




- @m0_53062159
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
记录服务器部署Django项目的三种方法,由于项目没有用到数据库服务,所以部署过程不涉及数据库相关的连接和配置(后续使用到数据库再补充)

从以上实例中可以发现KNN算法的基本思路是将测试样本通过算法在训练样本中预测其类别,其预测精度受多方面因素的影响,例如训练数据的正确性和规模、算法的实现过程、参数值k的选取等等。KNN算法的识别过程相当于蛮力识别,因为每个测试向量都要对训练集里的每一个数据进行距离运算,实际运用时可以发现其执行效率并不高。但是KNN算法的实现思路较为清晰、易于理解,对刚接触图像识别的新手提供了一个清晰直观的思路,同
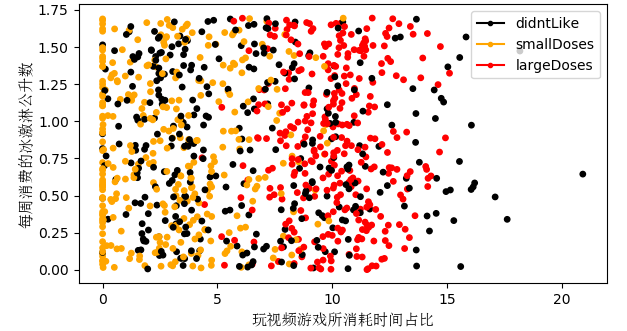
K-近邻算法(K-Nearest Neighbor),顾名思义,即选取最接近的数据进行分类的一种算法,它采用测量不同特征值之间的距离方法来进行分类。工作原理:存在一个样本数据集(训练样本集),并且样本集中的每一个数据都存在标签,即我们知道样本集中每一项数据与所属分类的对应关系,在输入没有标签的新数据时,将新数据的每个特征与样本集中数据对应的特征进行比较,最后根据算法提取样本集中最相似数据(最近邻)
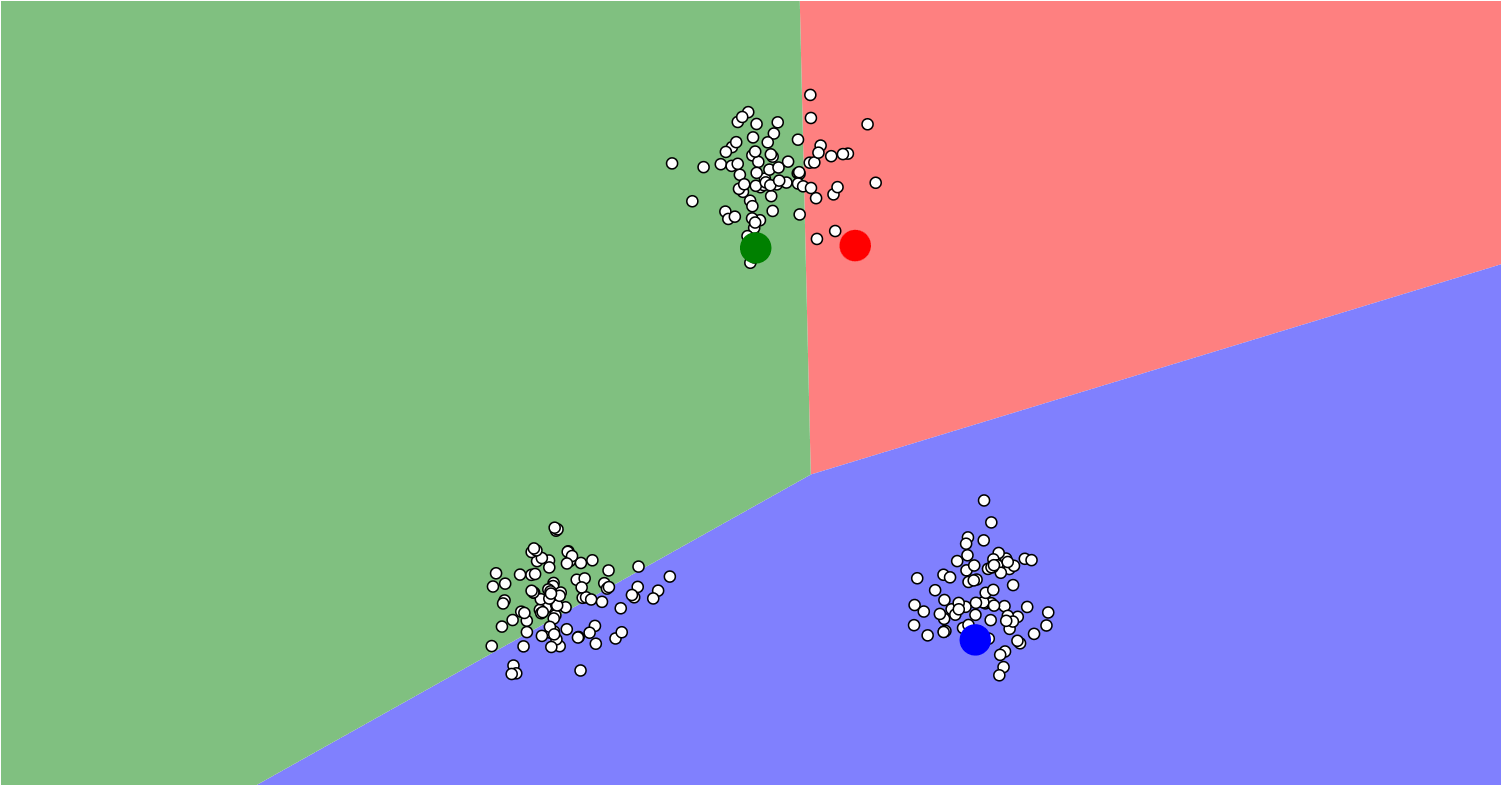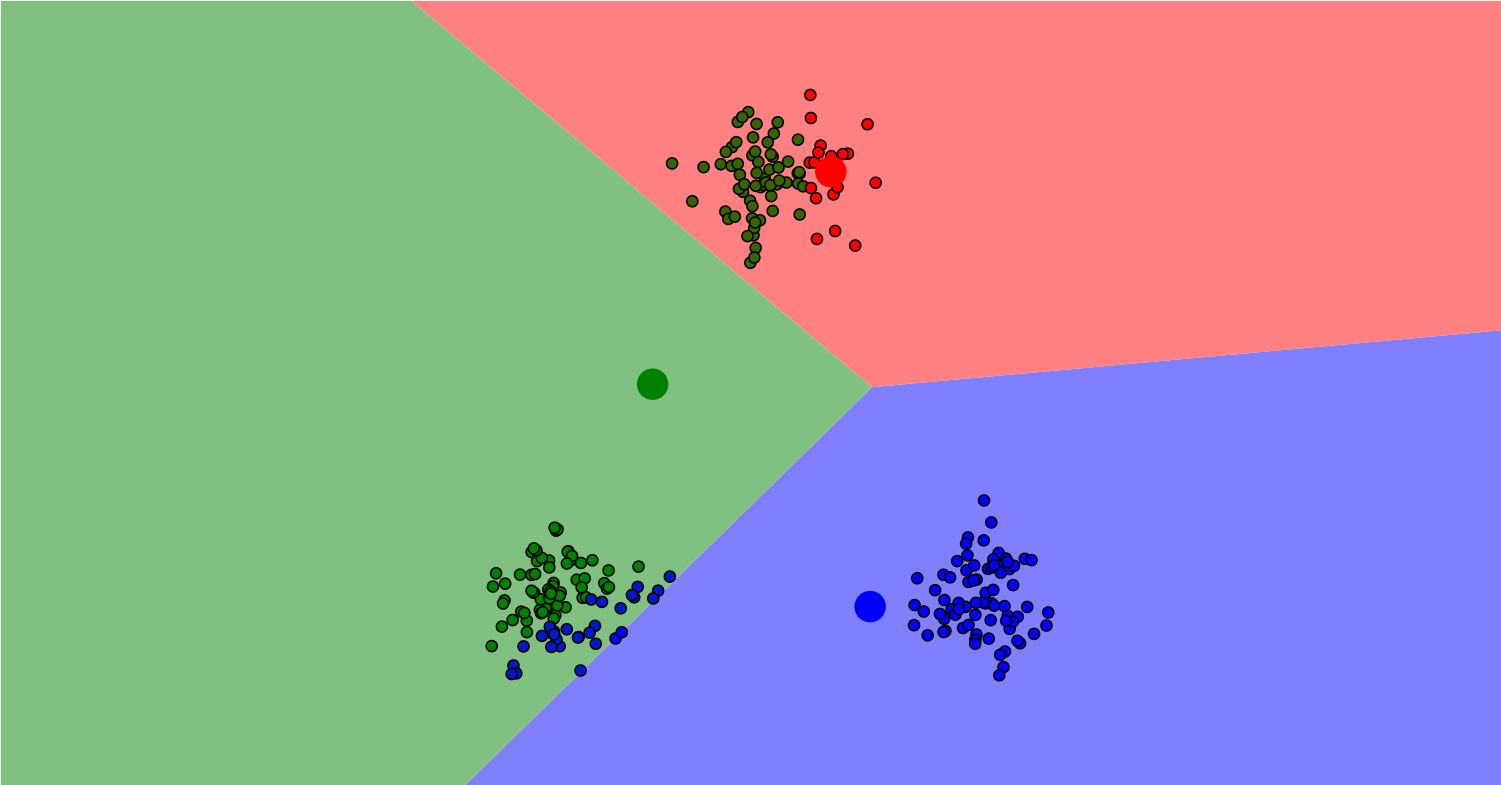