




- @m0_46553432
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
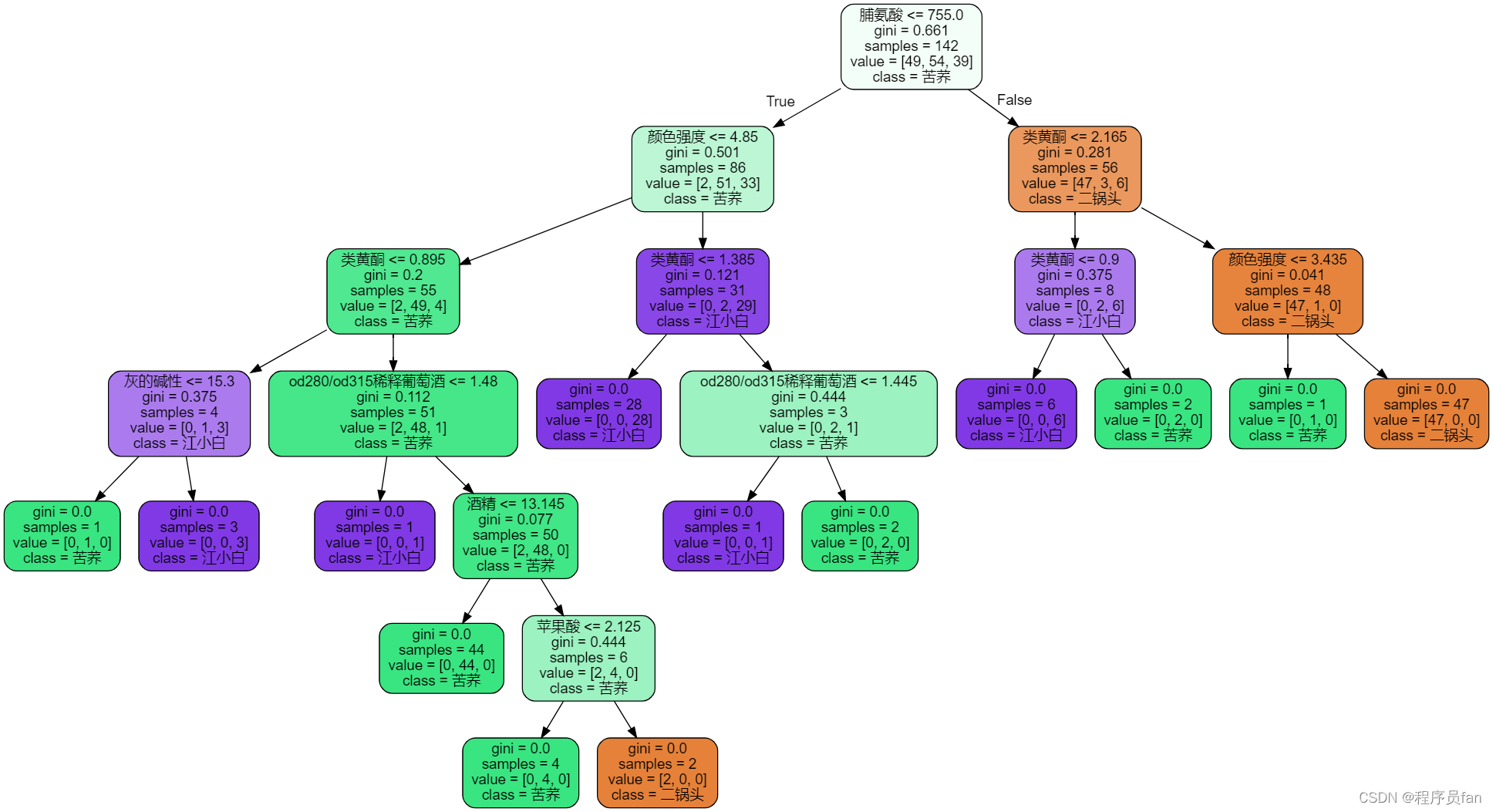
1、使用sklearn的决策树算法对葡萄酒数据集进行分类,要求:划分训练集和测试集(测试集占20%)对测试集的预测类别标签和真实标签进行对比输出分类的准确率调整参数比较不同算法(ID3,C4.5,CART)的分类效果。2、把ID3算法修改为CART,并实现以下例子的分类。
1、编写代码,实现对iris数据集的KNN算法分类及预测,要求:(1)数据集划分为测试集占20%;(2)n_neighbors=5;(3)评价模型的准确率;(4)使用模型预测未知种类的鸢尾花。2、改进模型,要求:(1)数据集划分采用10折交叉验证;(2)寻找最优的n_neighbors值(在5-10之间);(3)使用新的模型预测未知种类的鸢尾花。待预测未知数据:X1=[[1.5 , 3 , 5.8

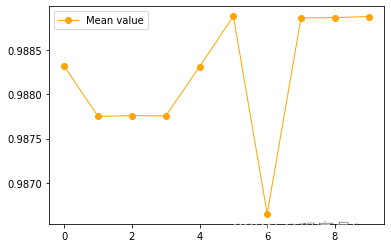
实现PCA算法实例2,要求:1、实现手写数字数据集的降维;2、比较两个模型(64维和10维)的准确率;3、对两个模型分别进行10次10折交叉验证,绘制评分对比曲线。机器学习实验:主成分分析法PCA实现手写数字数据集降维和分类...
机器学习实验:朴素贝叶斯算法编程实现朴素贝叶斯算法,并根据如下训练集输出预测结果:预测样本{Outlook=Sunny,Temp=Cool,Humidity=High,Wind=Strong}是否打球。给出代码与运行结果图。根据给出的算法naivebayes.py,实现:1、将数据集文件naivebayes_data.csv中的数据替换成14天打球与天气数据;2、预测样本{Outlook=Sunn
机器学习实验:主成分分析法PCA的实现主成分分析是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度。代码实现:导入相关库import sysdefaultencoding = 'utf-8'from math import *import random as rdimport num
