登录社区云,与社区用户共同成长
邀请您加入社区
重新梳理llava的结构细节,从源码出发再次理解llava的核心原理。结合week08的简单实现,重构代码为更合理的结构,并在此过程中加深对llava模型的印象,补充一些细节上的知识点。
从单臂路由中理解VLAN!
【摘要】某企业部门从4人裁至1人,通过AI自动化处理重复性工作,实现高效运转。员工小陈将43项工作分类,34项固定套路工作交由AI处理,如新闻摘要、竞品报告和PPT制作。他采用分步实施策略:先解决最耗时的3项任务,每周节省8小时;随后串联各环节形成半自动流程。关键经验:1)保留人工审核环节;2)越忙越需搭建系统;3)从单点突破到流程串联。最终实现80%重复工作自动化,将周三工作时间从全天压缩至70
AI科研副驾驶”不是让医生失业,而是让医生从重复劳动中解放,回归思考与判断。当文献检索、数据清洗、统计分析、论文初稿等“搬砖”环节被AI接管,你的核心价值将真正聚焦于提出有临床深度的问题、设计有意义的研究、解读有温度的结果。科研提速300%的背后,不是跑得更快,而是把精力花在更有价值的地方。
本文总结了第16周训练的多模态大语言模型(MLLM)的整理与部署工作。原模型仅保存了project和LoRA参数,image encoder和LLM仍需加载官方权重,导致部署维护困难。本周通过将LoRA合并到基础LLM中,统一保存为Hugging Face标准格式model.safetensors,便于使用transformers库加载和vLLM服务部署。文章提供了模型转换脚本、配置定义及处理代码
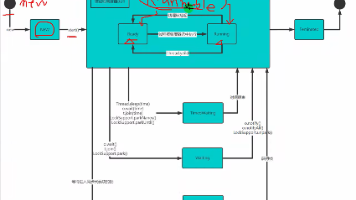
本文介绍了一个基于FastAPI和vLLM的多模态HTTP服务架构设计。服务采用分层设计:FastAPI负责业务逻辑(图片上传、限流、日志等),vLLM专注模型推理。主要特点包括:1) 通过请求队列控制并发;2) IP级限流;3) 图片预处理;4) 业务与模型解耦,支持独立扩展。服务提供/chat接口接收图片和问题,返回模型响应,并支持通过环境变量配置各项参数。这种分层架构提高了系统的可维护性和扩
道本科技总经理王智勇曾说,“传统意义上,企业提供给客户的价值是稳定的,但是在数字化时代,只有趋向数字化、智能化、个性化、便捷化、开放化才能更好地满足客户的需求。在未来,道本科技将紧跟国家发展战略,继续在“新基建”的引领下探索数字化发展之路,优化升级业务体系,更好的发挥人工智能、大数据等互联网技术优势,将新技术、新理念更好的融入企业法律事务管理发展之中,牢筑中国企业法律风险屏障,助推中国企业健康发展
本文实测金仓 KES MCP Server——把表结构查询、执行计划分析、健康检查、索引模拟等 9 个常用操作封装为标准工具,集成到 Cursor/Trae 等开发工具中。重点体验了 sys_hypo 零成本模拟索引功能,给出 Restricted 安全模式配置、日常巡检等实操建议。
RAG—文档解析——切片——入milvus向量库
摘要:本文详细介绍了二分查找算法的实现及优化。在有序数组中查找目标值时,通过设置左右指针i和j,计算中间值m进行比较。针对三个关键问题进行了分析:1)循环条件应为i<=j而非i<j,否则可能漏查边界值;2)处理大数组时使用无符号右移>>>计算m,避免整数溢出;3)改进代码可读性,统一使用小于号比较。文章提供了Java实现代码,并通过注释说明优化点,包括边界条件和中间值
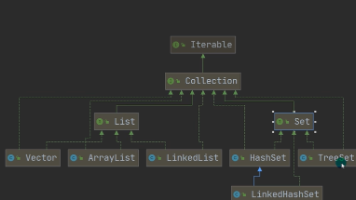
本文介绍了Java中Set接口及其主要实现类HashSet、LinkedHashSet和TreeSet的特性与底层机制。HashSet基于HashMap实现,通过hashCode和equals方法去重,具有动态扩容机制;LinkedHashSet继承HashSet,通过双向链表维护插入顺序;TreeSet基于TreeMap实现,通过Comparator或Comparable接口实现排序和去重。文章
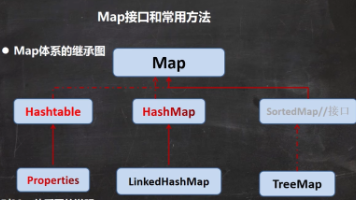
