 STM32 的使用场景简单说一下这两类芯片的定位:ESP32 集成 Wi-Fi/蓝牙,开发快、性价比高,是智能家居、物联网项目的热门选择;STM32 则以丰富的外设、强大的实时响应和工业级稳定性著称,在工业控制、汽车电子等领域占据主流。两者侧重不同,但都能用 PicoServer.Nano 快速提供 Web 能力。二、快速开始:在 ESP32 上跑一个 Web API”), “
elk
grok、date、mutate、mutiline
自定义表达式格式:(?<自定义名称>正则表达式)
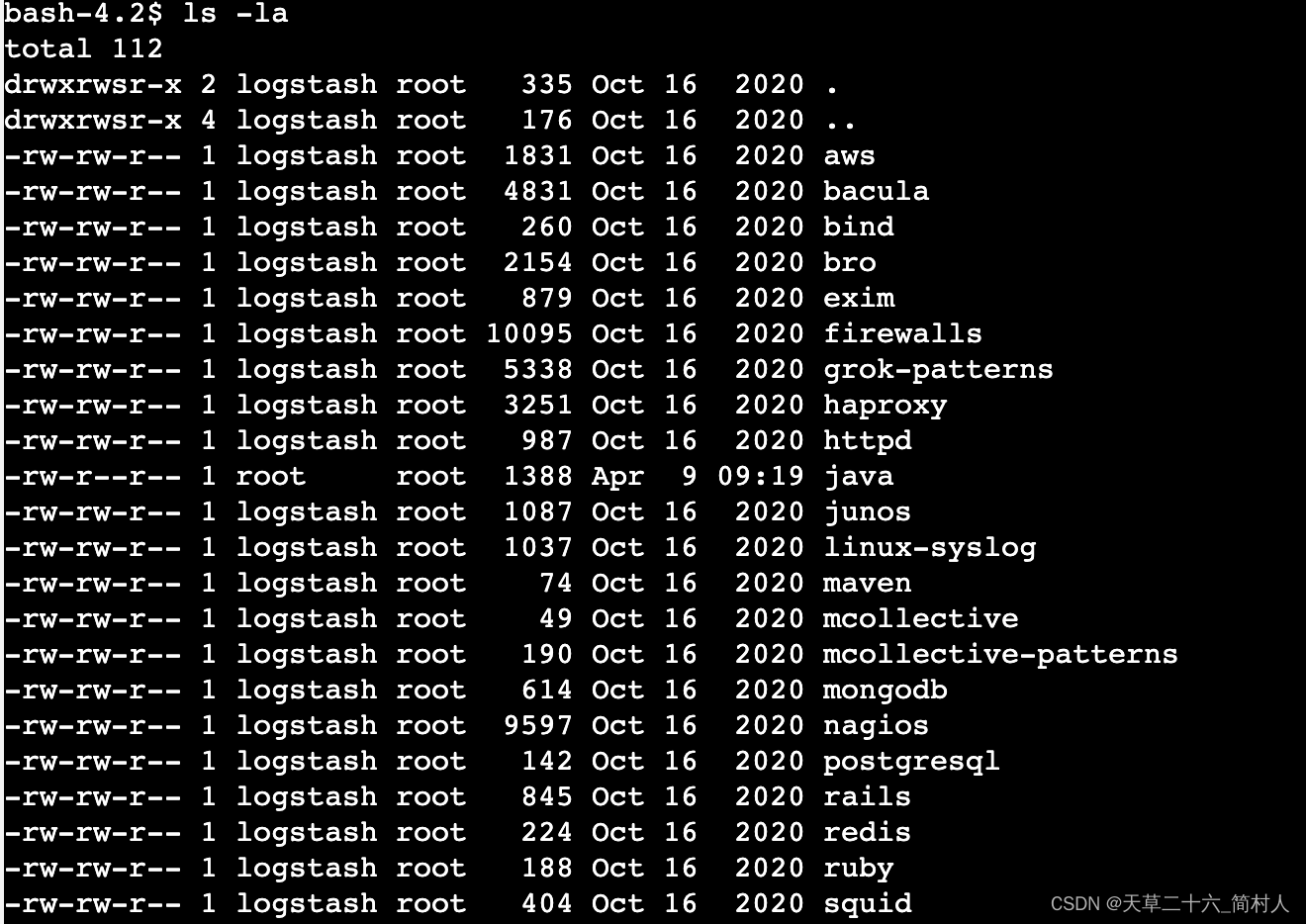
grok自带的正则表达式配置路径是:/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patternstotal 112文章开头部分提及的日期正则,大多数是配置在文件grok-patterns里。
elk笔记4--grok正则解析1 grok 切分方法2 grok 切分案例3 说明1 grok 切分方法grok切分规则可按照如下思路进行。1)找准切分标志,以切分标志作为中心向左或者向右逐个字段抽出,对于正则中的通配符需要进行转义处理,否则这类字符作为分割标志的时候容易解析出错2)也可以直接从左到右逐个字段取出2 grok 切分案例案例1内容:2016/04/27 12:22...
