登录社区云,与社区用户共同成长
邀请您加入社区
如果你喜欢这种经典横版动作游戏,或者想探索更多被遗忘的宝藏,可以常去TopClaw网站(https://top.wokk.cn/)逛逛,那里不仅有最新版本的引擎更新日志,还有玩家们整理的WAD资源索引和汉化补丁,省去了很多在搜索引擎里大海捞针的时间。我第一次图省事,从某游戏论坛下了个“优化版”,结果桌面多了个弹窗广告,气得我直接重装了系统。Windows直接解压即玩。如果像我一样,压箱底的光盘早扔
拿到安装包之后,我特意看了一下目录结构,里面不仅有 OpenClaw 的主程序,还附带了一个 runtime 文件夹,里面塞满了各种 .so 文件、.dll 文件(Windows 下)、预编译的 Python 依赖 whl 包,甚至还有一个简易的 Conda 环境配置文件。
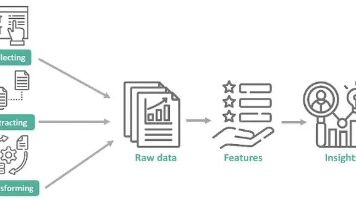
本文详解机器学习中至关重要的特征工程(Feature Engineering)全流程,涵盖EDA探索、缺失值处理(均值/众数/KNN填补)、类别编码(Label/One-Hot)、异常值检测(IQR/Winsorize)、特征缩放(Standard/MinMax/RobustScaler)、特征构造(日期解析、多项式、分箱)及特征选择(SelectKBest/RFE),并用Scikit-learn
抗拒不确定性不如接受不确定性,接受不确定性不如拥抱不确定性,拥抱不确定性不如制造不确定性。
但装上OpenClaw之后,它有一个“实时监控”功能,只要检测到某个驱动或服务挂掉了,就会自动尝试恢复,整个过程不到10秒,完全不影响手头工作。注意,一定要认准官网后缀是 .org 或带“官方”字样的链接,因为市面上已经有一些打着“免费OpenClaw”旗号的假网站,点进去全是广告。我家里用的是几百块的路由器,平时晚上刷视频经常缓冲,打开OpenClaw里的“TCP/IP优化”选项后,延迟确实降低
我们推出系列高端研修课程,涵盖生成式AI、大模型、多模态技术、数字孪生、嵌入式AI(含FPGA与Linux平台)、深度强化学习、迁移学习、边缘计算与边缘智能、量子计算、大数据建模与挖掘、知识图谱与大模型应用、深度学习与图神经网络,以及具身智能等十余个核心方向。无论是从事人工智能、嵌入式系统、数据分析还是前沿交叉研究的专业人员,都能找到契合自身发展的学习路径,为推动行业智能化升级夯实技术根基。在人工
发过户籍。
六维力控指机械手末端力传感器能够同时感知三个正交方向的力(Fx, Fy, Fz)和三个正交方向的力矩(Mx, My, Mz),实现空间六自由度的全量程力觉感知。很多康复机构、养生连锁采购理疗机器人后,设备利用率在第一个月达到峰值,随后逐月下滑,三个月左右进入“吃灰”状态。这篇笔记我们从技术角度把力控这件事彻底拆解——传感器选型、信号处理、控制算法、系统集成,以及它如何影响商业闭环。理疗机器人的技术
本文深入解析了scikit-learn中`fit_transform`方法及其在机器学习流水线(Pipeline)中的应用,详细介绍了数据预处理的三部曲(fit、transform、fit_transform)及其工程化实践。通过实际代码示例和最佳实践,帮助开发者构建健壮的预处理流程,避免数据泄露等常见陷阱,提升模型性能和开发效率。
机器学习入门涉及概念理解、工具实践与学习路径规划三大基础环节。其核心原理在于通过数据驱动建模实现预测与决策,技术价值体现在可复现性、开源生态支持及工程落地能力。当前主流学习者普遍关注Python机器学习库(如scikit-learn、mlxtend)的实操资源、权威作者配套代码与结构化笔记。然而,大量网络推荐内容存在信息断层、语言错配(如R/Python混淆)、链接失效或缺乏原始出处等问题,导致学
scikit-learn是Python机器学习最主流的工具库,其核心价值在于将算法工程化落地。理解其设计逻辑需从‘数据准备→特征工程→模型训练→评估调优→部署’这一端到端工作流出发,而非孤立记忆模块API。标准化(StandardScaler)、独热编码(OneHotEncoder)、Pipeline流水线等关键技术,本质是解决真实业务中特征量纲不一、类别变量不可计算、预处理与预测逻辑不一致等工程
