登录社区云,与社区用户共同成长
邀请您加入社区
调用商用的agent api,比如qwen-embedding3等模型自己搭建。我这里选择的方式是第二种,通过ollama部署qwen3-embedding环境:Win10,ollama0.31.2,python,fastAPI。
定义:通过抑制低频信号(如平滑区域)并保留高频信号(如边缘、噪声)来增强图像细节的滤波方法。应用场景边缘检测(如车牌识别)医学影像增强(如X光片血管强化)纹理分析(如指纹识别)与低通滤波对比高斯模糊(低通)会平滑图像,而拉普拉斯锐化(高通)会突出边缘。技术对比算子计算速度精度适用场景Sobel快中等实时边缘检测Laplacian慢高精细锐化扩展方向:结合GAN实现超分辨率(如ESRGAN)。资源推
Python的跨技术栈支持:可操作Win32、WPF、UWP及浏览器等多种技术构建的界面元素底层技术优势:基于微软UI Automation API(比传统MSAA更现代)开发效率:Pythonic风格的API设计(对比C++实现的原始API)轻量级:无需额外部署服务,单包安装即可使用app = Application().connect(title="记事本")edit = uiautomati
4-4.Python 数据容器 - 字典 dict(字典 dict 概述、字典的定义与调用、字典的遍历、字典的常用方法)
4-3.Python 数据容器 - 集合 set(集合 set 概述、集合的定义、集合的遍历、集合的常用方法)
在CentOS7.8上成功安装VSCode和Python3.11的解决方案:针对系统版本过旧(glibc 2.17)导致新软件不兼容的问题,采取以下措施:1)Python3.11通过编译时强制链接OpenSSL1.1.1解决依赖问题;2)安装VSCode兼容版本1.80.2绕过glibc限制;3)配置Docker国内镜像源解决网络问题。关键思路是避免升级系统核心组件,而是通过版本选择和编译参数调整
字符串是python中不可变的数据类型。
本文介绍了Python语言的基础知识,包括其面向对象、解释型、开源等特点,并演示了环境搭建方法。通过PyCharm工具实现首个程序print("Hellow,lxj"),详细讲解输入输出函数print()与input()的用法,强调Python无需变量声明、缩进代替大括号等特殊语法。通过案例展示数字格式化输出(如%.2f)、字符串处理(%s)及分隔符(sep)、结尾符(end)
Python 作为当今最受欢迎的编程语言之一,以其简洁的语法和强大的功能吸引了无数初学者。无论你是想进入数据科学、Web 开发、自动化还是人工智能领域,Python 都是一个理想的起点。本指南将带你迈出 Python 编程的第一步。
本文详细介绍了如何利用 Bright Data Web Scraper API 结合 Python 技术栈高效抓取 Glassdoor 平台数据。从环境配置、API 认证到请求构建,再到数据解析与结构化输出,提供了完整的实战指南。文章重点探讨了反爬虫策略应对、数据清洗技巧以及如何将抓取结果转换为可分析的 CSV 和 JSON 格式,为人力资源分析、市场研究和竞品分析提供可靠的数据支持。
infra/compose: docker-compose 配置。→ 配置、启动逻辑(settings、logging)→ 异步任务、celery/apscheduler。backend/app/schemas: 数据模型。backend/app/services: 服务层。backend/app/core: 配置与启动。backend/app/routers: 路由。backend/app/ta
本文探讨了多Agent协作系统的核心架构挑战,重点分析了主Agent在任务分解、信息隔离和状态管理中的关键作用。文章对比了单Agent与主从架构的差异,指出多Agent系统的本质在于明确划分状态、上下文和权限边界。通过OpenAI Codex和Hermes等案例,阐释了任务隔离、独立环境和证据管理的重要性。提出ACP协议作为标准化连接方案,使主Agent能专注于任务编排而非底层实现。文章还提供了杭
要为自己的类实现多维下标运算符,我们需要在类定义中重载带有多个参数的operator[]。}};这样的实现允许我们直接使用来访问矩阵元素,代码更加清晰直观。多维下标运算符不仅限于二维,还可以支持任意维度的索引,只需要相应增加参数数量即可。
本文详细介绍了 DrissionPage 库在 Python 中的使用方法,涵盖安装配置、核心功能、动态网页处理、数据抓取实战及性能优化。通过具体代码示例,帮助开发者高效处理动态加载内容,提升自动化脚本的稳定性和效率。
