




- @qq_34252622
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生产环境数据对不上了!数据库里少了一批订单状态流转记录!昨晚 11 点,正在排位的我被测试疯狂 Call 醒。这批数据涉及到资金结算,少一条都是 P0 级事故。我连夜爬起来排查,代码逻辑查了三遍,没毛病;数据库事务查了,也正常。日志在某个时间点突然截断了,没有任何报错,没有任何异常堆栈,就像应用“凭空蒸发”了一样。我把目光转向了发版记录。果然,那个时间点,运维正在进行灰度发布。我冲到运维工位(群里

摘要: Kubernetes中Java应用偶现的响应延迟问题常由Linux CFS的CPU配额机制引发。当多线程应用(如Java)在短时间内消耗完分配的CPU配额(如10线程各跑10ms即耗尽100ms配额),剩余周期内线程会被强制挂起,导致卡顿。解决方案包括移除CPU Limits、调大配额、利用CFS Burst特性或限制JVM并行度。监控应关注throttled_seconds而非仅CPU使

本文探讨了如何利用eBPF技术解决Java应用间歇性网络延迟问题。当传统监控工具无法定位P99飙升时,eBPF提供了内核级别的观测能力,能精准追踪TCP数据包处理全链路。通过分析TCP队列溢出和应用读取延迟,文章揭示了"网络抖动"假象背后往往是应用层问题(如GC停顿)。eBPF具有零侵入、低开销的优势,能打破应用与内核的观测边界,成为SRE排查复杂问题的终极武器。案例证明,掌握

你是否觉得现在的 AI 编程助手(Copilot, Cursor)虽然好用,但还是不够“智能”?它们大多只能在你写代码时补全几行,或者回答你的提问。你仍然需要自己规划架构、自己调试报错、自己切换浏览器查资料。Google 刚刚发布的可能会彻底改变这一切。这不仅仅是一个 IDE,它是一个Agent-First(智能体优先)的开发平台。在这里,你不再是孤独的“码农”,而是一个指挥 AI 特工(Agen

作为后端开发,我们习惯了类 (Class)对象 (Object)封装 (Encapsulation)和依赖注入 (DI)。满屏的this:这个this到底指的是 Window 还是实例?代码割裂:实现一个“搜索”功能,变量要写在data里,逻辑要写在methods里,监听要写在watch里。屏幕滚来滚去,逻辑支离破碎。Vue3 的 Composition API(组合式 API)简直就是后端开发者

本文提出一个面向"双碳"目标的个人碳足迹平台毕业设计方案。该选题紧扣国家战略,通过构建碳排放核算模型、积分激励体系和可视化系统,实现个人碳足迹管理。系统采用Spring Boot+Vue技术栈,核心功能包括:基于排放因子的碳核算引擎(核心算法为输入量×排放系数)、绿色积分激励机制以及ECharts数据可视化。设计强调"政治正确"与实用性的平衡,既满足学术要求


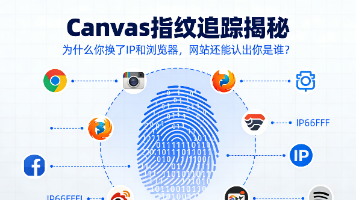
你是否遇到过这种情况:你在京东看了一双鞋,没登录账号,然后清除了浏览器 Cookies,换了 IP 地址,打开了 Chrome 的“无痕模式”。结果,当你打开另一个新闻网站时,广告栏里赫然推荐着刚才那双鞋。这是因为网站不再通过 Cookies(身份证)来识别你,而是通过Canvas 指纹(生物特征)认出了你。在反爬虫领域,这也是区分“真浏览器”和“Selenium 脚本”的致命杀招。Canvas
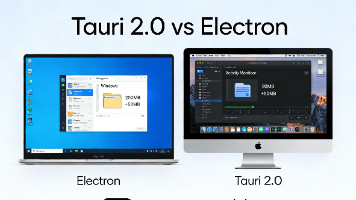
把一个完整的 Chrome 浏览器和 Node.js 打包进你的应用里。优点:前端极其舒服,API 统一,不用管浏览器兼容性。缺点体积大:Hello World 也要 60MB+(因为带着 Chrome)。内存泄露:每个窗口都是一个 Chrome 进程,内存杀手。安全性:Node.js 在渲染进程的权限过大,容易被 XSS 攻击利用。既然用户的电脑里已经有了浏览器(Windows 有 Edge/W
我们爱 Python,因为它简洁、生态丰富。我们恨 Python,因为在处理大规模循环或数学运算时,它真的太慢了。假设我们需要计算一个“超级复杂的数学序列”(例如:计算 0 到 N 所有数字平方和的累加)。在 Python 里,这只是一行代码;但在 CPU 眼里,这是数百万次的类型检查和对象创建。是时候引入Rust了。它没有 GC,编译成机器码,且通过PyO3库,可以像写普通 Python 模块一