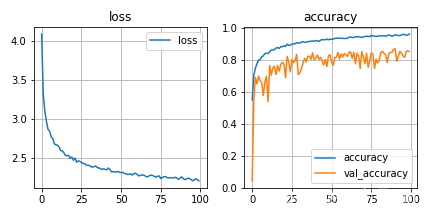
PointNet代码实现——tensorflow2框架Tensorflow2.0实现PointNet网络点云网络PointNet代码实现ModelNet40训练PointNet点云网络ModelNet40数据集训练前两天读了一下PointNet的论文,看了一下源码是用tensorflow1写的,关于**tensorflow2**实现PointNet的博客比较少,所以就自己查找资料复现了一下,数据集
机器学习实验:朴素贝叶斯算法编程实现朴素贝叶斯算法,并根据如下训练集输出预测结果:预测样本{Outlook=Sunny,Temp=Cool,Humidity=High,Wind=Strong}是否打球。给出代码与运行结果图。根据给出的算法naivebayes.py,实现:1、将数据集文件naivebayes_data.csv中的数据替换成14天打球与天气数据;2、预测样本{Outlook=Sunn
机器学习实验:主成分分析法PCA的实现主成分分析是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度。代码实现:导入相关库import sysdefaultencoding = 'utf-8'from math import *import random as rdimport num
1、使用sklearn的决策树算法对葡萄酒数据集进行分类,要求:划分训练集和测试集(测试集占20%)对测试集的预测类别标签和真实标签进行对比输出分类的准确率调整参数比较不同算法(ID3,C4.5,CART)的分类效果。2、把ID3算法修改为CART,并实现以下例子的分类。
机器学习实验:朴素贝叶斯算法实现对iris鸢尾花数据集的分类实验内容:通过sklearn提供的贝叶斯算法模型实现对iris鸢尾花数据集的分类及预测使用PCA降维,并通过matplotlib对决策边进行绘制代码如下:导入相关库import pandas as pdimport numpy as npimport matplotlib.colors as colorsimport matplotlib
