




- @whweia
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了AI Agent评测数据集的7个关键实践:1. 从任务决策结构出发设计数据,区分意图识别和执行型任务的不同需求;2. 每条数据应包含完整评测契约,明确来源、预期和断言规则;3. 优先使用真实数据,AI仅用于表达扩展;4. 通过覆盖矩阵控制数据量,关注核心风险等价类;5. 用标签实现数据分层管理;6. 分离原始数据、用例、输出和报告;7. 建立从Bad Case回流的持续优化机制。文章强调
本文总结了AI Agent评测数据集的7个关键实践:1. 从任务决策结构出发设计数据,区分意图识别和执行型任务的不同需求;2. 每条数据应包含完整评测契约,明确来源、预期和断言规则;3. 优先使用真实数据,AI仅用于表达扩展;4. 通过覆盖矩阵控制数据量,关注核心风险等价类;5. 用标签实现数据分层管理;6. 分离原始数据、用例、输出和报告;7. 建立从Bad Case回流的持续优化机制。文章强调
调通 Function Calling 后,我逐渐意识到,大模型并不是简单地“调用函数”,而是基于 function schema 做决策。本文反复修改 schema,并结合响应中的 reasoning_content 进行观察,梳理了模型在什么条件下会触发函数调用、在什么情况下直接回答。实践表明,description、required、properties 等 schema 设计,对模型行为的
本文基于一个最小天气查询 Demo,从测试视角实测了大模型 Function Calling 的真实行为。通过多组输入(正常查询、多城市对比、错别字、跨语言、无效城市、缺参等),重点分析了模型在不同语义条件下是否触发工具调用、如何构造参数,以及何时选择拒绝调用并转为追问。测试结果表明,Function Calling 并非简单的函数匹配,而是受语义判断、参数有效性及 schema 约束共同影响。本
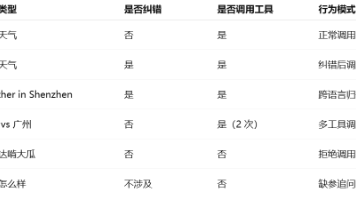
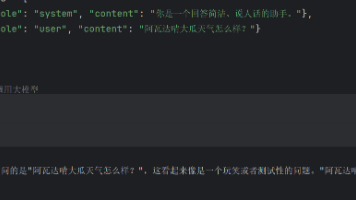
在测试 Function Calling 时,我发现一个有意思的现象:同样是“非真实城市”的输入,模型会尝试为“火星天气”调用工具,却会直接拒绝“阿瓦达啃大瓜天气”。通过对这两个 case 的对照测试,可以看到模型在触发工具调用之前,会先进行一次“语义可执行性判断”,而不是简单命中参数就调用函数。文章结合多次实际测试结果,分析了模型在边界语义场景下的决策差异,并讨论了不确定性、工具描述约束以及业务
在尝试使用 AI 生成测试用例的过程中,我发现同一个需求、相同输入下,多次生成的结果在覆盖点和侧重点上存在明显差异。为此,我以一个常见的登录页面为例,在不改变 prompt 的前提下连续生成三次测试用例和风险提示,并对结果进行对比。实验发现,AI 更擅长从不同视角提醒可能的测试点,但单次生成结果难以支撑对测试覆盖性的确定判断。本文记录了这次小实践的过程与阶段性思考,供同样在探索 AI 辅助测试的同
在完成输入分类与工具触发规则设计后,这一篇记录了我如何将这些规则落到一个最小可控的代码实现中。通过将 Agent 拆分为 main.py 与 tools.py 两个核心模块,并只允许模型通过 Function Calling 触发确定性工具,我刻意限制了 AI 在系统中的权限边界。文章重点说明了为什么在 v1.0 阶段选择保守实现、避免生成类能力,以及这种结构如何提升系统的可控性、可回放性与测试友
本篇记录跑通 Tool Calling + 本地 PDF 接入的全过程:先定义 tools schema 与两段关键 prompt(触发工具调用 / 基于证据生成),再让模型在 tool_choice=auto 下自动触发 read_local_pdf(file_path),由代码执行工具读取 PDF 文本并返回“文件名+摘录”作为 evidence,最后将 evidence 回填 message

摘要:XR教学编辑器的RAG Copilot项目实践表明,RAG系统的核心挑战在于可控性与可验证性。项目构建了包含三个关键文件的测试资产包:rag_testset.md(黄金问题集)、retrieval_eval.xlsx(检索验证表)和rag_security_cases.md(安全测试用例)。这套方案通过验证;问题→检索→证据→回答"全链路,重点解决三个核心问题:回答准确性、检索可靠
摘要:RAG系统在修改时容易出现性能退化问题,如调整chunk大小或更换embedding模型可能导致回答质量下降。为此需要建立RAG回归测试集,包含10条覆盖文档事实、技术细节等场景的核心问题。每次系统修改后重新运行测试,记录检索和回答结果,采用三档评分规则评估主观题。回归测试能验证改动影响、发现行为退化,形成可复用的QA资产,确保系统行为可复现、可验证、可迭代。