登录社区云,与社区用户共同成长
邀请您加入社区
连接 Hadoop 的文件系统(HDFS)FileSystem类,是 Hadoop 提供的统一的文件系统抽象类,支持 HDFS、本地文件系统等。通过它可以进行文件的读取、写入、删除、检查是否存在等操作。启动Hadoop 集群环境(master) >是终端或命令行的提示符(prompt)意思是你当前所在的是本身不是命令,只是提示符的一部分用 bash 执行一个叫的 shell 脚本,路径是。就是一种
https://blog.csdn.net/atgfg/article/details/152522487?sharetype=blogdetail&shareId=152522487&sharerefer=APP&sharesource=2401_85812043&sharefrom=link
智能指针支持自定义删除器,极大扩展了其应用范围。除了管理常规堆内存,还可用于管理文件句柄(fclose)、网络连接(closesocket)、第三方库资源等任何需要释放的资源。最佳实践是使用lambda表达式或函数对象定义删除器,确保资源释放逻辑与获取逻辑对称。例如,unique_ptr可安全管理文件资源。这种方式将资源生命周期与对象作用域绑定,实现了广义上的资源管理,是现代C++资源管理哲学的核
经验心得。
一个更现代和可能更兼容的配置是,直接声明一个所有节点都能访问的域名。重启后,当NameNode再重定向您的Python客户端时,它就会提供一个基于IP的、您的Windows主机可以理解的地址,问题就解决了。print(f"从HDFS读取到的文件内容:\n---\n{content_from_hdfs}\n---"): 仔细观察PyCharm的运行控制台输出,它会一步步地显示连接、创建、写入、读取、
``html。
本文档旨在详细说明一个基于 C# 开发的客户端应用程序的功能架构与核心工作流程。该客户端支持连接本地或远程 OPC DA 服务器,浏览服务器中的数据节点(Tags),实时读取数据项的值、品质和时间戳,并支持向指定节点写入数据。程序基于实现,适用于工业自动化领域中与各类 OPC 服务器(如 Kepware、Matrikon、Siemens SIMATIC NET 等)进行通信的场景。
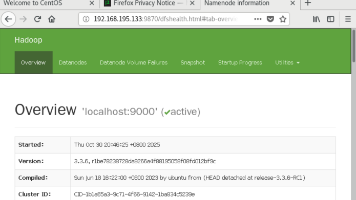
本文介绍了Hadoop HDFS的三种操作方式:Shell命令行、Web界面和Java API。Shell命令行提供了批量操作和进程管理功能,包括集群启停、文件传输等核心操作。Web界面通过9870端口访问,提供可视化文件管理功能。Java API适用于开发集成,需配置本地Hadoop环境和IDEA插件。三种方式各有优势,实际应用中可根据需求结合使用:Shell适合自动化运维,Web界面便于监控,
命令行操作适合系统管理员进行日常维护和批处理操作Web界面操作提供了直观的集群监控和基本的文件管理功能Java API操作为开发者提供了强大的编程接口,便于构建复杂的应用程序通过VMware Workstation 和MobaXterm的组合使用,我们可以在虚拟化环境中安全高效地学习和实践HDFS操作。建议各位读者根据实际需求选择合适的操作方式,并结合使用以达到最佳效果。
Hadoop 分布式文件系统(HDFS)作为大数据生态的核心存储组件,凭借高容错性、高扩展性及海量数据存储能力,成为分布式数据处理场景的基石。本文聚焦 HDFS 的三种核心客户端操作模式 —— 命令行客户端(client1)、9870 端口 Web UI 客户端(client2)与 Java API 客户端(client3),将系统拆解每种操作的实施步骤、核心特性、适用场景及优劣差异,同时阐明三者
