登录社区云,与社区用户共同成长
邀请您加入社区
本文是一篇系统整理的KNN算法学习笔记。内容从“近邻相似”的直观思想出发,梳理了KNN的分类与回归步骤,深入讲解了欧氏距离、曼哈顿距离等常用相似性度量及KD树的加速检索原理,并分析了K值大小对模型过拟合与欠拟合的影响。结合scikit-learn的API用法,进一步补充了交叉验证与网格搜索在超参数调优中的应用,旨在帮助读者构建清晰、可复用的KNN知识框架。
KNN 全称K-Nearest Neighbors,K 近邻算法。物以类聚。在预测一个样本的时候,找寻距离它最近的 k 个邻居,通过少数服从多数来划分类别。
源码里还有个路径规划算法的Demo,用A*算法实现避障,虽然比不上商业系统的算法库,但理解基本原理足够用了。介绍:c#winform系统模板,包含socket连接,多线程处理demo,MySQL连接进行增删查改,日志记录功能,写法规范,有通用类可以直接调用,可用于学习。介绍:c#winform系统模板,包含socket连接,多线程处理demo,MySQL连接进行增删查改,日志记录功能,写法规范,有
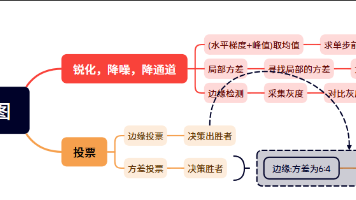
本文介绍了NS航司验证码破解的技术方案,主要针对六种随机下发的滑动验证码类型(Silder/CURVE2/CURVE/WORD/MOBIE/Silder2)。方案包含三个关键环节:1) 通过接口分析获取验证码背景图;2) 采用图像处理技术(灰度化、降噪、边缘检测等)定位缺口位置;3) 模拟人类滑动轨迹(变速移动+随机抖动)。该方案通过结合缺口检测(60%)和局部方差分析(40%)的投票机制,识别准
从Java的虚拟机抽象到C/C++的源码级可移植,从Python的解释器兼容到现代.NET的全面跨平台,每一种语言都在以自己的方式解决跨平台开发的挑战。成功的跨平台实战不在于追求某种“万能”的语言,而在于深刻理解各语言的优势与局限,并根据项目目标设计合理的架构。无论是选择单一语言的纯粹方案,还是采用多语言协同的混合策略,核心都在于通过抽象和封装来隔离平台差异,确保业务逻辑的稳定与复用。
通过本文方法可让C++程序在保持可维护性的同时,达到比低效代码快10-50倍的性能提升,具体取决于应用领域和具体优化措施。- 代码分块与注释:逻辑复杂处用`#pragma region`划分模块(需编译器支持)或通过函数封装。void deallocate(T obj) { / 归还对象到池中 / }T allocate() { / 从预分配内存块中取空间... / }auto process(T
设计条件对抗损失函数L_adv = log(D(AE(x))) + log(1-D(G(z))),其中AE代表自编码器重建真实场景特征,G生成合成干扰场景。在PyTorch的Optimizer中插入自适应动量项m_t=βm_{t-1}+(1-β)g_t,其中β根据突发噪声能量实时调整,该机制使系统在突发枪击声环境下的恢复时间缩短至1.2秒。在PyTorch的钩子机制中实现层粒度的冻结控制算法,配合
比如飞行里程数的范围是 0~134000,那么 134000 归一化后是 1,400 归一化后是 400/134000≈0.003,这样就和其他特征的量级一致了。K 值选择:目前 K=3 是经验值,可通过 “交叉验证” 选最优 K(比如用 5 折交叉验证,测试 K=1/3/5/7,选准确率最高的 K);K 近邻的核心逻辑可以总结为 “近朱者赤,近墨者黑”—— 未知样本的类别,由它周围 “最近的 K
实用小技巧:PyCharm中以函数化封装代码并在JupyterNoteBook中调用
(1)计算已知类别数据集中的点与当前点之间的距离;(2)按照距离递增次序排序;(3)选取与当前点距离最小的k个点;(4)确定前k个点所在类别的出现频率;(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
简单直观:算法原理易于理解,实现简单,不需要复杂的数学背景。无需训练阶段:作为惰性学习算法,KNN没有显式的训练过程,只需存储数据。适用性广:既能处理分类问题,也能处理回归问题。非参数特性:不对数据分布做任何假设,能够适应复杂的数据模式。理论基础坚实:有严格的理论保证,如Cover和Hart关于错误率的界限证明。计算效率低:预测时需要计算查询点与所有训练样本的距离,对于大规模数据集计算成本很高。内
文章目录一、KNN1、K值的判断与选取2、缺失值差填补3、KNN填充和模型评估4、RESSION一、KNNKNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。KNN属于懒惰
蜂窝晶格光子晶体的拓扑性质最近在光学领域火得不行,但计算陈数这事儿总让新手头疼。先别急着打开软件,记住核心逻辑:陈数就是Berry曲率在整个布里渊区的积分,而光子晶体要实现非零陈数,结构必须打破时间反演对称性。别慌,这是网格不够密的正常现象。最后记得验证时间反演对称性——把磁场方向反转,陈数符号应该翻转,这才是真·拓扑非平庸的实锤。这里braket函数得处理规范自由度,建议用⟨u|v⟩/|⟨u|v
优点:精度高、对异常值不敏感、无数据输入假定。缺点:计算复杂度高、空间复杂度高。适用数据范围:数值型和标称型。收集数据:可以用任何方法。准备数据:距离计算所需要的数据,最好是结构化的数据格式。分析数据:可以使用任何方法。训练算法:不适用于k-近邻算法。测试算法:计算错误率。使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行
