




- @m0_52053228
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
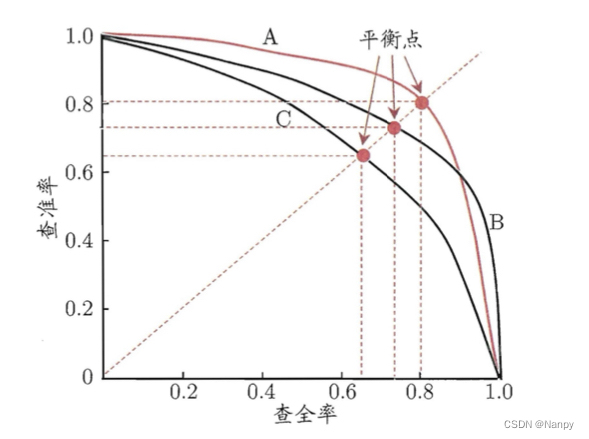
我们经常会关心“检索出的信息中有多少比例是用户感兴趣的”“用户感兴趣的信息中有多少被检索出来了”。“查准率”(precision)与“查全率”(recall)是更为适用于此类需求的性能度量。一、查准率P、查全率R与P-R曲线P-R图直观地显示出学习器在样本总体上的查全率、查准率。本文章仅简单概述了Precision、Recall以及P-R曲线的概念以及如何用Python绘制P-R曲线,作者目前也是
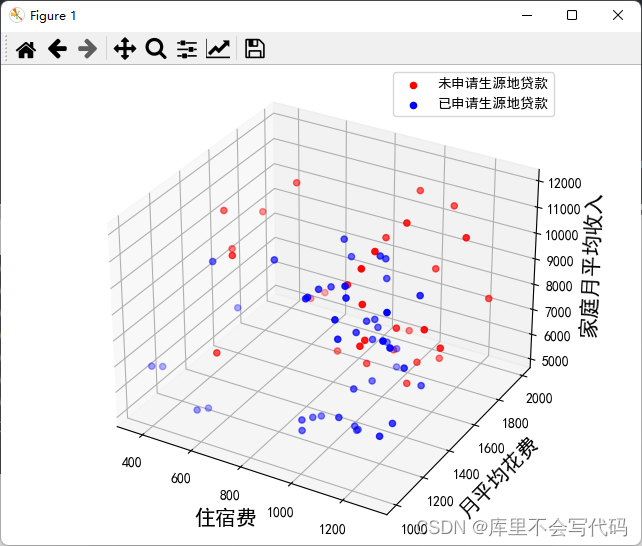
概率论是许多机器学习算法的基础,此篇博客会给出一些使用概率论进行分类的方法。首先从一个最简单的概率分类器开始,然后给出一些假设来学习朴素贝叶斯分类器。我们称之为“朴素”,是因为整个形式化过程只做最原始、最简单的假设。我们还将构建另一个分类器,观察其在真实的垃圾邮件数据集中的过滤效果。
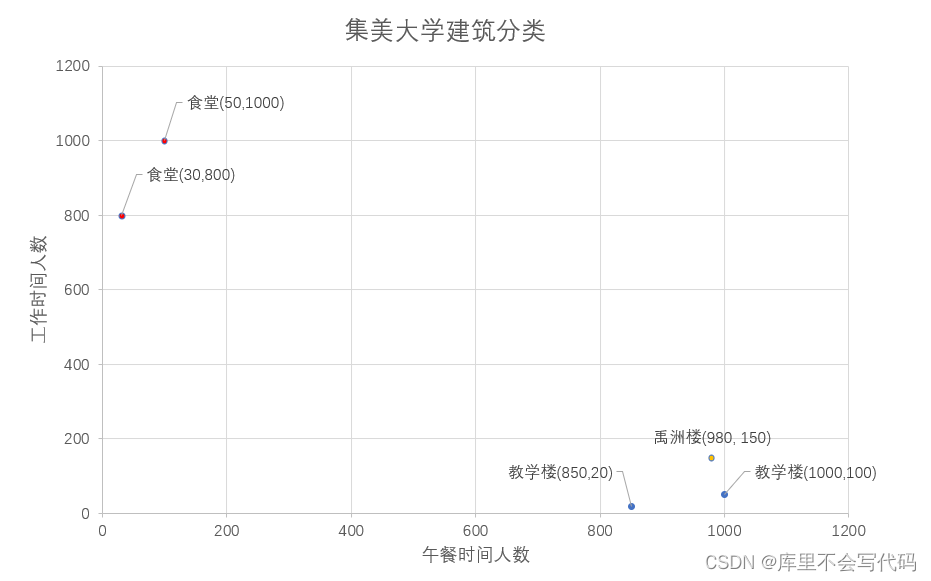
k-近邻(k-Nearest Neighbor,简称kNN)是一种常用的监督学习方法,其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测,选择这k个样本中出现最多的类别标记作为预测结果。,其类型属于图书馆,而k-近邻算法不会,因为在它眼里,建筑类型只有食堂和教学楼,它会提取样本集中特征最相似数据(最邻近)的分类标签,得到的
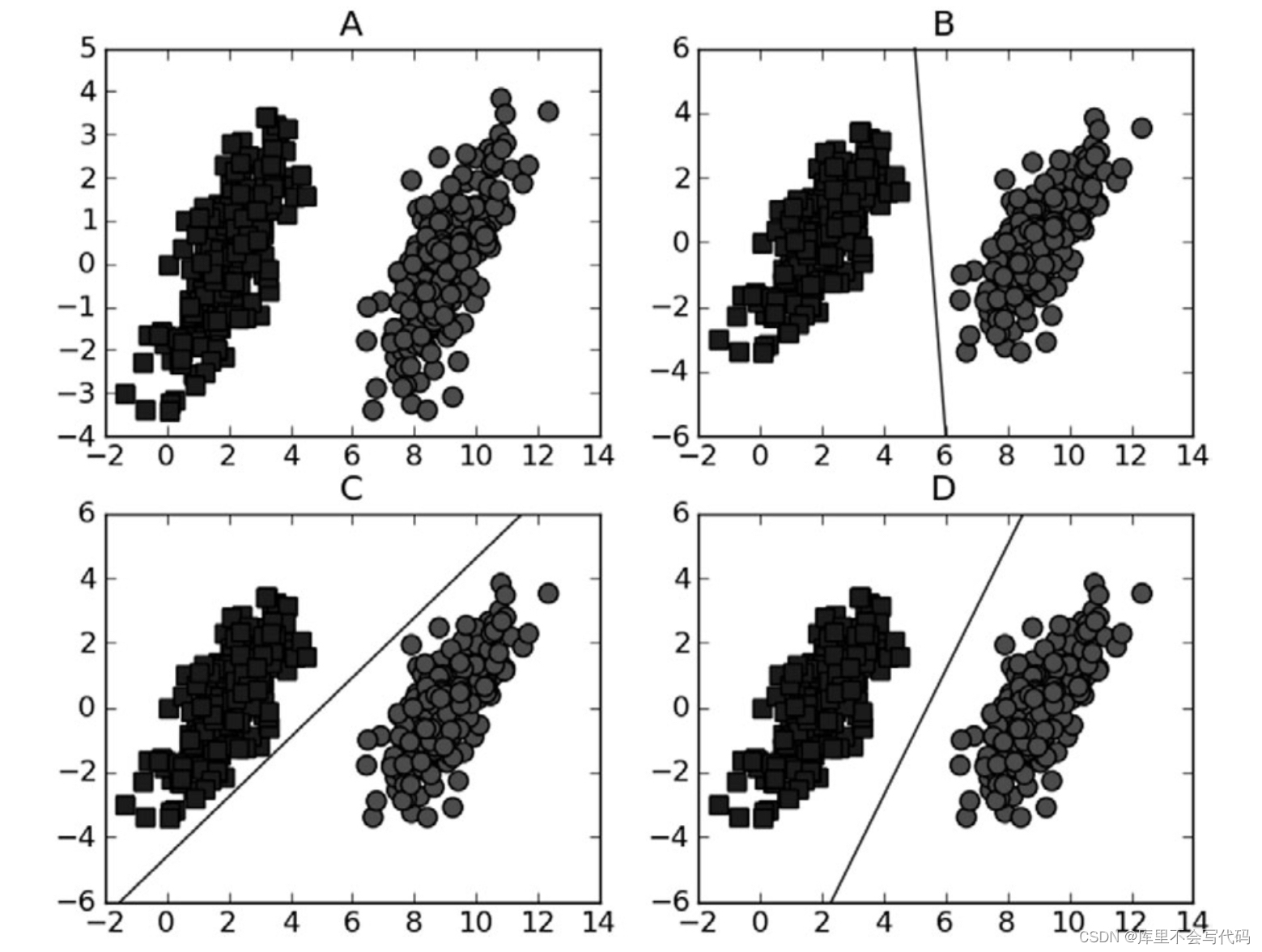