当标准库提供的RAII包装器不能满足特定需求时,开发者可以自定义RAII类。一个良好的自定义RAII类应遵循单一职责原则,即只管理一种资源。其设计要点包括:在构造函数中获取资源并完成所有可能失败的操作;使用析构函数无条件地释放资源;通常禁用拷贝操作(或正确实现拷贝语义,如深拷贝或引用计数),以避免重复释放;并提供访问所管理资源的接口。通过自定义RAII类,可以将任何稀缺资源(如网络连接、图形设备上
通过精准的类型约束,显著提升了代码的健壮性和可读性。在Python 3.11中,其与模式匹配等新特性的结合,将进一步推动类型驱动开发范式的发展。作为类型提示的进阶特性,为复杂数据结构和特定值约束提供了优雅解决方案。随着Python类型系统的持续演进,类型提示已成为提升代码可读性和可维护性的核心工具。注:本文所有代码示例均通过mypy 1.5+静态检查,建议在Python 3.11+环境中验证执行。
本文深入解析Python JSON模块中的loads、load、dump和dumps四个核心函数,涵盖其基本用法、参数详解、性能对比以及实际应用场景。通过代码示例和最佳实践,帮助开发者高效处理JSON数据,避免常见错误,提升编程效率。
本文档整合了 Python 3.11 与 OpenVINO 在 Windows 系统下的完整配置流程、常用命令、模型下载与验证方法,适用于新手快速搭建环境并开展推理开发。
本文通过一个完整的实战案例,详细讲解如何使用Python和BeautifulSoup(BS4)库爬取商业数据。从环境搭建到数据解析,再到数据存储,一步步指导读者掌握网页爬取的核心技术。内容包括HTML结构分析、BS4选择器使用、反爬虫策略应对,以及数据清洗与导出。适合有一定Python基础的开发者学习,帮助快速上手商业数据采集项目。
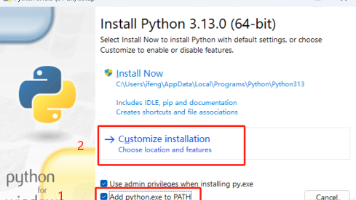
本文为 Python 3.11安装教程,详尽阐述了从下载 Python 3.11到完成安装的每一步操作流程,并分享了实用的安装技巧。作为最新正式版本,是一门强大且功能完备的通用型面向对象直译式计算机程序设计语言。它语法简洁清晰,具备高度的跨平台性,几乎能在所有操作系统上流畅运行,十分适合处理各类高层任务。并且,随着持续更新优化,它在独立大型项目开发中也日益发挥重要作用。
点击下面的下载链接,下载需要的版本。以3.13版本为例。输入python字母,如下图所示,就安装好了。下载完成后,双击安装文件。
通常就是代码编辑工具中显示的每一行。如果编辑器有自动换行(例如windows的记事本),需要将其关闭,否则代码会被编辑器重新换行,影响到源码的阅读。a=1b=2c=3print(a,b,c) // 这里一共5行代码,也是5个物理行obj={"a":1,"b":2} // 这里一共4行代码,也是4个物理行obj={"a":1,"b":2} // 这里python解释器,作为一个赋值语句解释,是一个逻
点击 “Browse”,选择一个。
Python 开发 - Python 装饰器(装饰器概述、函数概念、装饰器手动实现、装饰器语法糖实现)
Python 开发 - Python 中的 __name__(__name__ 概述、__name__ 的两种值、__name__ 的典型用法)
本文介绍了农业生产模型中的几种关键类型:PP(光温潜力产量)、FAO_WRSI10_WLP_CWB(水分限制产量)和Lintul10_NWLP_CWB_CNB(光能+水氮限制)。重点解析了WOFOST模型系列,包括7.2、7.3和8.1三个版本,涵盖潜在生产(PP)、水分限制(WLP)和水氮双重限制(NWLP)等模块。其中WOFOST 8.1功能最全面,支持多层水平衡(MLWB)和高级碳氮模块(S
摘要: Python 3.11 编译时若未正确链接 OpenSSL 会导致 pip 无法使用 HTTPS。本文提供了完整的解决方案,通过重新编译 Python 3.11.9 并显式指定 OpenSSL 3.0.13 路径来解决 SSL 模块缺失问题。关键步骤包括:清理旧编译、配置 OpenSSL 路径、验证模块生成、系统环境配置。文章包含自动化编译脚本和关键参数解释(--with-openssl、
Python Flask 开发 - Flask 路径参数类型(string、int、float、path、uuid)
Python Flask 开发问题:ImportError: cannot import name 'Markup' from 'flask'
Python Flask 开发问题:ImportError: cannot import name 'escape' from 'flask'
Python 开发 - type 函数(type 函数的基本使用、type 函数的返回值、type 函数与 isinstance 函数、type 函数元编程)
