
什么是RAG(检索增强生成模型)技术,大模型入门到精通,收藏这篇就足够了!
RAG(Retrieval-Augmented Generator)是一种将“检索”(retrieval)和“生成”(generation)结合在一起的模型框架。
一、概述
RAG(Retrieval-Augmented Generator)是一种将“检索”(retrieval)和“生成”(generation)结合在一起的模型框架。主要核心思想是:再需要回答问题或者生成文本时, 除了让模型自己生成答案外,会先从外部的知识库中检索相关的信息,并将检索到的内容作为额外的输入,辅助生成更准确、可证据化的结果。
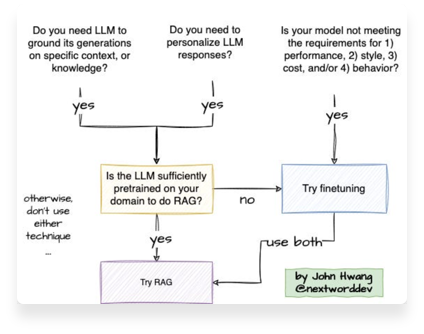
二、为什么要用RAG?
1、纯粹的生成模型(如标准的语言模型)在回答设计特定事实问题时,容易出现幻觉(hallucination),也就是给出不准确或未经证实的回答。
2、通过引入外部知识源,生成模型可以:
- 提高答案的准确性和覆盖面;
- 给出可验证的证据(来自检索的原文片段、链接等);
- 更容易进行知识更新,只需要更新检索源,而不必重新训练整个模型
三、核心原理

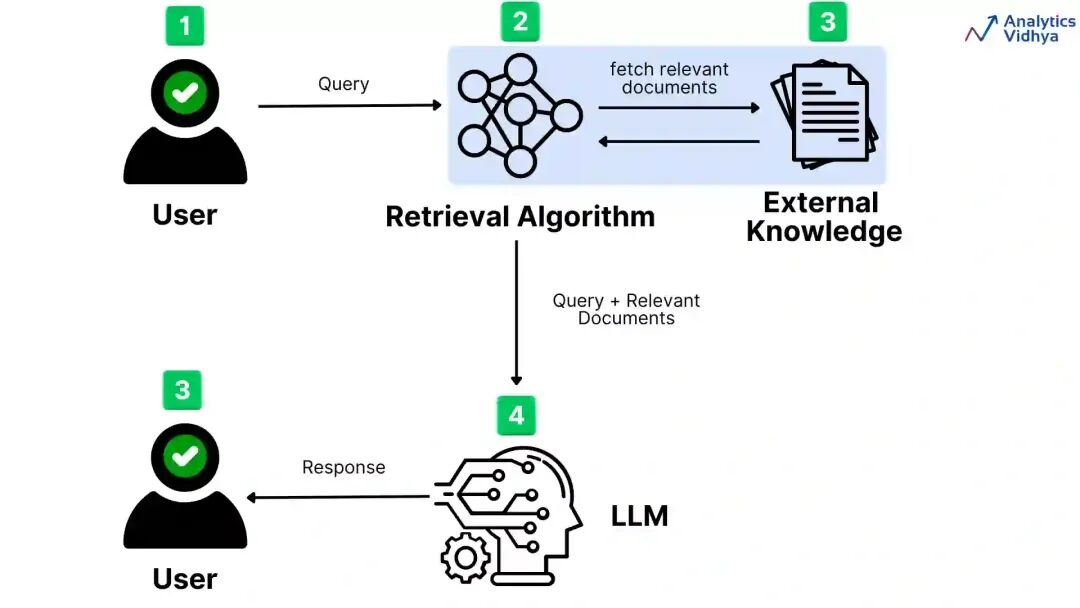
四、系统架构设计
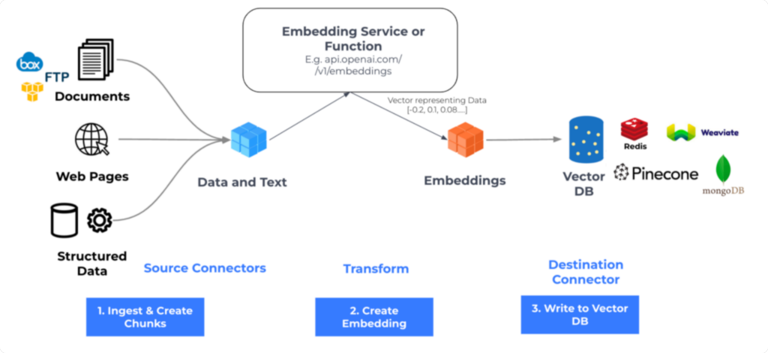
- 数据预处理:数据清洗、分块与标准化
- 向量存储:高效索引与检索数据库(向量数据库)
- 检索引擎:语义匹配与相关系排序
- 生成模型:上下文融合与回答生成
- 监控与日志:性能追踪与质量评估
五、搜索策略
1、ANN(Approximate Nearest Neighbor Search)近似近邻搜索
近似近邻(ANN)以记录向量嵌入排序的索引文件为基础,依据输入的搜索引擎请求中携带的查询向量查找向量嵌入子集,将查询向量与子集中的 向量进行比较,然后返回最相似的结果。
2、过滤搜索
由于ANN搜索是查找最相似的向量,所以搜索结果不一定总是正确的;因此需要在搜索请求中包含过滤条件,向量数据库(需支持条件过滤)在进行ANN搜索前进行多元数据过滤,将整个搜索范围缩小到只搜索符合指定过滤条件的实体。
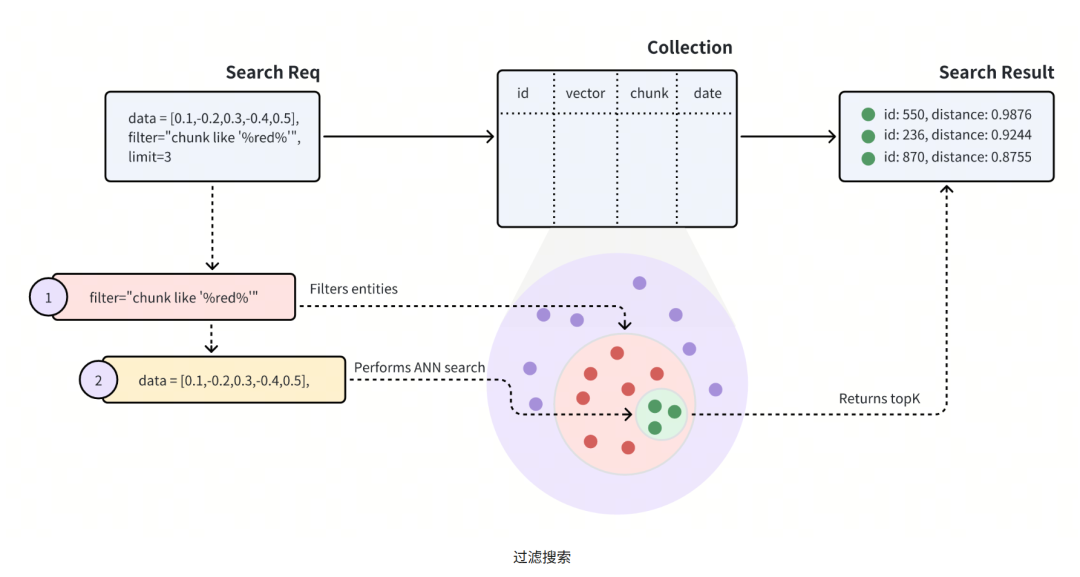
如图中所示,搜索请求中携带了过滤条件:chunk like % red %,表明应在chunk字段中包含red的所有实体进行ANN搜索。具体的过滤条件操作符可以查看具体向量数据库对应的手册。
3、BM25(Full-text Search)全文搜索
BM25全文搜索是一种基于信息检索模型的得分函数,用于在一个文档集合中对文档与查询的相关性排名,这在RAG场景中尤为重要,它能优先处理与特定搜索词密切匹配的文档。BM25属于Bag-of-Words模型的改进,考虑词频、文档长度与查询词的重要性。
以Milvus向量数据库为例,全文搜索只在 Milvus Standalone 和 Milvus Distributed 中可用,但在 Milvus Lite 中不可用。