本文介绍了Java集合框架中的Map接口及其实现类。Map存储键值对,具有key不可重复、value可重复、允许null值等特点。重点分析了HashMap的底层机制(数组+链表+红黑树)和扩容规则(初始16,2倍扩容)。对比了Hashtable(线程安全、不允许null)与HashMap的区别,并介绍了Properties类(继承Hashtable,用于处理.properties配置文件)。最后给
摘要:泛型(参数化类型)用于约束数据类型,提高类型安全性和效率。语法包括声明(如class 类<K,V>)和实例化(如List<String>)。注意事项:泛型只能是引用类型;可传入子类类型;不指定类型时默认为Object。自定义泛型包括泛型类(成员可用泛型,数组不能初始化)和泛型方法(调用时确定类型)。继承方面,泛型不具备继承性,但可通过通配符<?>、<
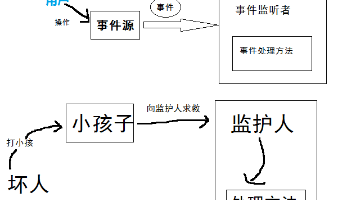
本文详解Java GUI的委派事件模型,重点剖析键盘监听实现。事件处理包含事件源、事件对象和事件监听器三要素,键盘监听通过实现`KeyListener`接口的`keyTyped`、`keyPressed`和`keyReleased`三个方法完成。通过键盘控制小球移动的完整实例,演示了方向键和WASD键的响应处理,涵盖焦点设置、边界检查等实战要点。文章还介绍了多键处理、`KeyBindings`替代
我们将探讨两种创建线程的方式(继承Thread类与实现Runnable接口),分析synchronized关键字的实现原理,研究互斥锁的工作机制,并学习如何避免常见的并发陷阱。多线程编程正是实现这一目标的关键技术,它不仅能提升程序的响应速度,还能优化资源利用,是现代软件开发中不可或缺的一环。我们将通过经典的"售票系统"案例展示线程同步的实际应用,通过"死锁"示例警示并发编程中的常见陷阱,并介绍线程
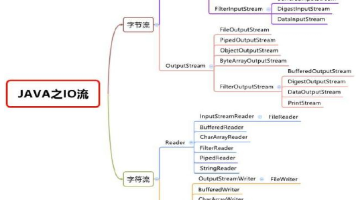
本文介绍了Java文件操作与IO流的基础知识。主要内容包括:1) 文件与文件流概念,文件在程序中以流的形式操作;2) 创建文件的三种方式及获取文件信息的方法;3) IO流原理与分类,包括节点流和处理流的区别及优势;4) 字节流操作,重点讲解InputStream及其常用子类的使用方法。通过代码示例演示了如何读取单个字节和多个字节,强调了资源关闭的重要性。全文系统性地讲解了Java文件IO的核心概念
连接池到底选 HikariCP 还是 Druid,参数怎么调。本文从零开始,先讲连接池原理(30秒理解),再分别给出 HikariCP 和 Druid 的 Maven 依赖、Java 原生配置、Spring Boot 配置,附核心参数详解和最大连接数计算公式。最后提供两者选型对照表,以及三种最常见的连接池报错(连接超时、Too many connections、链路断开)的排查与修复方案。跟着操作
用户 --(系统调用)--> 内核 --(驱动程序)--> 硬件版本类型历史规则(~2023年前)当前规则(2023年后)主版本结构变革时增加重大变化时增加(如6.x → 7.x次版本奇数=开发版,偶数=稳定版(如2.4稳定,2.5开发)不再区分开发/稳定,统一为新功能版修订号修复Bug时增加修复Bug时增加(保持不变)绝对路径:以 / 开始的路径相对路径:以当前为参照的路径(不以 / 开始的路径
更重要的是,履约数据会反馈回前面的环节:哪些条款在履约中经常出问题、哪些供应商承诺的和交付的不一致、哪些业务单元的合同执行偏差最大——这些信息会反向优化合同范本和审查重点。每一次审查中的审核意见——业务提了什么诉求、法务标注了什么风险、财务关注了什么成本——不再停留在邮件和批注里,而是被系统自动采集,沉淀为审查知识库的一部分。当合同被拆解成可计算的要素后,比对、审查、统计就有了统一的基础。道本科技
100 个 Java 程序员日常高频使用 的网站/工具,按「官方根站 → 学习教程 → 算法刷题 → 开源项目 → 工具/社区 → 资讯/博客」6 大类分层整理
json.loads() —— JSON 字符串【str】 → Python 对象【dict】父类定义:“通用流程框架和规范”,子类填充: “具体实现行为”。() 复用共性,通过重写方法实现个性——父类搭台,子类唱戏。子类通过重写,在父类授权的框架内,自主实现岗位专属行为。这个指的是要继承父类的功能,姓名,ID,但不是子类特有。💻 [小李] 上班第一件事,打开电脑,准备开始工作…💻 [小李]