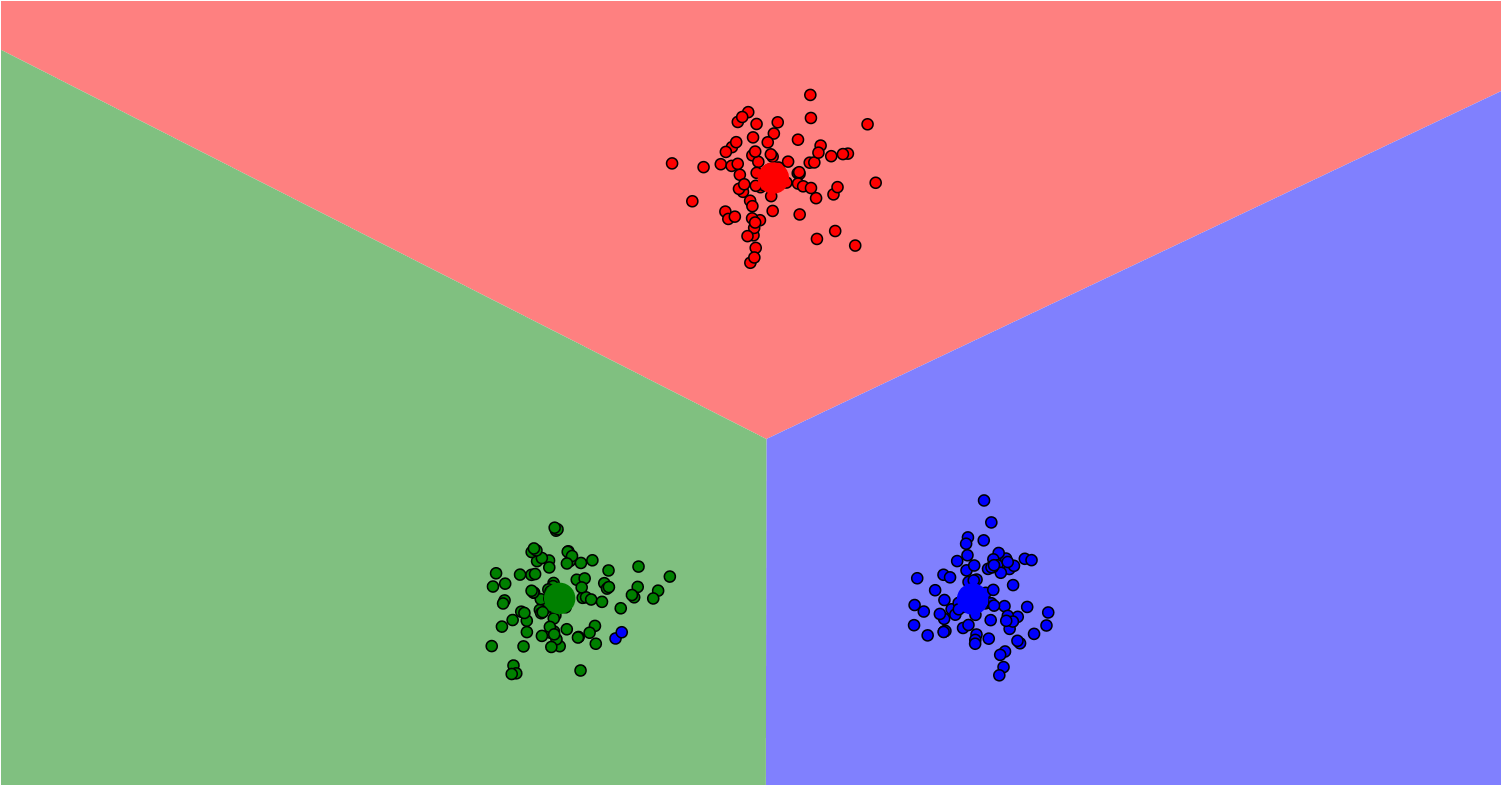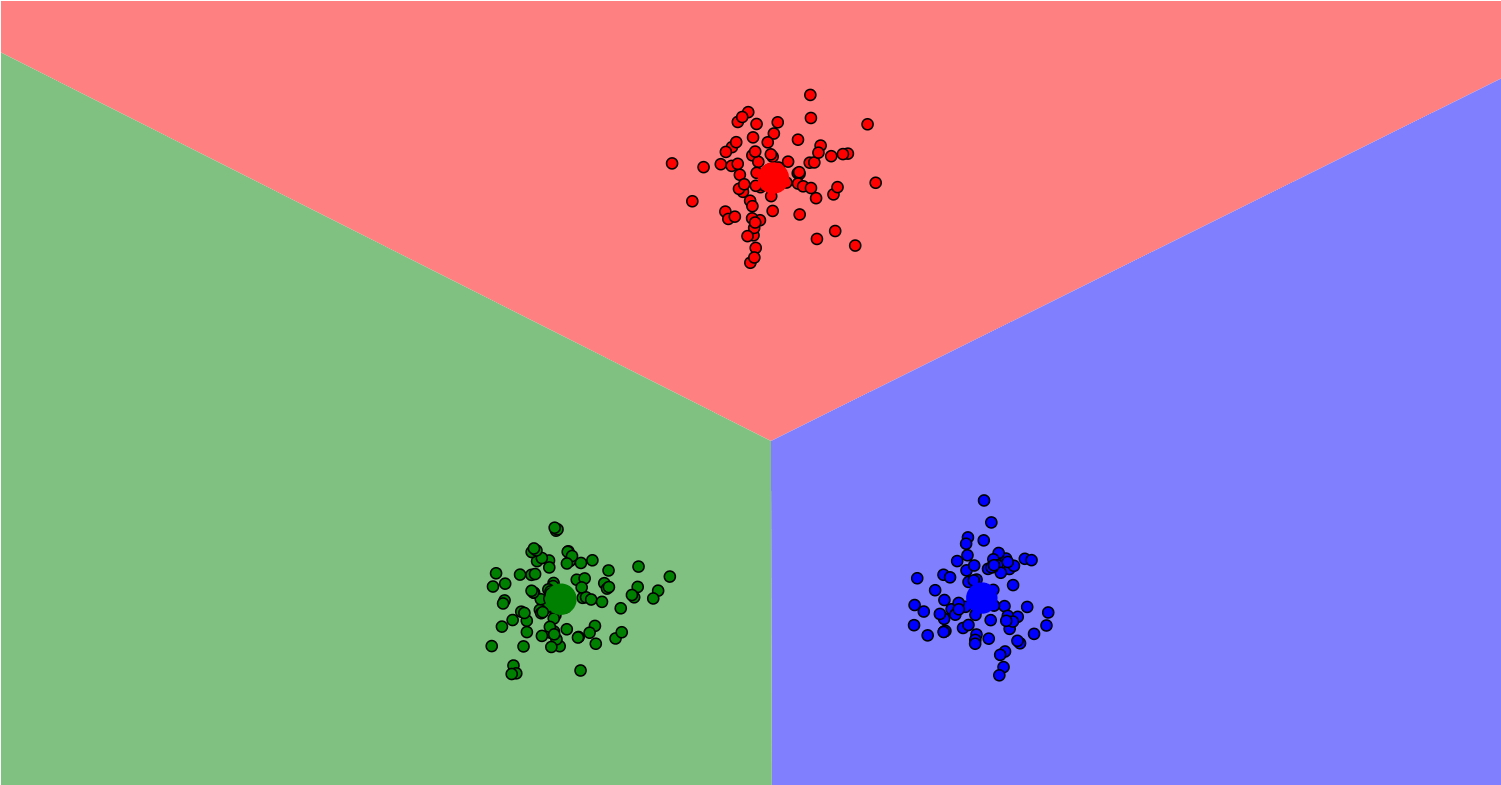
聚类算法是一种无监督学习方法,用于将数据集中的对象分组或聚集成具有相似特征的集合,该集合被称为簇(cluster)。聚类算法通过计算数据点之间的相似性或距离,将相似的数据点归为同一簇,使簇内差距最小化,簇间差距最大化,从而将数据集划分为多个互相区分的组。聚类算法的目标是在无标签的情况下,发现数据中的内在结构和模式。聚类算法可以发现数据中的隐藏模式、异常值或离群点,以及进行数据预处理和可视化。
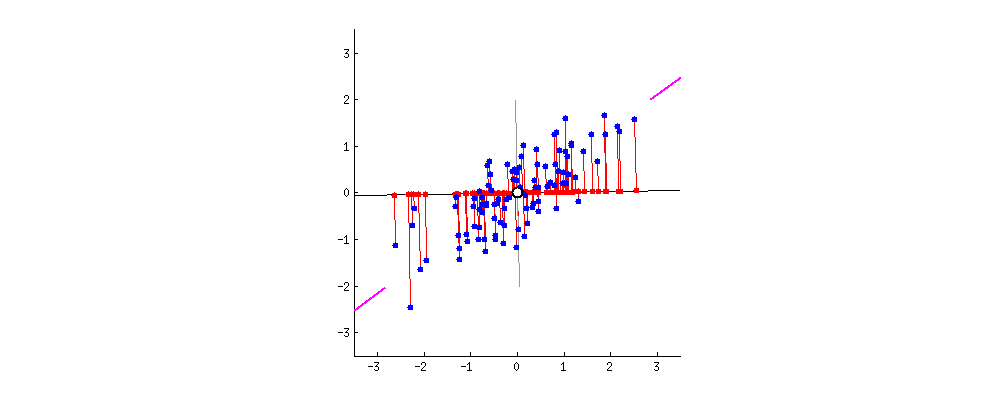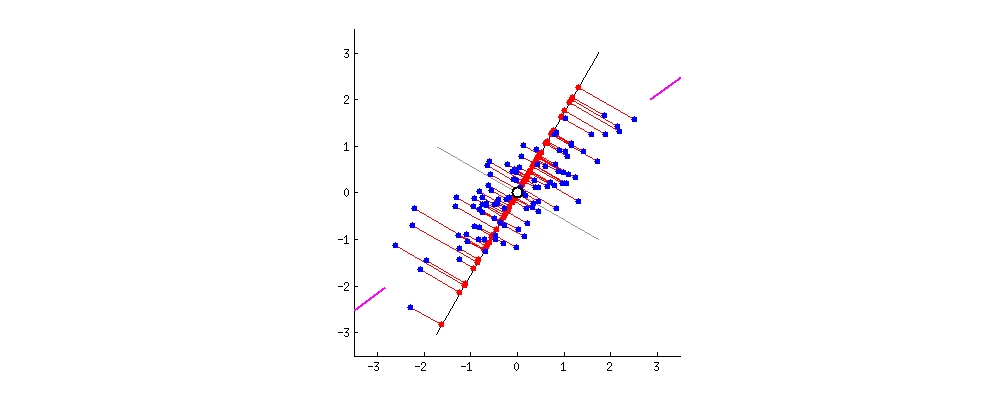