




- @m0_73633807
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
腾讯云智能结构化OCR产品,是一款基于深度学习和大数据分析技术的智能OCR产品。其能够在复杂的文本格式和版式下,对文件中的关键信息进行识别,并将其转化为结构化数据。通过结合自然语言处理(NLP)、图像识别、多模态大模型技术等先进手段,腾讯云OCR能够高效、精准地提取各种文件中的关键信息。腾讯云智能结构化OCR产品提供基础与高级版本选项,具备全面的行业覆盖能力,能精确识别包括卡证、物流单据、工业标签

弗洛伊德算法(Floyd's algorithm),又称为弗洛伊德-沃尔什算法(Floyd-Warshall algorithm),是一种用于在加权图中找到所有顶点对之间最短路径的算法。这个算法适用于有向图和无向图,并且可以处理负权重边,但不能处理负权重循环。


深度优先搜索(Depth-First Search,简称DFS)是一种用于遍历或搜索树或图的算法。这种算法会尽可能深地搜索图的分支,直到找到目标节点或达到叶节点(没有子节点的节点),然后回溯到上一个分支继续搜索。

它是一种贪心算法,信息增益表示按某特征划分数据集前后信息熵的变化量,变化量越大,表示使用该特征划分的效果越好。:这个实现是为了教学目的而简化的,实际应用中通常会使用更高级的库和算法,如 scikit-learn 中的 DecisionTreeClassifier。C4.5是ID3的改进版,使用信息增益比替代信息增益作为特征选择标准,从而克服了ID3倾向于选择多值特征的缺点。

随机森林(Random Forest)是一种集成学习方法,它通过构建多个决策树来进行分类或回归预测。随机森林的核心思想是“集思广益”,即通过组合多个模型来提高预测的准确性和鲁棒性。

腾讯云智能结构化OCR产品,是一款基于深度学习和大数据分析技术的智能OCR产品。其能够在复杂的文本格式和版式下,对文件中的关键信息进行识别,并将其转化为结构化数据。通过结合自然语言处理(NLP)、图像识别、多模态大模型技术等先进手段,腾讯云OCR能够高效、精准地提取各种文件中的关键信息。腾讯云智能结构化OCR产品提供基础与高级版本选项,具备全面的行业覆盖能力,能精确识别包括卡证、物流单据、工业标签
好了,自此你就获得了满血版的DeepSeek,Cherry Studio也是在电脑桌面上有客户端,以后想用的时候,直接打开Cherry Studio就可以,实现随时随用,最重要的是不会有服务器繁忙,请稍后再试了。以上步骤为博主自己实践操作,若有错误以及不准确的地方,欢迎大家纠正。

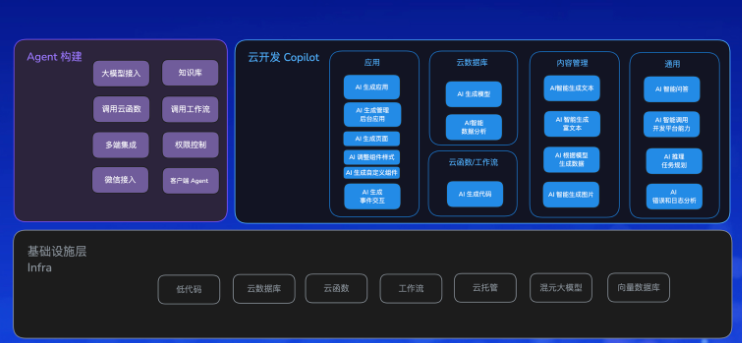
在云开发AI+中,腾讯云提供一系列与 AI 相关的功能,如大模型接入、 Agent 等,帮助开发者为自己的小程序、web 或者应用快速接入 AI 能力,同时也提供了云开发 Copilot,来加速用户的开发,帮助用户更快构建自己的应用。下面博主将会为大家实战使用云开发 Copilot来助力开发。云开发 Copilot是云开发推出的一款 AI 开发辅助工具,可以帮助用户快速生成多种类型的应用功能,包括
在算法竞赛中,博弈论算法常用于解决涉及对抗、策略选择、最优决策等问题。这类问题通常涉及两名或多名玩家在某种规则下的竞争,而每个玩家试图通过选择最优策略获胜。常见的博弈论问题类型包括零和博弈、格局游戏(如Nim博弈)、棋类游戏以及其他涉及策略选择的问题。