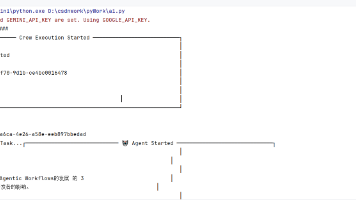
2026年AI玩法升级:告别2025年的"问答式"Prompt Engineering,转向更高效的Agentic Workflows(智能体工作流)。通过Google AI Studio和CrewAI框架,可组建多角色AI团队协作完成任务。文章提供详细教程:1)获取免费Gemini 2.0 Flash API密钥;2)搭建研究员和撰稿人协作流程;3)完整代码示例。关键优势:G
这是 Debian/Ubuntu 新版系统(Python3.11+)的,不允许直接在系统全局 Python 用pip安装包,防止破坏系统自带工具。下面给你三种稳妥方案,优先推荐虚拟环境。
本文详解 Windows 平台 Ollama 离线大模型部署,解决软件默认装 C 盘、模型缓存占用系统盘、局域网设备无法访问本地模型三大痛点。教程涵盖自定义安装路径、环境变量迁移模型目录、Modelfile 定制专属模型,实现多设备局域网共享本地模型。采用 Conda 虚拟环境部署 Open WebUI,隔离各类 Python 环境,规避依赖冲突问题。配套一键批处理脚本,自动分配大容量磁盘存储 W
DeepSeek V4 正式版 7 月中旬上线,同步引入峰谷定价,工作日 9-12、14-18 时段价格翻倍。本文结合炻光本地价格表交叉验证 V4-Pro / V4-Flash 两套定价,给出 4 条错峰省钱策略,帮开发者把 token 成本压回 5 月水平。
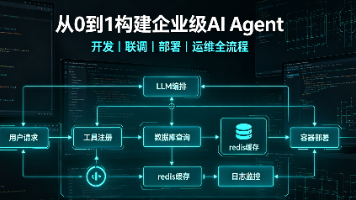
本文介绍了"智能运维助手"项目的全生命周期开发流程。项目基于Python 3.12+和FastAPI框架,采用异步架构设计,支持OpenAI和本地LLM模型接入。技术栈包含Pydantic配置管理、Docker容器化部署、GitHub Actions CI/CD流水线及Prometheus监控系统。项目结构清晰,包含配置管理、LLM客户端封装、工具注册等核心模块,通过pyproject.toml统
上个月接了 Claude 代码审查活,开 Extended Thinking 后检出率从 60% 拉到 90%。本文分享 thinking budget 各场景最优值,以及生产环境路由+监控的全套实践。
简洁明确的Prompt能减少模型"思考"token的消耗—## 总结Gemini 2.5 Pro的工程价值在于:把之前需要复杂RAG系统才能处理的长文档任务,简化成了直接输入。意味着你可以把整个代码仓库塞进去分析,可以把完整的法律合同包发给它审查,可以让它处理长达几小时的会议记录——而不需要复杂的分块和向量检索。### 原则三:长上下文的"丢失现象"处理研究发现,即使是支持百万token的模型,对
## 记忆的四个层次Agent的记忆体系可以分为四个层次,每一层的存储介质、访问速度、生命周期都不同:### 1. 上下文窗口记忆(In-Context Memory)这是最直接的记忆形式——把对话历史直接塞进提示词里。### 3. 语义检索记忆(Semantic/Vector Memory)对于长期积累的知识,需要用向量数据库实现语义检索——不是"最近的记忆",而是"最相关的记忆"。:只存储真正
本文介绍了Python面向对象编程的核心概念,包括类与对象的定义、类的组成、特殊方法和三大特性。主要内容包括: 类与对象基础:类作为蓝图定义类型,对象是类的具体实例。通过class关键字定义类,使用类名()创建对象。 类的组成:包含成员属性(在__init__方法中定义)和成员方法(带self参数)。介绍了__init__初始化方法和__str__字符串表示方法。 封装特性:通过双下划线__实现属
本文提供了Python编程环境的完整安装指南,适合零基础用户。教程包含三个核心步骤:1)从官网下载并安装Python解释器(强调必须勾选Add Python to PATH选项);2)安装免费的PyCharm Community版开发工具;3)创建并运行第一个Python程序。文章配有详细截图指引,涵盖Windows/Mac系统差异,并解答了常见安装问题(如PATH设置、解释器识别等)。成功完成安
python3.11
——python3.11
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区
 AI Agent技术社区
AI Agent技术社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区







 AI编程社区
AI编程社区











 龙虾开发者社区
龙虾开发者社区