




- @weixin_41233157
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文基于PyTorch框架实现MNIST手写数字识别任务。主要步骤包括:1)使用DataLoader加载并预处理MNIST数据集;2)构建三层全连接神经网络模型;3)采用SGD优化器进行模型训练;4)评估模型性能并进行调优;5)保存模型并展示预测结果。实验结果表明该方法能有效识别手写数字,预测准确率较高。项目代码已开源在GitHub,包含完整的数据处理、模型训练和评估流程。
1. 随机森林RandomForestClassifier官方网址:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html1.1 原理解释从给定的训练集通过多次随机的可重复的采样得到多个 bootstrap 数据集。接着,对每个 bootstrap 数据集构造一棵决
利用python进行常见的数据预处理,主要是通过sklearn的preprocessing模块以及自写的方法来介绍加载包及导入数据# -*- coding:utf-8 -*-import mathimport numpy as npfrom sklearn import datasetsfrom sklearn import preprocessingiris = datasets.load_ir
数据测试与分析需要经常将用户的敏感信息加密,将原有的明文信息经过加密算法转换成不可读的字符串,从而达到加密的目的,常用的加密算法有MD5、SHA256、RSA等。1.MD5、SHA256都是哈希算法,python中都来自hashlib包,主要是将一段字符串通过一定的加密算法转换成另一种字符串,因具有不可逆的特点,从而保证了数据的安全。2.RSA是一种非对称加密算法,对极大整数做因数分解的难度决..
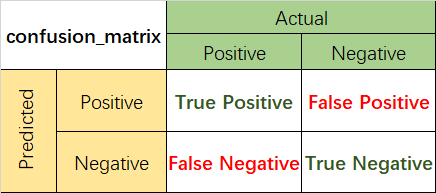
在使用机器学习算法解决一些分类问题的过程中,往往需要不同的模型评估指标,主要有一下三类指标:1.混淆矩阵相关1.1混淆矩阵混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。1.2准确率(Accuracy)准确率是最常用的分类性能指标。Accuracy = (TP+TN)/(TP+FN+FP+TN)即正确预测的正反
导出当前conda环境的所有包到一个environment.yml文件中,这个文件包含了conda环境中的所有依赖(包名和版本),包括Python包和非Python库,也可以用来完全恢复整个conda环境。训练好的模型通常需要在生产环境中部署和使用,一般导出为PMML(Predictive Model Markup Language)格式,以便在其他平台上使用,能够更加灵活地应用于各种场景。将当前

利用python进行常见的数据预处理,主要是通过sklearn的preprocessing模块以及自写的方法来介绍加载包及导入数据# -*- coding:utf-8 -*-import mathimport numpy as npfrom sklearn import datasetsfrom sklearn import preprocessingiris = datasets.load_ir
1. 随机森林RandomForestClassifier官方网址:https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html1.1 原理解释从给定的训练集通过多次随机的可重复的采样得到多个 bootstrap 数据集。接着,对每个 bootstrap 数据集构造一棵决
通过贝叶斯定理的理解,运用贝叶斯分类器处理分类问题
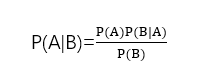
1.求group by之后和的占比先做group by分组汇总,再单独inner join连接到和,最后分组结果除以连接到的和selectifnull(hour_diff,'--合计--') hour_diff,count(1) cnt,count(1)/tot pctfrom(select timestampdiff(hour,createtime,activate_time) hour_dif