




- @A1063348628
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大模型开发,大模型微调,大模型部署,大模型推理,Linux,大模型GPU服务器部署,qwen3,显存的计算方法,模型的本地部署,rag,提示词工程,预训练,AI大模型应用开发工程师,AI,GPU,CPU,Python解释器,uvPython包管理器,虚拟环境。

文本分割是RAG流程中的关键步骤,主要解决长文档处理、检索质量和语义完整性问题。LangChain框架提供了专业化的文本分割工具,支持多种文档类型,通过chunk_size、chunk_overlap等参数控制分割粒度。分割后的文本块保留元数据,便于后续向量化和检索。合理分割能提升检索精度,避免信息丢失或冗余,是构建高效RAG系统的基础。

本文提出一个四步优化的大模型问答处理框架:首先对模糊问题进行上下文补全(指代消解/意图识别);然后根据复杂度拆分为子问题;接着通过多查询召回(同义改写/多视角扩展)增强检索覆盖;最后基于向量检索的Few-shot样例指导答案生成。流程采用动态策略,包含子问题依赖管理、冗余合并等优化,能有效处理多跳查询和模糊指代问题。该方案通过"补全-拆分-扩展-生成"的协同机制,显著提升复杂问

摘要:人工智能发展经历了符号主义、专家系统、机器学习到深度学习的演进过程。2017年Transformer架构的提出成为重大转折点,催生了当今的大语言模型时代。大模型具有参数规模大、训练数据量大、算力需求高等特征,通过预训练、微调和强化学习三个阶段获得能力。当前大模型已广泛应用于各行业,但仍面临幻觉问题、高能耗等挑战。未来发展方向包括推理能力突破、多模态融合、智能体普及等。理解大模型的关键在于认识

摘要:Transformer架构是当前大语言模型(LLM)的核心基础,由Google团队在2017年提出,取代了传统的循环神经网络(RNN)。其核心创新在于:1)完全基于注意力机制,实现全局依赖捕捉;2)支持全并行计算,大幅提升训练效率;3)采用多头注意力设计,可同时建模不同维度的语义关联。原始Transformer采用编码器-解码器双塔结构,通过自注意力、前馈网络等模块堆叠实现序列建模。现代大模
传统机器学习与大语言模型(LLM)存在本质差异:传统ML是"专项智能",依赖少量标注数据,模型简单(如决策树),针对特定任务(如图像识别);而LLM是"通用智能",通过海量无监督文本学习,采用复杂Transformer架构(如GPT-4万亿参数),具备语言理解、生成、推理等综合能力。核心区别在于LLM能跨领域应用(聊天、写作、编程等),采用生成式推理,但可解

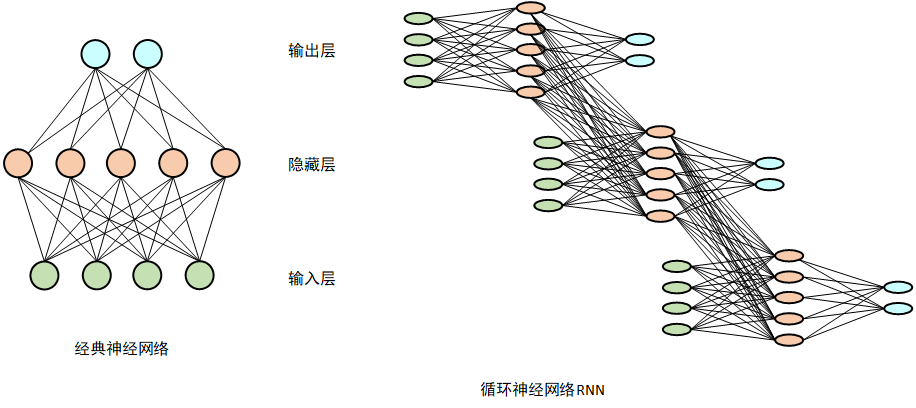
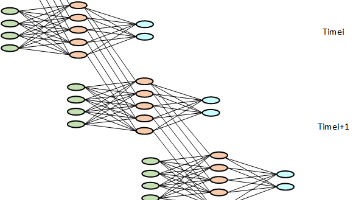
摘要:本文系统阐述了循环神经网络(RNN)处理文本数据的完整流程。首先介绍了文本向量化的三个关键步骤:Token化、词汇表映射和嵌入层转换,将文字转化为数值向量。其次详细解析了RNN的核心运算机制,包括隐藏状态的循环更新和参数共享原理。然后说明了RNN输出向量的两种应用场景:文本分类和生成任务。最后总结了从概率向量还原文字的反向映射过程。文章通过PyTorch代码示例,完整展示了从"我爱
大模型开发,大模型微调,大模型部署,大模型推理,Linux,大模型GPU服务器部署,qwen3,显存的计算方法,模型的本地部署,rag,提示词工程,预训练,AI大模型应用开发工程师,AI,GPU,CPU,Python解释器,uvPython包管理器,虚拟环境。
大模型开发,大模型微调,大模型部署,大模型推理,Linux,大模型GPU服务器部署,qwen3,显存的计算方法,模型的本地部署,rag,提示词工程,预训练,AI大模型应用开发工程师,AI,GPU,CPU,Python解释器,uvPython包管理器,虚拟环境。
本文系统介绍了API开发的核心知识与实践。首先解析了API的基础概念和类型(REST、GraphQL等),重点阐述了REST API的设计原则。接着详细讲解了HTTP请求/响应格式、API设计规范与最佳实践,包括URL路径、请求响应设计和数据验证。通过FastAPI框架的代码示例,演示了GET、POST、PUT、DELETE等操作的实现过程,并解决了CORS跨域问题。最后提供了API文档自动生成方
