




- @wiyi9891
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了TensorFlow的基本概念和入门实践。主要内容包括:1) TensorFlow的简介及其优势,将其比作"AI积木工厂";2) 安装指南和环境要求;3) 核心概念:张量、计算图和自动微分;4) 通过房价预测案例演示简单神经网络的构建与训练流程;5) 手写数字识别项目的引入。文章使用生活化比喻和代码示例相结合的方式,帮助初学者快速理解TensorFlow的基本使用方法

摘要:本教程介绍了GPT模型的基本原理与实现方法,重点讲解了Transformer解码器的自回归生成机制。通过代码演示如何使用HuggingFace的GPT-2模型进行文本生成,包括模型加载、参数设置和生成函数实现。教程包含完整的项目结构、常见问题解答和课后练习,适合初学者快速上手文本生成应用。关键点包括单向注意力机制、预训练模型使用和生成参数调整技巧,最后还提供了中文生成方案和扩展学习资源。

作为一个深度剖析 AI 应用开发平台的系列文章,我们已经从宏观架构设计和后端服务架构两个维度理解了 Dify。今天,让我们把目光转向前端——这个用户感知最直接、交互最频繁的层面。在前端技术日新月异的当下,Dify 选择了 Next.js + TypeScript + Tailwind CSS 的现代化技术栈。但更有趣的是,它在状态管理上的选择和实践,以及整个前端架构的设计哲学。

Dify性能优化实践:从缓存设计到异步处理 本文深度剖析Dify应用的性能优化策略,涵盖以下关键技术点: 多层缓存架构: 三级缓存设计(内存→Redis→数据库) 智能缓存穿透保护和自动回填机制 三类缓存失效策略:立即失效、延迟失效和写穿 向量检索优化: 嵌入向量和检索结果分别缓存 采用不同TTL策略(24小时 vs 1小时) 基于查询哈希的高效缓存键生成 监控体系: 实时记录缓存命中/未命中情况

摘要: 本教程基于BERT模型实现情感分析任务,讲解微调预训练模型的核心流程。首先介绍BERT的双向编码优势及其在情感分析中的适用性,包括上下文理解和情感词捕捉能力。通过HuggingFace Transformers库,逐步演示数据加载(SST-2数据集)、BERT模型初始化、文本预处理(分词与格式化)以及训练配置(学习率2e-5、3轮训练)。代码涵盖完整训练评估流程,最终模型在验证集准确率达9

理解提示词工程的核心原理掌握5种实用的Prompt设计模式学会优化提示词的评估方法实现一个智能问答系统优化案例

本文介绍了插件系统与扩展机制的设计与实现。首先概述了插件系统的整体架构,包括守护进程结构和多种插件类型。然后详细讲解了插件的加载机制、API扩展点实现方法以及自定义工具开发流程。接着探讨了插件生态建设的重要性和具体措施。最后讨论了插件系统的监控运维方案,并对未来发展提出了展望。全文系统性地阐述了构建可扩展插件平台的关键技术与实践方法。
第2章:后端服务架构深度剖析。
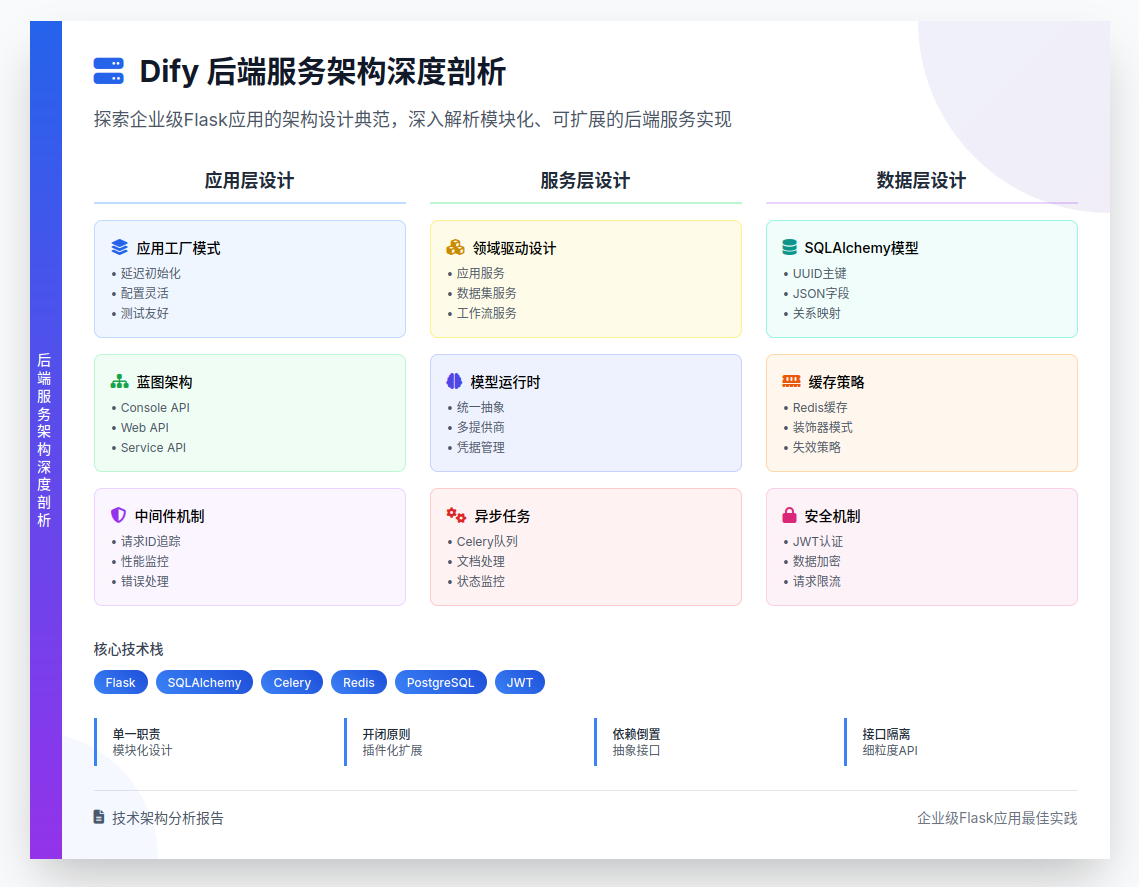
Dify开源平台的架构演进与未来展望 文章分析了Dify平台从Beehive架构向Organism架构的进化路径,预测其将具备自愈性、自适应和自进化三大特征。在插件系统方面,文章展望了从当前解耦架构到智能插件编排,再到自进化插件生态的三级跃迁。模型运行时方面,文章指出Dify已实现统一接口和负载均衡,未来可能向更智能的资源调度发展。整体而言,Dify正在从模块化工具平台向具备自我优化能力的AI应用

第1章:Dify架构概览与核心概念。
