- @2502_93987700
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
代表后续可传入的具体类型(T为约定俗成的占位符,可替换为E(元素)、K(键)、V(值)等)判断凭证类型并执行对应逻辑,会导致代码臃肿),新增凭证类型时需修改原有逻辑,违反开闭原则。可写:可以安全地向集合中添加T类型的元素(因为T是集合类型的子类,向下转型安全,如。),会产生大量重复代码,且新增业务类型时需同步新增结果类,违反开闭原则。),会导致分页逻辑与业务类型强耦合,新增业务时需重复编写分页结构
大家可能没注意到,现在每一款与你互动的Chatbot,背后运行的都是 PyTorch。可以说,它已经成为了主流LLM研发链路中事实上的标准。Pytorch 赢了。大家可能没注意到,现在每一款与你互动的Chatbot,背后运行的都是 PyTorch。可以说,它已经成为了主流LLM研发链路中事实上的标准。首先,不管是大洋彼岸的OpenAI、Anthropic,还是国内的通义千问、智谱、月之暗面,他们推

上述的一些实例,并非绝对可行的方案,仅是针对不同场景的探讨。在实际应用中,需要结合实际数据和具体问题进行深入分析,并运用相应的工程优化技巧,以实现RAG方案的最佳效果。RAG之所以被行业看重,核心不是因为它“技术多先进”,而是因为它“落地成本低、适配性强”。在AI技术从“通用能力”走向“行业深耕”的今天,RAG更像是一把“行业适配的钥匙”——能快速打开“AI+客服”“AI+法律”“AI+金融”等各

最近,Meta的PyTorch团队与Hugging Face联手推出了一个开源项目,试图为这个难题提供标准化解决方案。AI智能体的发展正在进入一个关键阶段。随着模型能力的不断提升,如何为AI智能体创建安全、可控的运行环境,成为了整个行业必须面对的挑战。最近,Meta的PyTorch团队与Hugging Face联手推出了一个开源项目,试图为这个难题提供标准化解决方案。

FlowithOS的出现,不仅仅是一款产品,它更像是AI领域的一个重要宣言。它预示着AI竞争将从“谁的模型更聪明”转向“谁的系统能让AI更有效地做事”。一个全新的“AI操作系统”生态正在浮现,AI不再仅仅是提供答案的工具,而是能够独立工作、自主执行任务的真正“协作者”或“数字员工”。朋友们,当我们在谈论AI的时候,脑海中浮现的往往是那些能够“回答问题”、“生成内容”的强大模型。但如果我告诉你,一场

Google还添加了一个代码助手工具包——MCP服务器,它连接到Google Maps的技术文档。开发者可以利用这个连接获取关于如何使用Google Maps API和数据的答案。上个月,公司还为Gemini的命令行工具推出了扩展,让开发者能够访问Maps数据。Google Maps最近引入了一系列全新的AI功能,包括构建代理(builder agent)和MCP服务器,帮助开发者和用户利用地图数
Linux 之父 Linus Torvalds,最近迷上了做吉他效果器,而且做得一塌糊涂。但在“失败”的爱好之外,他依旧掌舵着全球最重要的开源系统。在本月早些时候,首尔Linux基金会开源峰会上,他与Verizon开源负责人Dirk Hohndel进行了第28次对谈。如果不是这次访谈,你可能不知道:Linux 之父 Linus Torvalds,最近迷上了做吉他效果器,而且做得一塌糊涂。但在“失败

说了这么多,不是要告诉大家什么框架好或者不好。在Agent框架的选择上,没有绝对的对错,只有适不适合你的业务场景。我建议你用三个维度来评估:第一,业务复杂度:你的Agent需要处理多少种场景?场景之间是否有明确边界?复杂业务需要更灵活的框架,简单业务可能需要更稳定的框架。第二,团队能力:你的团队对框架的理解程度如何?学习成本vs开发效率的权衡?不要选择超出团队能力太多的框架。第三,演进预期:你的业

不少网友都提到,DeepSeek-V3.2的长思考增强版Speciale,确确实实以开源之姿又给闭源TOP们上了压力,但问题也很明显。DeepSeek-V3.2很强很火爆,但随着讨论的深入,还是有bug被发现了。并且是个老问题:浪费token。不少网友都提到,DeepSeek-V3.2的长思考增强版Speciale,确确实实以开源之姿又给闭源TOP们上了压力,但问题也很明显:在面对复杂任务时,消耗
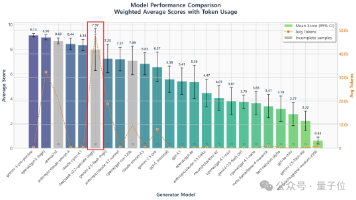
Gemini 3 DeepThink 现已向 Google AI Ultra 订阅用户推出。它代表谷歌在高级推理上的重大突破,专为攻克复杂数学、科学与逻辑问题而设计,性能达到行业领先水平。Gemini 3 DeepThink 现已向 Google AI Ultra 订阅用户推出。它代表谷歌在高级推理上的重大突破,专为攻克复杂数学、科学与逻辑问题而设计,性能达到行业领先水平。