logstash grok 规则
语法:(?举例:捕获10或11和长度的十六进制数的queue_id可以使用表达式(?filter {grok {如果表达式匹配失败,会生成一个tags字段,字段值为 _grokparsefailure,需要重新检查上边的match配置解析是否正确。日志管理方案服务器数量较少时,rsyslog或脚本 收集、分割日志,统一汇总到专门存放日志的日志服务器保存管理查看日志可把需要的日志文件传到Window
基于观察者模式设计的分布式结构,负责存储和管理架构当中的元信息,架构当中的应用接受观察者的监控,一旦数据有变化,通知对应的zookeeper,保存变化的信息。3、统一集群管理,在整个分布式的环境中,必须实时的掌握每个节点的状态,如果状态发生变化,要及时更新。1、点对点,一对一,生产者生产消息,消费者消费消息,这个是一对一的。消息的生产者发布一个主题,其他的消费者订阅这个主题,从而实现一对多。经纪人
Kibana 是 Elastic Stack 中用于数据可视化的组件,它通过与 Elasticsearch 紧密集成,提供了强大的可视化工具,使用户可以实时地浏览、查询和分析 Elasticsearch 中的数据。在 Kibana 中,用户可以创建仪表盘、设置数据视图,并使用强大的查询功能分析日志和指标数据。📌 在本系列中,我们成功完成了在 Kubernetes 集群中部署 ELK(Elasti
springcloud集成sleuth并将日志写入到elk
1.ELK 是一套开源工具,用于日志管理、搜索和数据分析。三个核心组件:是一个分布式搜索和分析引擎,能够高效地存储和检索大量数据。它适用于结构化和非结构化数据,擅长全文搜索和数据聚合。Logstash是用于数据收集和处理的工具,能够从多种数据源(如日志文件、数据库等)获取数据,对其进行解析、过滤,并将处理后的数据发送到 Elasticsearch 或其他目标系统。Kibana是一个可视化工具,提供
Logstash 是 Elastic Stack 中的一款强大且灵活的数据收集与处理引擎,主要用于从多种来源收集数据,进行过滤、解析、转化后,转发到指定的存储系统(如 Elasticsearch 等)。它支持丰富的输入、过滤器和输出插件,能够对日志数据进行结构化处理和格式化转换。与传统的日志处理工具相比,Logstash 具备高扩展性和复杂数据处理能力,适用于构建灵活的数据采集与处理管道,广泛应用
永久生效方法:echo "* - nofile 65536" >> /etc/security/limits.conf。
本文详细介绍了ELK栈(Elasticsearch、Logstash、Kibana)在Linux环境下的安装配置过程,实现从日志收集到可视化分析的全流程。内容包括:1)环境准备(JDK11安装配置);2)三大组件安装与核心配置(Elasticsearch存储、Logstash日志收集处理、Kibana可视化);3)系统日志收集与分析验证;4)常见问题解决方案。通过分步指导,帮助新手快速搭建可用的日