支持向量机算法可以解决小样本情况下的机器学习问题,简化了通常的分类和回归等问题。由于采用核函数方法克服了维数灾难和非线性可分的问题,所以向高维空间映射时没有增加计算的复杂性。换句话说,由于支持向量计算法的最终决策函数只由少数的支持向量所确定,所以计算的复杂性取决于支持向量的数目,而不是样本空间的维数。支持向量机算法利用松弛变量可以允许一些点到分类平面的距离不满足原先要求,从而避免这些点对模型学习的
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。决策树剪枝的基本策略有“预剪枝”(prepruning)和“后剪枝”(postpruning)。预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点得划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为
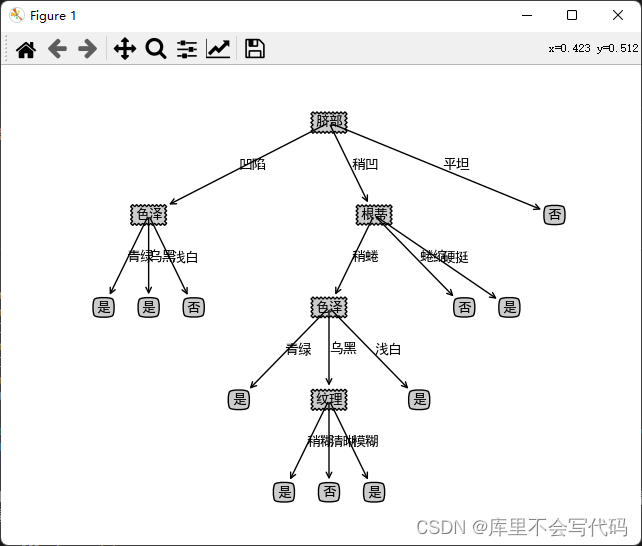
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。决策树剪枝的基本策略有“预剪枝”(prepruning)和“后剪枝”(postpruning)。预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点得划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为
概率论是许多机器学习算法的基础,此篇博客会给出一些使用概率论进行分类的方法。首先从一个最简单的概率分类器开始,然后给出一些假设来学习朴素贝叶斯分类器。我们称之为“朴素”,是因为整个形式化过程只做最原始、最简单的假设。我们还将构建另一个分类器,观察其在真实的垃圾邮件数据集中的过滤效果。