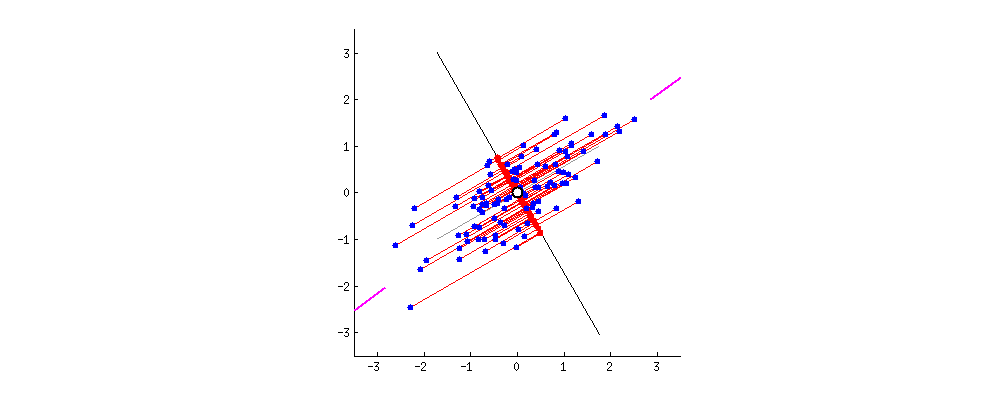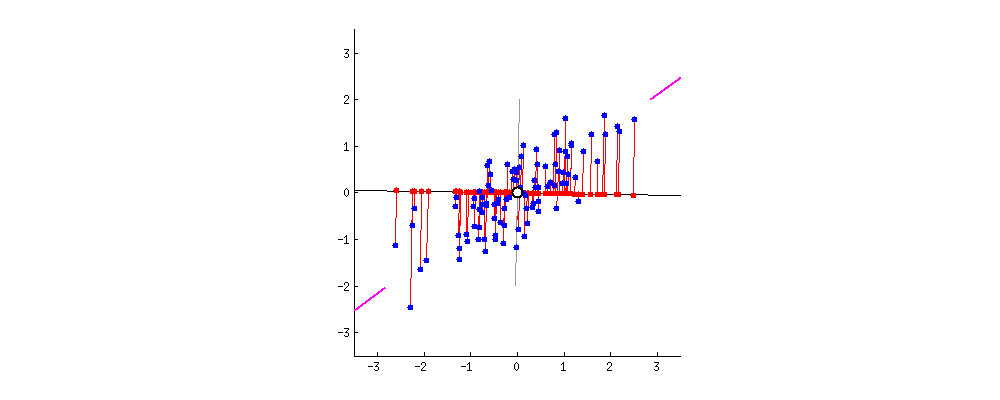
具体来说,第一主成分是数据中方差最大的特征(即该特征下的值的方差最大),数据点在该方向有最大的扩散性(即在该方向上包含的信息量最多)。第二主成分与第一主成分正交(即与第一主成分无关),并在所有可能正交方向中,选择方差次大的方向。然后,第三主成分与前两个主成分正交,且选择在其余所有可能正交方向中有最大方差的方向,以此类推,中,紫色线方向上数据的方差最大(该方向上点的分布最分散,包含了更多的信息量),