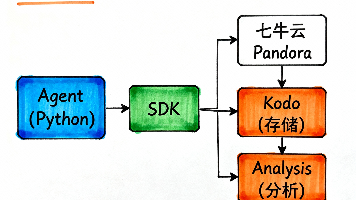
摘要: 本文探讨了在GPT-5时代如何有效监控AI Agent的思维链问题。传统ELK日志系统因上下文丢失、非结构化数据等问题已无法满足需求。作者通过七牛云Pandora构建轻量级"Agent思维黑匣子",利用其动态模式、存算分离和Trace可视化特性,结合LangChain回调中间件实时记录Agent思考过程。相比ELK,该方案显著降低了成本和查询延迟,提升了故障排查效率,为
维度说明优点应用性能高:应用只写内存/流,不涉及慢速的磁盘IO或网络IO。职责分离:开发只管打日志,运维只管收日志,互不干扰。安全:如果日志服务器挂了,不会导致你的业务应用崩溃。缺点丢失风险:如果日志生成的太快,超过了“搬运工”的处理速度,或者容器突然崩溃,缓冲区里的极少量日志可能会丢失。调试延迟:从你代码执行error到你在网页上看到它,可能会有几秒钟的延迟(Latency)。那好,既然现在知道
Aspect@Componentlogger.info("开始执行方法: {}.{}, 参数: {}",} else {logger.info("开始执行方法: {}.{}", className, methodName);try {logger.info("方法执行完成: {}.{}, 耗时: {}ms",logger.info("方法返回结果: {}", result);
Spring Boot日志管理实战摘要 日志是系统运行的DNA,85%线上故障排查耗时取决于日志质量。本文深度解析Spring Boot日志体系,涵盖: Logback核心配置:解析SLF4J门面模式,推荐使用logback-spring.xml,支持动态环境配置和异步输出优化IO性能。 日志级别艺术:严格区分TRACE/DEBUG(开发)与INFO/WARN/ERROR(生产),采用JSON格式
ELK 栈为微服务架构提供了一套完整的日志收集与分析解决方案。通过 Logstash/Filebeat 采集日志,Elasticsearch 存储与索引,Kibana 实现可视化分析,解决了微服务日志分散、难以管理的问题。该方案支持日志聚合、高效检索、可视化监控和告警配置,能够满足问题排查、系统监控等需求。关键配置包括 Filebeat 采集规则、Logstash 预处理管道和 Kibana 索引
如果把安全工作粗略拆成三段:预防、检测、响应,那么 ELK 覆盖的是后两段的“主战场”。- 预防:权限、认证、输入校验、供应链治理、配置基线- 检测:把关键行为转成结构化事件,把异常转成可追踪的信号- 响应:告警分级与升级、证据保全、处置闭环与复盘
大家好,我是 微赚淘客系统3.0 的研发者省赚客!在高并发、多服务的返利系统中,用户一次“查券+下单+返利”操作可能涉及 5 个以上微服务。若出现佣金未到账或查询超时,传统文本日志难以快速定位根因。微赚淘客系统3.0 基于构建可观测性体系,实现秒级问题定位。</</</</</</</基于 Spring Cloud Sleuth 自动注入traceId和spanId。