目前华为在跨中心的大二层互访的网络中提供了3种解决方案,第1种就是端到端的VXLAN,就是011章节讲述的。本章节具体讲述的就是第2种跨中心的大二层解决方案,俗称最简单的跨数据中心的大二层解决方案。2023年XX市的XX分行要和XX县区的XXX支行实现大二层互联,两个分支机构之间通过长途专线互联,要求两个分支机构之间的网络互不影响。handoff vlan 的含义就是实现vxlan的终结,通过vl
知行学科技公司通过AI智能体培训助力企业数字化转型,构建了涵盖战略、战术、实战的课程体系,采用"理论+案例+实操"的培训模式。公司提供内训、公开课、公益课等多种形式,已为银行、保险、制造等行业定制AI应用方案。未来将结合生成式AI优化培训体验,拓展垂直领域深度,并布局国际化市场。知行学科技通过培训-合作-落地的闭环模式,正在推动AI智能体从概念走向产业应用,目标成为AI智能体创
C/C++中支持最基本的三种程序运行结构:顺序结构、选择结构、循环结构。
变量类型:基本类型(`int`, `float`, `char`)、自定义类型(`struct`, `class`)。// 动态分配内存(需 `delete ptr`)if (arr[i] > 0) { / ... / } // 分支可能降低性能。// 纯虚函数(抽象类)- 目标:实现一个基于事件驱动的HTTP服务器(如用`epoll`或`libevent`)。- 动态内存(堆):手动分配,需 `
三种构造更推荐第一种括号法,直观明了。
本文介绍了四道二叉树相关的算法题目:1. 单值二叉树:通过递归遍历整棵树,检查所有节点值是否与根节点相同;2. 相同树判断:递归比较两棵树的节点结构和值;3. 对称二叉树:使用相同树判断函数,交叉比较左右子树实现镜像对称检查;4. 子树判断:递归检查主树中是否存在与子树完全相同的结构。每个问题都给出递归解法,并通过示例图解析递归过程。四道题目层层递进,从基础遍历到复杂结构比较,展示了递归在树问题中
行为督促,坚持日更
当子类重写了父类的虚函数,子类中的虚函数表内部会被替换成子类的虚函数地址(&Cat::speak),父类没有发生改变,还是原来的。有一些属性开设在子类的堆区了,所以需要释放,但防止释放不干净,所以需要写虚析构或纯虚析构去走子类的析构函数,使之释干净,若不写,就是只走父类的析构函数。若写执行函数时,函数内调用的是父类的同名函数,这个时候不管传的参数是那个子类的对象,最终调用输出的函数始终是父类的函数
程序运行时产生的数据都属于临时数据,程序一旦运行结束就都会被释放,通过文件可以将数据持久化。参数解释:字符指针buffer指向内存种的一段存储康健,len是读写的字节数。注意:文件打开方式可以配合使用,利用|操作符。参数解释:字符指针buffer指向内存种的一段存储空间,len是读写的字节数。以二进制方式对文件进行读写操作,打开方式要添加一个ios::binary。二进制方式写文件主要利用流对象调
用户在批量创建时,可能会创建不同种类的职工,如果想将不同种类的员工都放入到一个数组中,因为一个数组中必须存放的是相同数据类型的数据,所以可以将所有员工的指针维护到一个数据里,如果在那个在程序中维护这个不定长的数据,可以将这个数组创建到堆区(指针),并利用Worker**的指针维护。先判断文件是否存在,若不存在,提醒用户,若存在,继续操作;判断职工是否存在,输入编号,按照编号查找,若不存在,提醒,若
这篇文章介绍了如何用React Hook Form和Zod优化React表单开发,解决传统受控组件性能问题。主要内容包括: 对比传统useState写法与RHF写法,展示代码量从50行缩减到10行 引入Zod实现校验逻辑与UI分离,通过schema定义校验规则 使用isDirty属性防止用户误关闭未保存的表单 强调RHF+Zod组合在性能、可维护性和开发体验上的优势 预告下期将探讨大数据量场景下的
本文介绍了Python列表的基本操作。列表用[]表示,元素间用逗号分隔。可以通过索引访问元素,支持负数索引访问末尾元素。常用操作包括:修改元素、添加元素(append/insert)、删除元素(del/pop/remove)。还介绍了排序方法(sort/sorted)、反转列表(reverse)和获取长度(len)。最后提醒注意索引从0开始,避免索引错误。列表是Python中灵活实用的数据结构。