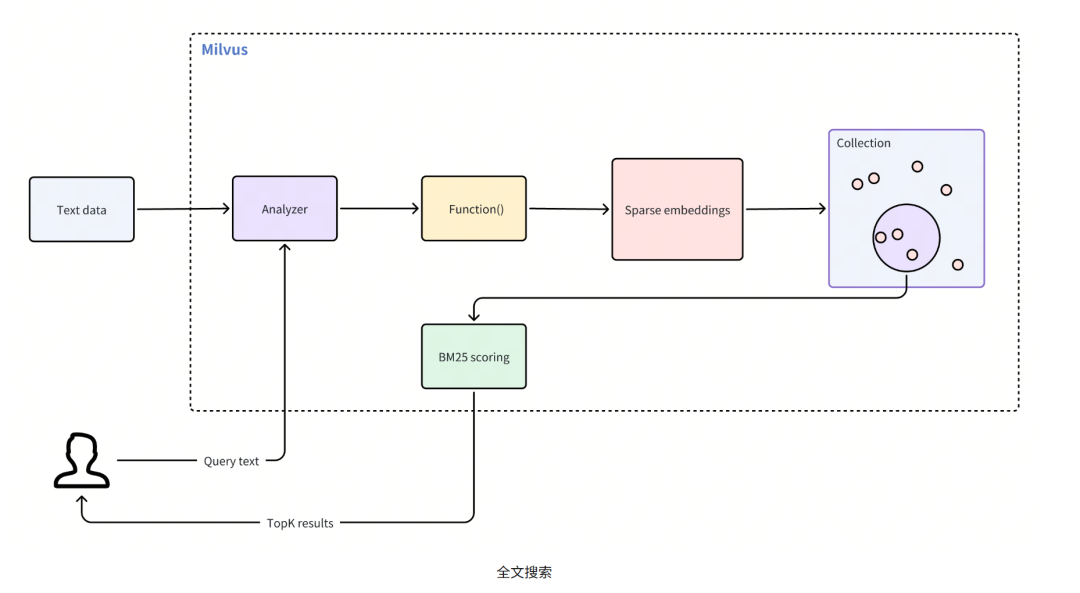
使用全文搜索遵循的主要步骤:
- 创建Collections: 设置一个带有必要字段的Collections,并定义一个将原始文本转换为稀疏嵌入的函数。
- 插入数据:将原始文本文档插入Collections。
- 执行搜索:使用查询文本搜索Collections并检索相关的结果。
search_params = {
'params': {'drop_ratio_search': 0.2}, # Proportion of small vector values to ignore during the search
}
client.search(
collection_name='demo',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
limit=3,
search_params=search_params
)
4、混合搜索
混合搜索是一种同时进行多个ANN搜索、对多个ANN结果进行重排并最终返回一组结果的搜索方法。使用混合搜索能很大程度提高搜索的精度,最常用于稀疏密集向量搜索和多模态搜索等场景。
混合搜索的应用场景: 稀疏-密集向量搜索
稀疏向量:稀疏向量的主要特点是向量维度高(上万到上百万),但大多数维度为0,仅有很少的维度为非零。例如基于词项的 One-hot/Bag-of-Words/TF-IDF 表示。
-
优势:可解释性强、可按词项精准匹配、与倒排索引结合后高效、对罕见专有名词敏感。
-
不足:维度极高且不捕捉语义同义关系;对拼写变化、同义词、上下文语义不鲁棒。
密集向量:维度较低(几十到几千),大多数维度均为非零实数,由神经网络(如 Transformer)编码得到的语义嵌入。例如,用 BERT/SimCSE/CLIP 等模型将一句话编码为长度为 768 的浮点向量,每个维度都可能是非零值。 -
优势:能表达语义相似度,对同义表达、改写、跨语言/多模态更友好;维度低、利于 ANN 加速。
-
不足:可解释性弱,可能召回“语义近但术语不匹配”的结果;依赖模型质量与更新成本。
| 维度/属性 | 稀疏向量 | 密集向量 |
|---|---|---|
| 典型维度 | 很高(104–106) | 较低(32–4096) |
| 非零比率 | 很低(<< 1%) | 很高(接近 100%) |
| 构建方式 | 规则工程:词袋、n-gram、TF-IDF、BM25 权重等 | 深度模型编码:BERT、Sentence-BERT、word2vec、CLIP |
| 含义 | 精确的特征计数/权重,偏词项匹配 | 压缩的语义表示,捕捉相似含义 |
| 相似度/距离 | 余弦、点积、Jaccard、BM25 等;常用倒排索引 | 余弦、内积、欧氏;常用 ANN 索引(HNSW、IVF-PQ) |
| 存储结构 | 稀疏存储(CSR/COO、倒排表) | 稠密数组(连续内存、向量数据库) |
| 检索特性 | 可解释、可控、对关键词精确 | 语义泛化强、召回语义相近而非关键词相同 |
