




- @2501_92003677
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文分极简、入门、初级三个层级详解语言大模型原理,从Transformer思考机制到Token向量化、多头自注意力机制,再到位置编码与概率计算,以“文字接龙”比喻大模型输出逻辑。今天跟大家聊一下大模型的底层原理,文章会分三个层级介绍语言大模型,从小白的极简角度,到入门,到初级逐渐深入。极简级上面是deepseek的对话界面,我们现在肯定都经常使用,当我们输入一段话给的deepseek之后,它是如何
当ChatGPT、文心一言等大型语言模型(LLMs)成为日常工具,我们既惊叹于它们流畅的表达能力,也常遭遇尴尬:询问最新政策时给出过时信息,解答专业问题时出现“一本正经的错误”,这便是传统语言模型的“知识瓶颈”——依赖训练数据的静态记忆,难以应对动态信息与专业场景的精准需求。为破解这一难题,检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。
本文主要讲了AI大模型应用的开发是怎么一回事、它的具体流程以及在不同应用场景中大模型是怎么发挥价值的。举了很多例子,也比较粗显地介绍知识问答场景和Copilot场景的原理和挑战。最后花了比较多的篇幅讲MCP,这是我们把大模型运用到实际工作中发挥价值的关键,且人人都可参与。开发框架(infra):目前处于百花齐放的状态,感兴趣可以去玩玩RAG(给大模型引入业务领域知识):RAG是把大模型和业务相结合
结合我自己的经历,给各位正在纠结选后端还是AI Agent的程序员小白、求职伙伴们,分享几点我的真实看法,仅供参考:\1. 后端领域:只要互联网行业还在,后端岗位的需求就不会减少,薪资也依然可观,但目前市场已经趋于饱和,竞争非常激烈,学习周期长、需要背诵大量八股,适合有耐心、能沉下心来长期深耕,且不排斥传统技术栈的伙伴。
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只
结合我自己的经历,给各位正在纠结选后端还是AI Agent的程序员小白、求职伙伴们,分享几点我的真实看法,仅供参考:\1. 后端领域:只要互联网行业还在,后端岗位的需求就不会减少,薪资也依然可观,但目前市场已经趋于饱和,竞争非常激烈,学习周期长、需要背诵大量八股,适合有耐心、能沉下心来长期深耕,且不排斥传统技术栈的伙伴。
本文详细介绍了AI编程工具从辅助到自主演进的四个阶段:AI作为打字员、提供新视角但需人工辅助、理解业务上下文的信任拐点,以及最终从编程到编排的转变。文章强调随着AI能力的提升,工程师的核心竞争力将从写代码转向编排AI工作流、设计Skill和推动AI友好的编程范式。Vibe Coding展现了AI编程的巨大潜力,但在复杂UI交互场景仍需人工干预。未来,工程师的价值更多体现在对业务的深度理解和AI能力
本文系统介绍了大语言模型应用中的关键技术概念:Agent(智能体)是基于LLM结合外部工具完成复杂任务的实体;FunctionCalling是让LLM生成结构化指令调用外部函数的机制;MCP是标准化模型与工具连接的协议;A2A则实现了不同Agent间的协作。文章通过天气查询示例展示了Agent工作流程,分析了各项技术的必要性及相互关系:FunctionCalling/MCP解决工具调用问题,而A2
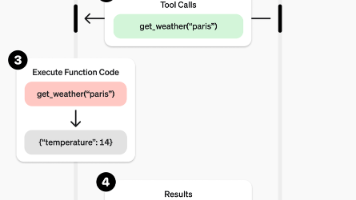
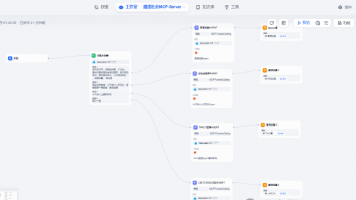
MCPServer是基于MCP协议构建的轻量级服务程序,旨在实现大型语言模型与外部资源的安全高效连接。本文介绍了MCPServer的客户端-服务器架构及其核心功能,包括资源暴露、会话管理、安全保护等。通过魔搭社区MCP广场,作者演示了如何配置高德地图等4个MCP-Server,并利用Dify平台搭建集吃饭、学习、看新闻、出行规划于一体的AI智能体工作流。虽然首次调用可能出现超时问题,但该方案展示了
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只