本文介绍了Python中变量和简单数据类型的基本操作,包括字符串处理、数值运算和变量赋值等。主要内容涵盖:1)字符串的定义与引号使用规则;2)字符串大小写转换方法(title/upper/lower);3)f字符串格式化输出;4)字符串空白处理(strip/rstrip/lstrip);5)前缀/后缀删除方法;6)数值运算(包括乘方**);7)浮点数运算特性;8)多变量同时赋值;9)常量命名规范(
摘要:本文回顾了C++中const成员变量、引用类型成员、静态成员变量等初始化规则,强调const和引用成员必须通过初始化列表初始化,静态成员需在类外初始化。同时解析了static变量的存储特性及作用域规则,指出static成员函数无this指针。最后讨论了友元机制,说明友元函数可访问类的所有成员但不具备this指针。通过示例题目加深了对初始化顺序、静态成员和友元特性的理解。
摘要:本文介绍了C++内存划分及new/delete操作。内存分为栈区(自动管理)、堆区(手动管理)、全局/静态区、代码段和常量区。new/delete用于动态内存管理,会自动调用构造/析构函数,需注意匹配使用(new对应delete,new[]对应delete[])。通过选择题解析了常见错误,如栈/堆生长方向、内存碎片问题、静态分配限制等。重点强调:数组释放必须用delete[],否则可能引发内
本文介绍了Python中列表和元组的基本操作。主要内容包括:1) 使用for循环遍历列表的两种方式;2) range()函数创建数值序列及列表推导式;3) 列表切片操作和复制列表的正确方法;4) 元组的定义、访问和遍历。重点说明了列表与元组的区别,特别是元组的不可变性,以及如何正确复制列表以避免引用问题。文章还涉及简单的统计计算和代码格式规范,适合Python初学者了解基本数据结构操作。
#请创建一个列表,其中包含至少三个你想邀请的人,然后使用这个列表打印消息,邀请这些人都来与你共进晚餐。# # 4)缩短名单:你刚得知新购买的餐桌无法及时送达,因此只能邀请两位嘉宾,并使用pop不断删除名单中的嘉宾,# # 3) 添加嘉宾:你刚找到了一张更大的餐桌,可容纳更多的嘉宾就坐,请想想你还想邀请哪三位嘉宾,分别添加进。# print(f"{people.pop()},很抱歉,无法邀请您")#
摘要:本文系统回顾了C++模板的核心概念与应用。函数模板通过类型参数实现代码复用,强调类型推导规则和语法要点(如typename/class声明)。类模板作为参数化类蓝图,支持多参数和特化,需注意实例化规则。通过典型例题解析,指出常见误区:函数模板不支持隐式类型转换(B选项错误),类模板在运行时不会检查类型(C选项错误),模板类与普通类的编译处理不同(D选项错误)。正确模板声明需每个参数前加typ
本文介绍了Python中if语句的基本用法和结构。if语句用于根据条件执行不同代码块,其基本结构包括if、elif和else三个部分,其中elif和else是可选的。条件表达式可以使用比较运算符(==、>、<等)和逻辑运算符(and、or)组合。文章通过多个示例演示了if语句的应用场景,包括处理列表元素、判断列表是否为空以及使用in关键字进行成员资格判断。最后强调编程需要多实践,建议读
本文介绍了Python基础语法练习,包含多个编程任务:1)创建并打印披萨列表;2)使用for循环处理列表元素;3)数字范围操作(1-20、1-1000000);4)列表统计计算(min/max/sum);5)生成奇数和3的倍数;6)计算立方数;7)列表切片操作;8)列表复制与修改;9)元组基础操作及修改限制。通过这些练习帮助掌握Python基础语法和数据结构操作。
改行学it
——改行学it
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵

 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区

 AtomGit AI 社区
AtomGit AI 社区



 openEuler 社区
openEuler 社区

 DeepSeek技术社区
DeepSeek技术社区

 AI Agent技术社区
AI Agent技术社区


















