




- @Trisyp
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章摘要:针对Codex CLI安装报错"Missing optional dependency @openai/codex-linux-x64"问题,提供了完整的Ubuntu解决方案。首先建议通过卸载后使用国内镜像源重新安装(npm install -g @openai/codex@latest --registry=https://registry.npmmirror.co

终端输入可以正常执行脚本,而加入crontab中没有任何输出
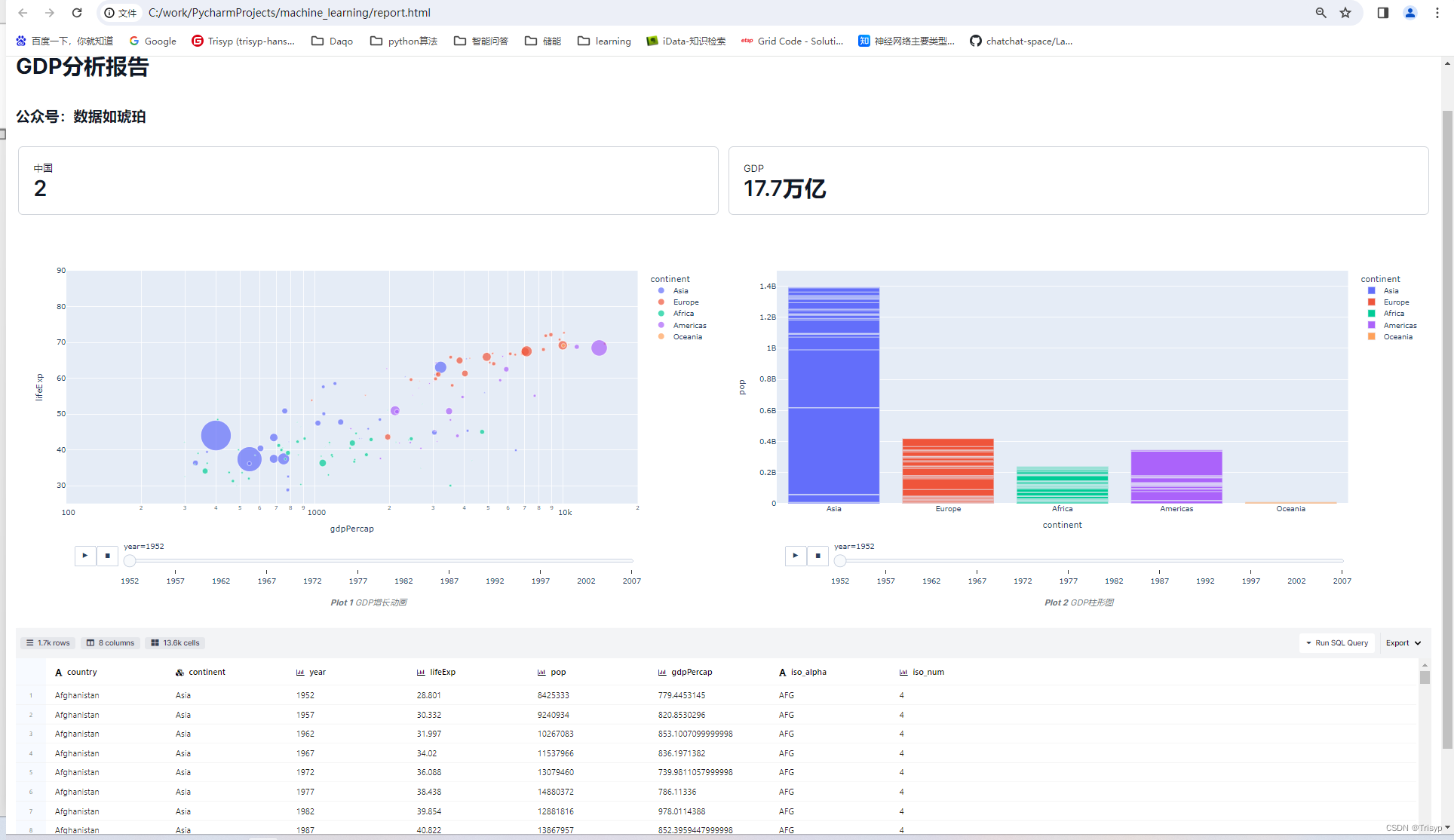
-利用datapane整合报告:上面的报告里面,fig采用Plot来生成报告,df采用DataTable生成报告,还有标题,数字仪表也是类似的方式生成。dp.BigNumber(heading="GDP", value="17.7万亿"),columns=2,),dp.Plot(fig2, caption="GDP柱形图"),columns=2),--各种展现方式,数字仪表盘,动图,数据表格,描述
执行python manage.py makemigrations命令无任何文件生成,结果显示“No changes detected”。
Airflow是一个以编程方式编写,用于管理和调度工作流的平台。可以帮助你定义复杂的工作流程,然后在集群上执行和监控这些工作流。Airflow计划程序在遵循指定的依赖项,同时在一组工作线程上执行任务。丰富的命令实用程序使在DAG上执行复杂的调度变的轻而易举。Airflow的可扩展Python框架可以让你构建连接几乎任何技术的工作流程。丰富的用户界面可以随时查看生产中正在运行的管道,帮助你管理工作流
import rehtml = '<div class="desc">累计签到获取,不积跬步,无以至千里,继续坚持!</div>'# 方法1pat = re.compile('<[^>]+>', re.S)print(pat.sub('', html))# Out[4]: 累计签到获取,不积跬步,无以至千里,继续坚持!# 方法2pat = re.compi

执行python manage.py makemigrations命令无任何文件生成,结果显示“No changes detected”。
Yolov5训练自己的数据集,目标检测
自然语言处理(英语:Natural Language Process,简称NLP)是计算机科学、信息工程以及人工智能的子领域,专注于人机语言交互,探讨如何处理和运用自然语言。自然语言处理的研究,最早可以说开始于图灵测试,经历了以规则为基础的研究方法,流行于现在基于统计学的模型和方法,从早期的传统机器学习方法,基于高维稀疏特征的训练方式,到现在主流的深度学习方法,使用基于神经网络的低维稠密向量特征训
文章地址:https://www.jianshu.com/p/23949ca4f8ab文章写的比较容易理解,但仅仅对二分类的学习问题可行性进行讨论,并非所有的机器学习输出空间都是二值的,其他类型的需要更深入的学习了。文章参考资料:[1] Learning From Data(网易公开课).[2] 林轩田机器学习基石(B站公开课).[3] No Free Lunch Theorems.[4] 机器学