
写文章




- @lzw379764332
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
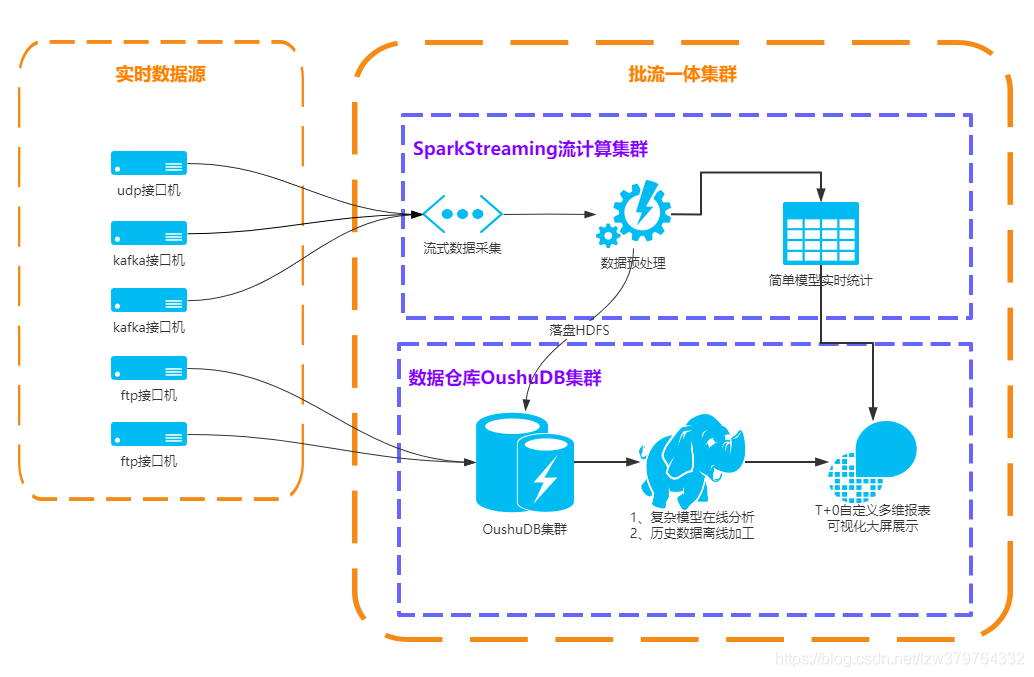
基于Kafka+SparkStreaming+OushuDB搭建批流一体大数据分析架构
流式计算。Spark Streaming的实现非常简单,通过微批次将实时数据拆成一个个批处理任务,通过批处理的方式完成各个子Batch。Spark Streaming的API也非常简单灵活,既可以用DStream的java/scala API,也可以使用SQL定义处理逻辑。但Spark Streaming受限于微批次处理模型,业务方需要完成一个真正意义上的实时计算会非常困难,比如基于数据事件时间、
到底了