| 更新成本 | 词表变动成本高;新增文档更新倒排即可 | 需向量化新数据;模型更迭需重编码 |
| 典型应用 | 传统全文检索、广告匹配的关键词阶段召回 | 语义搜索、相似内容推荐、多模态检索 |
六、RAG的完整实现流程

- 数据加载:文档读取与解析、 格式转换、去重与初步清洗、元数据提取
- 向量化:文档分块切分、 嵌入模型选择、 向量计算与存储、 建立高效索引
- 检索:查询向量化、 相似度计算、 检索策略优化、 结果过滤与排序
- 生成:Prompt模板构建、 上下文注入、 LLM参数调优、 回答生成与格式化
- 评估:准确性检测、 相关性评分、 用户反馈收集、 迭代优化
七、RAG的简单示例
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# 1. 数据加载
loader = DirectoryLoader('./documents/', glob="AI/*.txt")
documents = loader.load()
print(f"加载了 {len(documents)} 个文档")
# 2. 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_documents(documents)
print(f"文档分割为 {len(chunks)} 个块")
# 3. 向量化与存储
embeddings = OpenAIEmbeddings()
vector_store = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
vector_store.persist()
print("向量存储创建完成并已持久化")
# 4. 创建检索问答链
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # stuff方法:将所有文档合并作为上下文
retriever=retriever,
return_source_documents=True # 返回源文档以便参考
)
# 5. 交互式问答
def ask(question):
result = qa_chain({"query": question})
print(f"\n问题: {question}")
print(f"\n回答: {result['result']}")
print("\n参考来源:")
for i, doc in enumerate(result["source_documents"][:2], 1):
print(f"{i}. {doc.metadata.get('source', '未知来源')}")
return result
# 测试示例
ask("什么是向量数据库?")
ask("RAG与传统LLM微调相比有什么优势?")
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐

 8
8 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)