ELK日志系统实战指南:从零搭建自动报警平台 本文通过生动比喻和实操演示,系统介绍了ELK(Elasticsearch+Logstash+Kibana)日志解决方案的核心原理与部署方法。文章将ELK组件类比为现代化图书馆:Logstash是负责收集和解析日志的"翻译官",Elasticsearch是建立高效索引的"仓库",Kibana则是提供可视化分析的&q
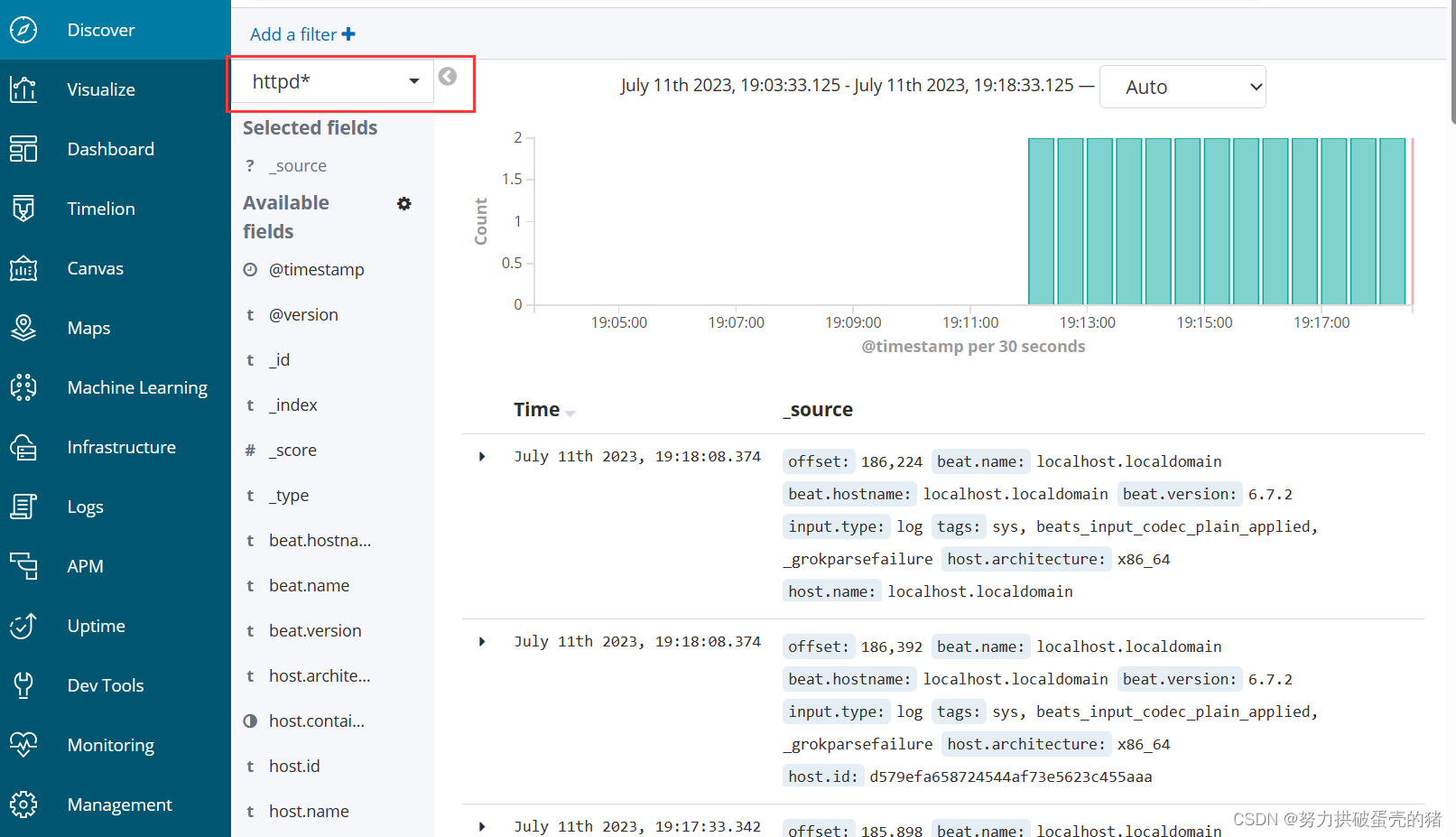
本次实验是收集nginx 日志,并存储在elasticsearch中。将elasticsearch和kibana 安装在同一主机上可以避免不必要的网络IO操作,直接本机交互。Kibana 下载地址: Past Releases of Elastic Stack Software |Elastic。根据规划,Kibana和elasticsearch安装到同一台主机(es01)查看5601端口如果被监
注意这里的hosts要写logstash主机的IP 修改 nginx块配置文件(vi /etc/filebeat/modules.d/nginx.yml)(这个文件一开始没有,vi的时候是一个空白文件)Filebeat 下载地址: Past Releases of Elastic Stack Software |Elastic。修改filebeat主配置文件 (vi /etc/filebeat/f
文章开始前我想说的Elasticsearch 7.17.10 双节点集群部署实战(基于 Rocky Linux 9.6)Elasticsearch 7.17.10 双节点集群部署(二):安装 elasticsearch-head 插件实现可视化ELK日志分析平台(三):Logstash 7.17.10 独立节点部署与基础测试(基于Rocky Linux 9.6)ELK日志分析平台(四):Kiban
手动部署核心是:下载解压→配置文件→创建 systemd 服务实现开机自启,所有组件需版本一致(8.14.0)。ES 必须用非 root 用户启动,需提前配置系统内核参数和权限;其他组件(Logstash/Kibana/Filebeat)可直接用 root 启动。核心流程不变:Filebeat 采集 Nginx 日志→Logstash 解析→ES 存储→Kibana 可视化,关键是确保 Logst
本文详细讲解了K8s日志收集的核心——EFK/ELK部署与配置,从日志收集核心原理、EFK与ELK的区别,到EFK完整部署(重点)、ELK部署(备选),再到日志过滤、Kibana日志查询与可视化、生产环境最佳实践和常见问题排错,全程实操、命令可复制,帮你彻底解决了“日志分散、无法快速排查故障”的难题,掌握了K8s应用日志的集中收集、存储、查询方法,为应用故障排查、监控告警打下了坚实基础。
ELK简要介绍
——elk
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区