- @2501_92069919
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
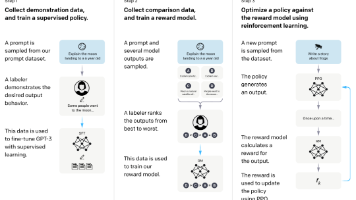
本文详细介绍了从零开始训练大语言模型的全过程,主要包括四个阶段:预训练、指令微调、奖励模型和强化学习。预训练阶段通过大规模无监督文本数据,让模型学习语言的基本规律和结构,为后续任务打下基础。指令微调阶段通过监督学习,使模型在特定任务上表现更优。奖励模型阶段通过人类反馈,评估模型输出质量,指导模型生成更符合人类偏好的内容。强化学习阶段结合人类反馈,进一步优化模型行为,使其输出更加自然和符合用户期望。
人工智能(AI)技术中的机器学习、深度学习和大模型是相互关联的概念。机器学习是获取模型的一种方法,而深度学习是机器学习的一个子集,专注于使用深度神经网络进行建模。大模型,如语言或图像大模型,通常基于深度学习技术构建。在实际应用中,大模型可以直接解决某些问题,但在其他情况下,可能需要调整模型参数或选择更适合的机器学习方法。重要的是,选择AI技术时应考虑其与业务需求的匹配度,而不是盲目追求大模型技术。
为了让大家把所学变成应用,“他”来了,一个零代码经验也可以搭建一个可用的大模型知识库,他来了,注意了,是零代码+可用,零代码+可用,零代码+可用......(重要的事情说三遍)通过学习能得到什么?可以得到一个简单的应用可以更深入了解大模型知识库的工作流大家有兴趣,可以跳到文末先看效果重要的工具我们先来看下今天这个小项目需要的概念和工具: Dify:Dify是一个开源的大语言模型(LLM)应用开发平

人工智能(AI)技术中的机器学习、深度学习和大模型是相互关联的概念。机器学习是获取模型的一种方法,而深度学习是机器学习的一个子集,专注于使用深度神经网络进行建模。大模型,如语言或图像大模型,通常基于深度学习技术构建。在实际应用中,大模型可以直接解决某些问题,但在其他情况下,可能需要调整模型参数或选择更适合的机器学习方法。重要的是,选择AI技术时应考虑其与业务需求的匹配度,而不是盲目追求大模型技术。
大型语言模型(LLM)是一种能够理解和生成人类语言的人工智能模型,通常包含数百亿参数,通过海量文本数据训练获得深层次语言理解能力。LLM能够执行多种任务,如回答问题、创作文本等。模型命名通常反映其架构、版本、参数规模或功能特性,如DeepSeek-V3、通义千问2.5-VL-32B等。LLM的核心概念包括Token(文本处理的最小单位)、参数(神经网络中的权重和偏置)、蒸馏(将大型模型压缩为小型模
人工智能(AI)技术中的机器学习、深度学习和大模型是相互关联的概念。机器学习是获取模型的一种方法,而深度学习是机器学习的一个子集,专注于使用深度神经网络进行建模。大模型,如语言或图像大模型,通常基于深度学习技术构建。在实际应用中,大模型可以直接解决某些问题,但在其他情况下,可能需要调整模型参数或选择更适合的机器学习方法。重要的是,选择AI技术时应考虑其与业务需求的匹配度,而不是盲目追求大模型技术。
本文概述了神经网络和深度学习的基本概念、历史及其应用。神经网络,受人类大脑结构启发,由互连的神经元组成,通过多层结构处理复杂的模式识别任务。深度学习作为神经网络的一个子集,利用多层网络处理大数据,广泛应用于图像识别、语音识别和自然语言处理等领域。文章还回顾了深度学习的发展历史,从1943年首次提出的人工神经元模型到现代复杂的网络架构,如卷积神经网络和循环神经网络,展示了深度学习在人工智能领域的重要
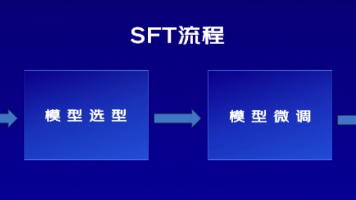
大模型微调技术中,监督微调(SFT)和Unsloth是两种常见方法。SFT通过在预训练模型基础上使用标注数据进行训练,使模型适应特定任务,提升性能和控制输出。其关键要素包括预训练模型、监督数据、损失函数、优化器和微调策略。Unsloth则是一个开源项目,专注于加速和优化大语言模型的微调和推理,通过FlashAttention、4bit量化、LoRA等技术实现高效微调,降低内存占用,并支持主流开源模
知识图谱在智能问答系统中扮演着关键角色,它通过有序整合海量知识,帮助大模型快速理解并精准回答用户问题。传统知识图谱构建依赖人工标注,存在效率低、主观性强和修正成本高等问题。KAG(知识增强生成)技术的引入,通过大模型的语言理解能力和逻辑推理,实现了全自动化的文本知识图谱抽取,显著提升了构建效率和准确性。KAG技术不仅将知识图谱构建周期从数周缩短至数天,还消除了人工标注的主观偏差,使得智能问答系统能
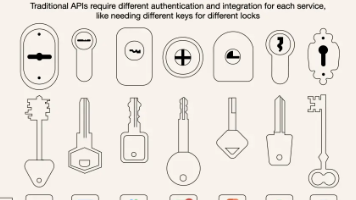
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的一种开放标准协议,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信方式。MCP的核心目标是解决AI应用开发中的数据孤岛和碎片化集成问题,提供一种标准化的方法,使AI模型能够与不同的数据源和工具无缝交互。MCP采用客户端-服务器架构,包含Host、Client和Serve