scikit-learn 是 Python 机器学习工程落地的核心库,其设计哲学围绕‘统一接口’(fit/predict/transform)展开,本质是面向对象的标准化契约体系。理解这一原理,才能避免 NotFittedError、参数错位、评估失效等高频故障。技术价值在于提升开发确定性与 pipeline 可复现性;典型应用场景涵盖数据预处理(如 StandardScaler 与 Robust
ONNX(Open Neural Network Exchange)作为一种跨框架的开放式模型交换格式,其核心价值在于提供计算图层面的语义一致性与运行时可复现性。它通过标准化张量形状、数据类型、算子行为及缺失值传播规则,使不同技术栈(如scikit-learn特征工程与PyTorch神经网络)能在同一执行引擎(如ONNX Runtime或Triton)中协同工作。这种统一不仅降低MLOps中胶水代
用Scikit-learn跑通第一条ML Pipeline:从泰坦尼克号CSV出发,走完数据加载→特征工程→随机森林训练→评估全流程。20行代码理解"读数据→训练→评估"这个基本循环。
机器学习作为数据科学的核心技术,其核心价值在于从数据中自动发现规律并进行预测。其基本原理是通过算法学习数据特征与目标之间的映射关系,从而实现分类、回归等任务。在工程实践中,一个统一的、可复用的工具框架能极大提升开发效率与模型可靠性。scikit-learn正是这样一个基于Python的经典机器学习库,它通过设计哲学上的一致性API(如fit、predict、transform)降低了学习门槛,并通
机器学习作为人工智能的核心分支,旨在通过算法让计算机从数据中学习规律并做出预测。其核心原理在于通过训练数据拟合模型参数,从而实现对未知数据的泛化能力。这一技术价值在于能够自动化解决分类、回归、聚类等复杂问题,显著提升决策效率和准确性。在实际应用中,机器学习已广泛应用于金融风控、医疗诊断、推荐系统等场景。要实现高效的机器学习应用,一个统一、易用的工具库至关重要。scikit-learn作为Pytho
机器学习不是调包,而是理解数据、算法与工程约束的闭环过程。标准化(StandardScaler)为何必须先fit再transform?train_test_split中的random_state如何保障实验可复现?classification_report中的precision与recall怎样揭示模型真实能力?本文以scikit-learn内置的wine数据集为沙盘,聚焦特征量纲差异大、类别非线
机器学习入门的核心在于建立对数据、模型与评估的工程直觉,而非陷入数学推导或工具选择焦虑。本文围绕scikit-learn这一轻量级框架,以‘人造数据+可视化决策边界+混淆矩阵诊断’为路径,系统讲解从环境配置、数据生成、模型训练到超参数调优的完整闭环。强调‘参数物理意义’(如max_depth控制过拟合程度、C值反映模型固执度)和‘避坑清单’(如conda/pip混用导致的NumPy冲突、Jupyt
机器学习入门的核心不是理解抽象定义,而是建立‘输入数据→输出预测’的完整因果链。其底层原理源于统计建模思想——通过量化变量间关系实现泛化预测,技术价值在于以低认知负荷达成可复现、可调试、可业务对齐的建模能力。典型应用场景包括房价预测、销售预估、风险初筛等结构化数据分析任务。关键在于避开框架陷阱(如过早引入PyTorch)、直面真实裂缝(缺失值、编码歧义、过拟合),并依托scikit-learn和J
后续经过针对性的笔试集训,他顺利拿到了Offer,电话里激动的声音都在颤抖——原来好的就业服务,不只是简单的网申投递,更是为你量身定制的未来。很多学员看重我们的“签订协议,保障就业”,这其实不是为了给谁压力,而是一份沉甸甸的责任。看到辅导老师为了学员的一个面试复盘到深夜,只为帮他扣住每一个得分点,突然觉得,这份行业的温度,就藏在这“不辜负每一份信任”的坚持里。你有没有过这样的时刻——面对电脑上密密