本文围绕HDFS实操练习展开,覆盖了Shell命令、权限配置、图形化工具连接、NFS挂载及存储原理验证等核心内容。通过这些实操,可深入理解HDFS的分布式存储特性和操作逻辑。在实际应用中,需根据业务场景选择合适的操作方式,同时注意权限控制和集群稳定性维护。
想起第一次去公司就让我们手写分布式master和slave,刚开始是一个master对应多个slave,到后面多个master对应多个slave带数据备份,数据分段处理,任务下发各种功能,如果分布式理念用到安全,渗透等开发我们可以做什么,另一个大数据demo中我再说。大数据开发,在线%图书分析%系统开发,基于html,css,jquery,echart,python,django,hadoop,m
以下是 HDFS Java API 6 大类核心功能的独立代码示例,每个功能单独成类,可直接复制运行(需确保 Hadoop 依赖已配置,且集群正常运行,注意修改代码中hdfs地址)5. 元数据与状态 API(获取文件 / 目录元数据、块信息)1. 连接管理 API(获取 / 关闭 HDFS 连接)2.1 创建目录(支持多级)3.3 删除 HDFS 文件。
摘要:HDFS提供三种主要操作方式:Shell命令(hdfs dfs/hadoop fs)用于命令行交互,支持文件上传下载、目录创建删除等基本操作;Web界面(默认端口50070/9870)用于可视化浏览文件系统、查看文件属性和内容;Java API(FileSystem类)提供最灵活的编程式访问,支持目录操作、文件读写等。Shell适合管理员和脚本操作,Web界面便于监控和查看,Java API
本文详细介绍了通过Java API和Shell脚本在HDFS上创建文件的完整方案。核心内容包括:1) HDFS Java API的实现原理,涵盖Configuration、FileSystem等关键类;2) 40余行核心Java代码,实现连接HDFS、创建文件、写入数据全流程;3) Shell脚本封装方案,简化编译打包执行过程;4) 常见问题解决方法及生产环境最佳实践。该方案支持本地/远程集群操作
java.io.FileNotFoundException: File does not exist: hdfs://master:9000/sparklog
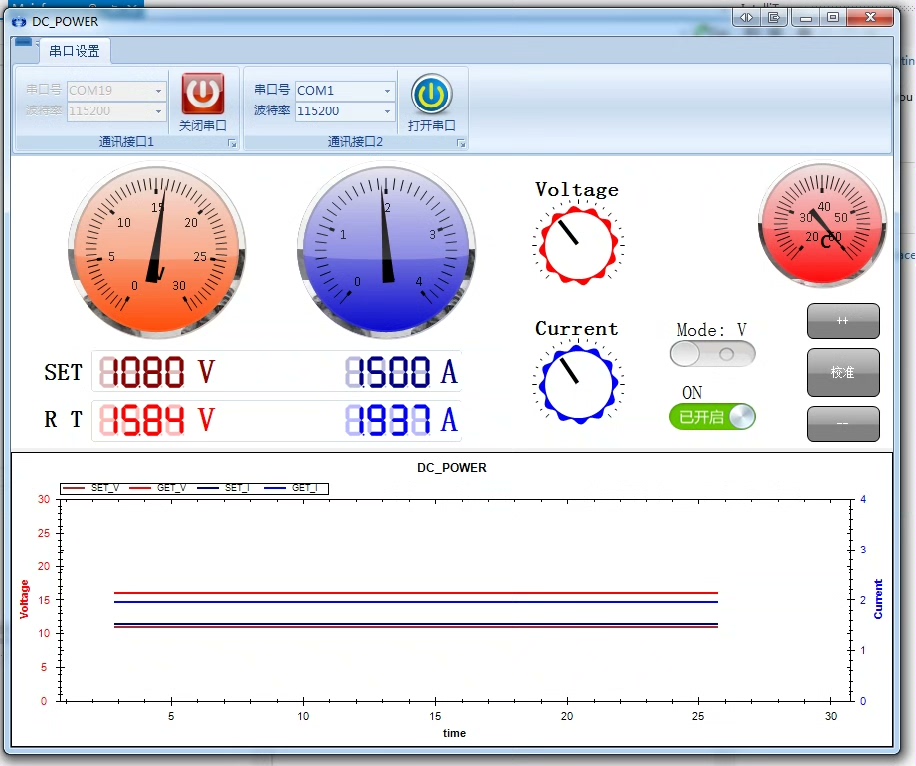
源码和STM32工程已打包,Github链接:https://github.com/xxxx/power-monitor (注:此为示意地址)下回咱们可以聊聊怎么用C#做PID参数整定界面,想看的评论区吱个声~1.该程序利用了codeproject上的zedgraph(绘图)、knob(表盘旋钮)、manometers(表盘)、ribbon、lbindustrialctrls(数码管等)这些控件,
本文通过一段简单的 Java 代码,完整讲解了 HDFS 文件写入的核心流程、关键 API 和实操细节。掌握这些基础操作后,可进一步探索 HDFS 的文件读取、删除、重命名、权限管理等功能,结合大数据计算框架(如 MapReduce、Spark)实现更复杂的业务场景。HDFS 作为大数据生态的存储基石,Java API 是操作它的最基础方式,理解底层逻辑、规范资源管理、注意编码细节,才能写出稳定、
使用hdfs库中的。以下实例涵盖连接、上传、下载、查看(列表/状态/内容)及删除操作。。
创建完maven项目之后,会生成pom.xml文件,编辑pom文件,配置jar包的版本号和名称,把运行hadoop程序所依赖的jar包配置好之后重新加载,idea就会自动下载所需要的jar包,显示在External Libraries文件列表中。HDFS作为Hadoop实现的其中一个文件系统,除了能使用Shell操作HDFS的文件和目录之外,还可以通过HDFS提供的Java API操作HDFS的文
