- @pan13360344415
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了数据集中缺失值的表现形式、判断方法和处理技巧。缺失值在不同环境中可能表示为NULL、NA、空字符串或NaN(在Pandas中)。判断缺失值时,推荐使用pd.isnull()而非np.isnan,因其能处理更多数据类型。处理缺失值主要包括两种方法:删除(dropna)和填充(fillna)。删除适用于少量缺失值,填充则可采用固定值、前后值或线性插值等方式。文章以泰坦尼克号数据集为例,演示了
本文介绍了pandas中的三种数据处理方法:1)向量化操作,通过底层C代码实现高性能数组运算;2)np.vectorize伪向量化,将普通函数转换为可处理数组的接口,性能介于循环和向量化之间;3)apply函数,提供最高灵活性但性能最低。重点分析了apply函数在Series和DataFrame中的应用场景,包括元素级处理、行列操作,并以泰坦尼克数据集为例展示了缺失值统计的实现。三种方法在性能与灵
很多人担心 “AI 会抢我的工作”“AI 会统治人类”,其实不用这么害怕。AI 就像以前的 “ electricity”—— 刚开始大家也担心 “ electricity 会电死人”,但后来发现, electricity 能点亮灯、带动机器,让生活更方便。AI 也是一样,它会代替一些重复、枯燥的工作,比如工厂里的流水线工人、银行里的柜员,但也会创造新的工作,比如 AI 训练师、AI 伦理师、AI
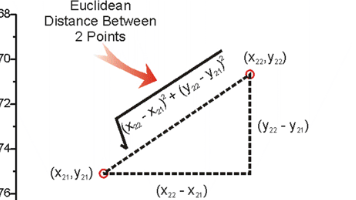
KNN算法是一种基于相似度的分类和回归方法,通过计算样本距离进行分类预测。关键要素包括k值选择(影响模型复杂度)、距离度量(欧氏/曼哈顿/切比雪夫距离)和特征预处理(归一化/标准化)。应用流程包含数据分割、模型训练、预测评估等步骤,案例演示了鸢尾花分类和手写数字识别。算法优势是简单直观,但需注意k值选择和特征缩放对结果的影响。