分别计算x、y分母项:S_x=\sqrt{n\sum x^2-(\sum x)^2},S_y=\sqrt{n\sum y^2-(\sum y)^2};肘部法则粗筛:遍历K,inertia下降变缓拐点,圈出候选K区间(如K=2、3、4);数据挖掘 (DM):从海量数据通过算法挖掘隐藏规律,常用任务:回归、分类、聚类、关联规则,挖掘数据商业价值。分别计算:\sum x、\sum y、\sum xy
scikit-learn不是简单的Python机器学习库,而是一套严格定义的机器学习工程协议。它以统一的接口契约(fit/predict/score)、刚性预处理流水线(Pipeline)和可审计的模型评估机制为核心,将统计建模过程标准化、可调试化、可复现化。其设计本质是封装数学推导为可控API,要求输入满足明确数据契约(如X必须为二维数值矩阵),并强制训练与预测使用相同变换参数。这种范式极大降低
机器学习作为人工智能的核心技术,通过算法让计算机从数据中学习规律并做出预测。其核心原理包括监督学习、无监督学习和强化学习三大范式,涉及特征工程、模型训练和评估等关键环节。在实际应用中,Python凭借scikit-learn、TensorFlow等丰富的工具链,成为机器学习开发的首选语言。本文以线性回归、随机森林等经典算法为例,详解从数据预处理到模型部署的全流程实践,特别针对过拟合、特征工程等常见
机器学习作为人工智能的核心技术,其开发流程通常包含数据预处理、模型训练和性能评估等关键环节。Python凭借简洁的语法和丰富的库生态(如scikit-learn、pandas),成为机器学习领域的首选语言。通过conda环境管理工具可以有效解决依赖冲突问题,而Jupyter Notebook则提供了交互式开发体验。在实际项目中,遵循数据清洗的'三遍法则'和80-20时间分配原则能显著提升模型效果。
机器学习作为人工智能的核心技术,其实现过程往往涉及数据预处理、模型训练与评估等关键环节。Python凭借丰富的库生态系统(如scikit-learn)成为主流实现工具,其中Pipeline和ColumnTransformer等组件能有效构建可复用的数据处理流水线。在实际工程中,代码的可读性和模块化设计直接影响项目维护成本,而交叉验证、网格搜索等技术则保障模型性能。本文通过特征工程、模型调参等典型场
机器学习系统构建是数据科学项目的核心环节,涉及从数据预处理到模型部署的全流程。通过Python生态中的scikit-learn和TensorFlow等工具链,开发者可以实现特征工程、模型训练和性能优化的标准化流程。在生产环境中,合理的环境配置(如conda虚拟环境)和版本控制能确保实验可复现性,而特征存储和模型监控则保障了系统稳定性。以电商推荐系统为例,构建端到端的机器学习系统需要关注数据流水线设
机器学习作为人工智能的核心技术,通过算法让计算机从数据中学习规律并做出预测。其核心原理包括监督学习、无监督学习和强化学习三大范式,广泛应用于图像识别、自然语言处理、推荐系统等领域。Python凭借scikit-learn等强大的机器学习库,成为实现这些算法的首选语言。以经典的鸢尾花分类项目为例,完整展示了数据预处理、特征工程、模型训练与评估的标准化流程,其中KNN算法和决策树等基础模型的准确率评估
机器学习不是抽象知识的线性堆砌,而是一种以问题解决为驱动的认知实践。其核心原理在于将复杂模型简化为可解释、可调试、可部署的最小可行单元,通过即时反馈建立稳定的心智模型。技术价值体现在降低启动门槛、压缩认知熵、加速价值验证——尤其在算力普惠与低代码工具成熟的2026年,scikit-learn等成熟工具已成为承载‘机器学习思维’最友好的API接口。典型应用场景包括业务指标预测、工作流自动化、生活小问
机器学习入门的核心在于理解数据、模型与评估之间的基本关系。从特征工程到模型验证,从过拟合识别到算法公平性,这些基础能力往往依托于结构清晰、规模适中、语义明确的经典数据集。Iris、Wine、Breast Cancer、Digits和已弃用但原理重要的Boston Housing,构成了scikit-learn生态中最常用的教学与验证载体。它们支撑着数据探索、模型调参、可视化解释及部署验证等关键环节