本文详细解析了Hadoop开发中常见的‘No FileSystem for scheme hdfs’错误,提供了六种解决方案,包括依赖配置、文件加载和版本兼容性检查。特别强调了core-site.xml的正确配置和HDFS客户端库的必要性,帮助新手快速定位和修复问题。
打进 Jar 包,编译时保留、打包剔除集群执行用 hadoop jar 命令时,程序运行依赖的 Hadoop 核心包(hadoop-common、hadoop-hdfs、mapreduce、yarn 等)全部由集群服务自带,运行时自动加载,不用打入自己的业务 Jar。hadoop jar 读取 Jar 内部 META-INF/MANIFEST.MF 里的 Main-Class 属性,如果配置了,命
1、windows能ping通虚拟机IP地址【虚拟机网络改为桥接模式,改为固定IP】2、Linux开放端口:9000,9870,8088【使用windows的 PowerShell,执行:Test-NetConnection IP地址 -Port 9000,需要修改linux中hadoop配置文件hdfs-site.xml和core-site.xml】3、windows配置Hadoop本地依赖4、
1 文件系统: 文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易。2 文件名 : 在文件系统中,文件名是用于定位存储位置。3 元数据(Metadata):保存文件属性的数据,如文件名,文件长度,文件所属用户组,文件存储位置等。4 数据块(Block):存储文件的最小单元。对存储介质划分了固定的区域,使用时按这些区域分配使用。HDFS产生背景随着数据量的增加,在一个操作系统存不
import xml.etree.ElementTree as ETimport pickleimport osfrom os import getcwdimport numpy as npfrom PIL import Image# 引入一个新的目标检测库import imgaug as iafrom imgaug import augmenters as iaafrom utils impor
本课程基于Abaqus,应用两种加载方式一-FluidCavity与Pressure分别介绍了气动驱动软体机器人仿真分析流程。该软体机器人涉及两种材料,主变形部分选用超弹性材料,应用Yeoh本构定义材料属性;限制层部分定义为线弹性材料。此外,对结果的后处理进行了简要介绍。想学轮胎充气、气囊充气、各种充气分析都能用最近学习了一个超有意思的课程,基于Abaqus平台,深入探讨了气动驱动软体机器人的仿真
上节我们已经成功配置并启动了hadoop集群,1台namenode节点,2台datanode节点,接下来我们就利用hadoop大杀器,使用HDFS和Mapreduce1、测试HDFS的功能我们先上传一个文件到HDFS,先查看software目录里面有我们之前配置java的jdk包,我们就上传这个文件,输入hadoop可以查看帮助信息,看到有fs我们再输入hadoop fs,可以看到有很多命令可用,
五.HDFS架构大多数分布式大数据框架都是主从架构HDFS也是主从架构Master|Slave或称为管理节点|工作节点主叫NameNode,中文称“名称节点”从叫DataNode,中文称“数据节点”5.1 NameNode5.1.1 文件系统file system文件系统:操作系统中负责管理文件、存储文件信息的软件具体地说,它负责为用户创建文件,存入、读取、修改、转储、删除文件等读文件 =>.