KNN算法
最近在搞时序预测的朋友可能都听说过LSTM的鼎鼎大名,但这种"单打独斗"的模型遇到复杂场景时总有点力不从心。LSTM-Multihead-Attention回归预测 基于长短期记忆神经网络(LSTM)结合多头注意力机制(Multihead-Attention)多变量回归预测[可以修改为时序预测,前]这里有个细节要注意——输入特征和预测目标在滑窗时是错位的,就像看连续剧时用前24集剧情预测第25集发
机器学习近邻算法总结
(1)算法简单,理论成熟,可用于分类和回归。(2)对异常值不敏感。(3)可用于非线性分类。(4)比较适用于容量较大的训练数据,容量较小的训练数据则很容易出现误分类情况。(5)KNN算法原理是根据邻域的K个样本来确定输出类别,因此对于不同类的样本集有交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为合适。(6)对数据类型(图片,文本,视频)不做限制(1)时间复杂度和空间复杂度高。(训练复杂度为
重点看那个sind和cosd的用法,角度单位千万别搞错,新手容易在这翻车。算出来的坐标要扔进Adams里验证运动轨迹,别问我怎么知道的——都是血泪教训。麦弗逊悬架硬点布置这事儿,说难不难说简单也不简单。计算内容:根据设计输入,布置麦弗逊悬架硬点坐标,匹配转向拉杆断开点,匹配车轮外倾角和前束值,从而获得硬点初版坐标。(2)技术文档:包括硬点布置,计算结果验证,外倾和前束匹配原理,减振器侧向力,双球头
算法又叫KNN算法,是一种分类算法,这个算法是机器学习里面一个比较经典的算法, 总体来说 KNN 算法是相对比较容易理解的算法。定义:如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。通过你的“邻居”来判断你属于哪个类别如何计算你到你的"邻居"的距离:一般时候,都是使用欧氏距离算法流程计算已知类别数据集中的点与当前点之间的距离按距
KNN即k近邻法,k-nearest neighbor,是1967年由Cover T和Hart P提出的一种基本分类与回归方法,也是机器学习的基础算法之一。本文参考教程:《机器学习实战》KNN算法原理在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较
机器学习 入门 knn算法简单实现
给定一个训练数据集,对于新输入的实例,在训练数据集中找到与该实例最近的k个实例,这k个实例的多数属于某个类,就将该输入实例划分为某个类通俗来说,就是未标记的样本类别,由距离其最近的k个邻居投票决定,少数服从多数。
今天咱们直接上干货,用Matlab撸个Drude模型计算VO2介电常数,再教你怎么塞进CST里用。找篇靠谱论文扒参数,比如某文献给的数据:ε∞=12,ω_p=1.5×10^15 rad/s,γ=5.75×10^13 rad/s(金属态参数)。遇到过有人导数据时单位没统一,结果在30GHz处出现诡异谐振峰,后来发现是txt里频率单位错写成了THz。最后提醒:做时域仿真时优先用解析式Drude模型,表
项目内容:用K-近邻算法,对Mnist数据集完成手写数字的识别主要内容:读取Mnist数据集获取图片数据的函数读取标签数据的函数分类函数classify0测试代码第三方库:numpy、matplotlib、operator、struct(后两个主要用于读取Mnist数据集用)有关struct库使用的方法请自行百度了解。代码:MNist数据集的数据结构:代码:from numpy import *i
本课程基于Abaqus,应用两种加载方式一-FluidCavity与Pressure分别介绍了气动驱动软体机器人仿真分析流程。该软体机器人涉及两种材料,主变形部分选用超弹性材料,应用Yeoh本构定义材料属性;限制层部分定义为线弹性材料。此外,对结果的后处理进行了简要介绍。想学轮胎充气、气囊充气、各种充气分析都能用最近学习了一个超有意思的课程,基于Abaqus平台,深入探讨了气动驱动软体机器人的仿真
摘要:实验基于Python的sklearn库,使用K近邻算法(KNN)实现鸢尾花三分类任务。通过数据探索、标准化处理和训练集/测试集划分(75%/25%),构建K=3的KNN分类模型。结果显示模型在测试集上实现了100%准确率,完美区分了Setosa、Versicolour和Virginica三类鸢尾花。实验验证了KNN算法在特征区分度高的数据集上的有效性,完成了机器学习分类任务的基本流程实践。
不过需要提醒的是,选择中转平台一定要优先选运营时间久、用户口碑好的正规平台,避开不知名的小平台——不少小平台会通过虚报Token用量、悄悄降级模型版本来压缩成本,长期使用下来不仅成本更高,还可能存在数据泄露的风险。这类平台的运作模式已经非常成熟:平台统一批量采购官方API额度,搭建国内中转加速节点,再拆分卖给国内开发者,支持微信、支付宝等国内主流支付方式直接充值,开发者只需要修改代码里的一行接口地
如果用第三方中转服务依然遇到频繁超时,要先检查是不是自己选的模型不对——如果你用Opus模型处理几十万Token的长上下文请求,单请求推理时间本身就会超过10秒,对于低延迟要求的业务场景自然容易触发超时,这种时候换成Sonnet模型就能解决大部分问题。很多开发者本地测试用的是测试配额的密钥,部署到生产服务器的时候忘记替换成正式密钥,上线跑起来直接抛401错误,排查半天都找不到问题。不要轻信所谓的免
近邻算法
——近邻算法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