机器学习中,高质量、可控、可复现的数据是构建可靠模型的基础前提。sklearn内置数据集(如Iris、Digits、Wine)本质上是一组经过工程化设计的标准化接口,其核心价值在于提供确定性输入、消除环境依赖、支持快速验证与教学闭环。它们覆盖分类、回归、图像、高维等典型任务类型,具备稳定统计特性、明确文档契约与零网络/零磁盘开销优势。相比Kaggle或UCI等外部数据源,这些数据集天然规避了缺失值
本文详细介绍了使用Python 3.12和scikit-learn 1.5进行机器学习实战的全过程,包括房价预测与分类任务。从环境配置、数据探索、特征工程到模型训练与评估,提供了完整的代码示例和实用技巧,帮助初学者快速掌握机器学习基础。
机器学习作为人工智能的核心技术,通过算法让计算机从数据中学习规律并做出预测。其基本原理是基于统计学习理论,通过特征工程、模型训练和优化迭代实现智能决策。在工程实践中,机器学习技术能够显著提升业务效率,广泛应用于电商推荐、金融风控、医疗诊断等工业场景。以Python为核心的技术栈,结合scikit-learn进行传统机器学习建模,TensorFlow处理深度学习任务,构成了完整的机器学习工作流。哥伦
Python在数据科学中并非以理论最优或性能第一见长,而是在‘从问题到可运行结果’的全链路中持续降低工程认知负荷。其核心价值源于pandas、numpy、scikit-learn等库对真实场景的长期磨损适配——自动处理BOM编码、混杂日期格式、缺失值语义(如pd.NA)、链式清洗与视图安全索引等设计,本质是将数百万从业者的踩坑经验沉淀为‘最小可行路径’。这种面向交付时效(如下午三点前发图表)、容忍
机器学习本质上是数据驱动的实验性工程,其核心挑战不在算法理论或计算性能,而在于快速验证假设、协作迭代与稳定交付。Python凭借统一的数据接口(如pandas DataFrame与PyTorch Tensor无缝转换)、一致的API范式(fit/predict/forward)和极低的调试延迟,显著降低认知负荷与团队协作成本。它不追求单点极致性能,而是通过成熟生态(scikit-learn、PyT
数据科学不是静态算法应用,而是涵盖数据探查、特征工程、模型训练、服务部署与持续监控的动态闭环。其核心挑战在于如何在不确定性中保障可复现性、协作一致性与生产稳定性。Python 凭借动态类型降低认知负荷、pandas 与 scikit-learn 的接口契约实现无缝流水线、PyTorch 的 autograd 提供可调试梯度流,构建了覆盖研究到上线的最小阻力路径。结合 Poetry 环境隔离、pan
机器学习作为人工智能的核心技术,通过算法让计算机从数据中学习规律。其核心原理是构建数学模型来自动识别模式并进行预测。在实际工程中,Python凭借简洁语法和丰富生态成为首选工具,特别是scikit-learn库提供了完整的机器学习工作流支持。典型应用场景包括客户流失预测、推荐系统等商业智能领域。本文以最新Python 3.11和scikit-learn 1.3.0环境为例,详解从数据清洗、特征工程
数据科学工具的本质是解决真实场景中的工程效率问题,而非堆砌技术名词。其核心原理在于匹配数据形态(如表格、时序、图像)与任务类型(如预测、归因、部署),并通过版本兼容性、API可维护性与环境一致性保障长期可演进。技术价值体现在降低协作成本、规避‘在我机器上能跑’陷阱、支撑模型从实验到生产的全生命周期。典型应用场景包括金融风控的特征稳定性监控、电商推荐的AB测试快速迭代、工业设备预测性维护的轻量化部署
scikit-learn
——scikit-learn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 智能体开发者社区
智能体开发者社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI编程社区
AI编程社区



 DAMO开发者矩阵
DAMO开发者矩阵



 AI Agent技术社区
AI Agent技术社区