记得在材料属性里把两相黏度比调成3:1,表面张力系数设0.072N/m,这参数能让界面变形更明显。提供基于comsol中相场方法模拟多孔介质两相驱替(水气、油水等等)的算例(也可以定做水平集驱替的算例),可在此基础上学会利用comsol软件进行两相流驱替的模拟,拓展研究,具体参考算例附后。先来点有意思的——想象把咖啡渍从桌布里挤出来的过程,这就是典型的水气驱替场景。把时间步长改自适应BDF方法,稳
本文为你提供了一套完整的HDFS DataNode故障处理流程,涵盖节点下线、数据重建、磁盘更换三大核心场景。如何安全下线故障DataNode(不丢失数据);如何快速重建丢失的数据块(恢复副本完整性);如何更换故障磁盘(最小化集群影响)。关键结论处理DataNode故障的核心原则是**“数据不丢失、集群不宕机”**;优雅下线节点(使用命令)比直接重启更安全;定期检测磁盘状态(使用smartctl)
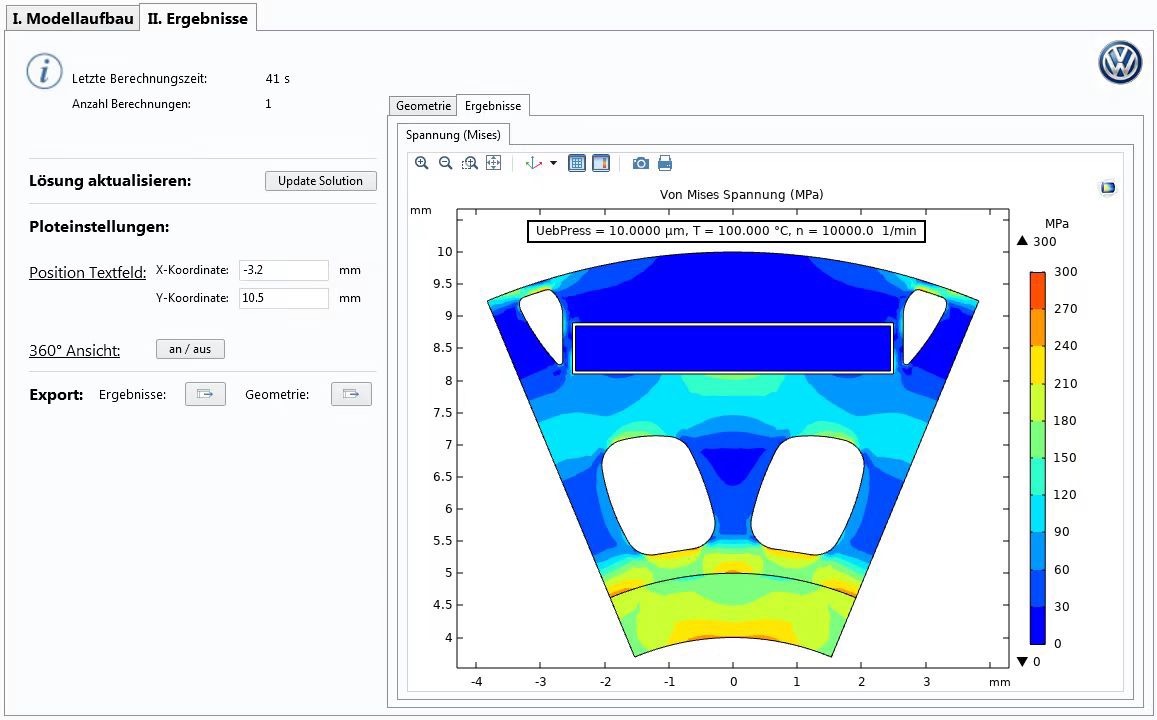
还有个骚操作是把电压模型和电流模型的输出做加权融合,低速时主要用电流模型,高速时切到电压模型,这个切换逻辑要用滞回比较防止震荡。实际调试时有个骚操作:把wc设成与转速相关,当转速低于2Hz时自动增大wc值,相当于给积分器加了动态阻尼。注意第12行的幅值箝位,这是对付直流偏置的土办法,比纯软件滤波来得直接。但要特别注意,当电机温度变化超过50℃时,记得重新标定一次转子电阻参数,否则时间常数辨识会跑偏
一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。设计理念为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负
hdfs
——hdfs
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区









 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 openEuler 社区
openEuler 社区

 DAMO开发者矩阵
DAMO开发者矩阵