例如两个变量之间成正比(例如:x1 为房子的面积,单位是平方英尺;x2为房子的面积,单位是平方米;不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。的适用范围更广,可以用于描述非线性或者有两个及两个以上自变量的相关关系,它可以用来评价模型的效果。常用相关系数来衡量两个变量间的相关性,相关系数越大,相关性越高,使用直线拟合样本点时效果就越好。下图的样
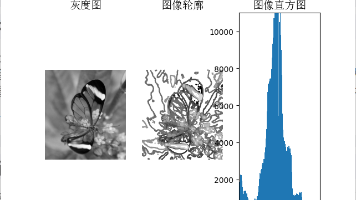
本文介绍了OpenCV的安装方法及常见问题处理,包括使用pip安装OpenCV、Pycharm中模块路径配置错误的解决方案。详细讲解了图像直方图原理及实现代码,展示了对灰度图和彩色图进行高斯滤波的效果对比,并探讨了不同标准差参数对滤波结果的影响。最后介绍了直方图均衡化的原理及Python代码实现,通过实际案例展示了均衡化前后图像及直方图的变化效果。文章包含完整代码示例和运行结果图示,适合图像处理初
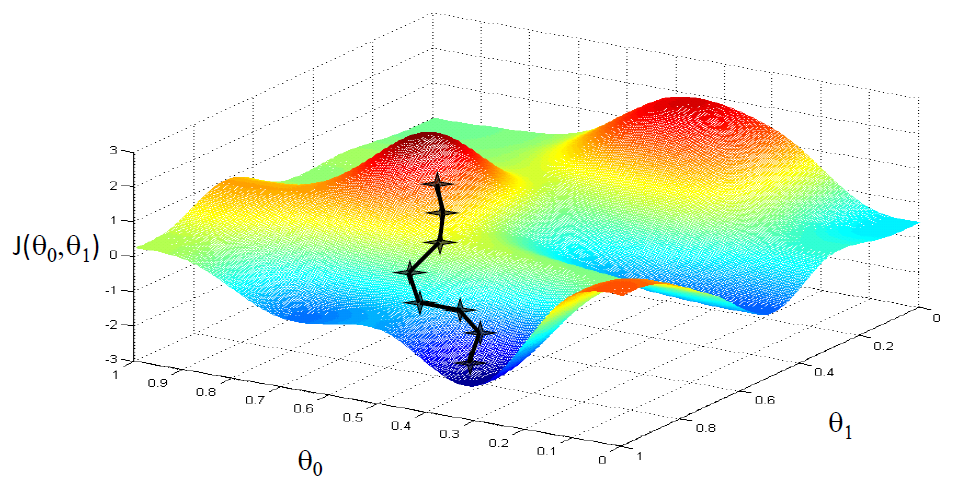
例如两个变量之间成正比(例如:x1 为房子的面积,单位是平方英尺;x2为房子的面积,单位是平方米;不可逆的情况很少发生,如果有这种情况,其解决问题的方法之一便是使用正则化以及岭回归等来求最小二乘法。的适用范围更广,可以用于描述非线性或者有两个及两个以上自变量的相关关系,它可以用来评价模型的效果。常用相关系数来衡量两个变量间的相关性,相关系数越大,相关性越高,使用直线拟合样本点时效果就越好。下图的样
竞赛的数据集中,训练集有7613个样本,测试集有3263个样本。训练集中的`target`用于标识推文是否属于灾难推文(1表示灾难推文,0表示非灾难推文),最终任务是判断测试集中的推文样本是否为灾难推文,评估指标是F1值。竞赛使用的模型是DistilBert,DIstilBERT是 transformers 库中的模型。提交代码后最终评分(F1值)为0.82071。

本次竞赛的数据集包含训练集和测试集,数据集的研究区域包含位于科罗拉多州北部罗斯福国家森林的四个荒野区域,这些区域受人为干扰影响最小,每个观测样本的区域大小为 30m x 30m。其中,训练集大小有15120个样本,测试集有565892个样本。共56个特征,7种类别(用数字1-7表示),第一列为样本`Id`列,最后一列`Cover_Type`为标签列。最终评分为0.78729。
