




- @m0_66899341
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
空间参照是体现机器人与3D物理世界交互的基本能力。 然而,即使使用强大的预训练视觉语言模型(VLM),最近的方法仍然无法准确理解复杂的3D场景,也无法动态推理指令指示的交互位置。 为此,我们提出了RoboRefer,这是一种3D感知的VLM,可以通过监督式微调(SFT)集成一个解耦但专用的深度编码器,首先实现精确的空间理解。 此外,RoboRefer通过强化微调(RFT)推进了广义多步空间推理,并

MedVLM-R1是一种能够生成明确推理过程的医学VLM,它采用GRPO框架进行训练,旨在提升医学影像分析的透明度和可信度。该模型不仅提供最终答案,还通过自然语言形式详细阐述其推理过程。

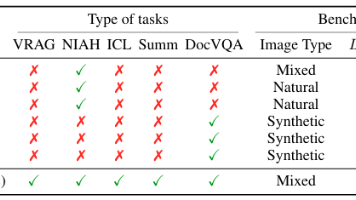
本文介绍了MMLongBench,这是首个专门用于评估长上下文视觉语言模型(LCVLMs)的基准,旨在处理包含大量图像和文本的长上下文信息。MMLongBench包含13,331个示例,覆盖五种任务类型和多种图像类型,通过标准化输入长度(8K-128K标记)评估模型的鲁棒性。研究对46个闭源和开源LCVLMs进行了全面评估,发现单一任务表现不能完全代表模型的长上下文能力,且闭源和开源模型均面临挑战
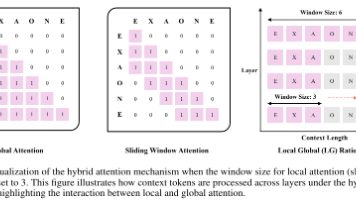
摘要:EXAONE4.0通过创新架构设计融合非推理与推理模式,支持英语、韩语和西班牙语,并增强智能体工具使用能力。该系列包含32B和1.2B两种参数规模的模型,在数学编程、长文本处理等任务中表现优异。研究采用混合注意力机制、扩展预训练数据至14万亿token,并通过三阶段后训练优化性能。尽管存在数据偏差、推理预算限制等挑战,该模型在多个基准测试中展现出竞争力,为未来智能体AI发展奠定基础。研究成果
本研究揭示了GPTQ量化算法与格点理论中巴拜最近平面算法的数学等价性。通过理论分析证明,当GPTQ从后向前执行时,其量化过程等同于解决由输入海森矩阵定义的最近向量问题。这一发现为GPTQ提供了两个重要理论支撑:误差传播的几何解释,以及无裁剪条件下的误差上界保证。研究还提出了基于LDL分解的"最小支点"排序启发式算法,为优化量化顺序提供了新思路。该成果将格点算法与模型量化建立理论

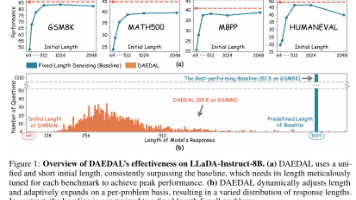
摘要:扩散型大语言模型(DLLMs)面临静态生成长度限制的关键挑战,导致性能与计算效率的权衡困境。本文提出DAEDAL策略,通过两阶段动态调整机制实现无训练的自适应长度扩展:初始阶段通过序列补全指标迭代扩展大致长度,去噪阶段则精准定位并扩展不足区域。实验表明,该方法在数学推理和代码生成任务中达到或超越固定长度基线性能,同时显著提升有效标记比率(如GSM8K任务从27.7%提升至73.5%),为DL
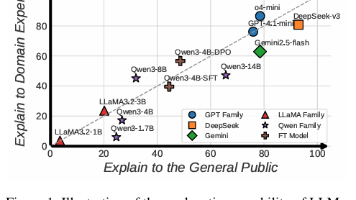
本研究探讨大语言模型生成幸福相关概念解释的能力。构建了包含10种模型对2194个概念生成的43,880条解释的数据集,提出原则指导型评估框架,采用双重评判机制评估解释质量。研究发现:1)模型评判与人类评估高度契合;2)不同模型、受众和概念类别的解释质量存在显著差异;3)通过监督微调(SFT)和直接偏好优化(DPO)微调的模型性能优于更大规模模型。研究为提升专业领域解释质量提供了有效方法,同时指出了
摘要:本研究提出首个金融大语言模型认知诊断评估框架FinCDM,突破传统单一分数评估的局限。基于注册会计师考试构建的CPA-QKA数据集覆盖70个核心金融概念,由专家严格标注技能标签。采用非负矩阵协同分解方法,该框架在30个主流模型上验证了其有效性,成功揭示模型在税务、监管等领域的知识缺口,并发现模型行为聚类现象。实验表明,即使总分相近的模型在具体金融技能上存在显著差异,且语言资源不足会严重影响性
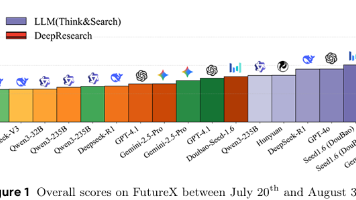
《FutureX:面向大语言模型智能体的动态实时预测评估基准》摘要 本研究针对大语言模型(LLM)未来预测能力评估的空白,提出首个动态实时基准测试FutureX。该基准从195个高质量网站每日采集未来导向问题,通过自动化流程避免数据污染,支持对25个LLM智能体的持续评估。研究显示:具备搜索推理能力的模型(如Grok-4、GPT-o4-mini)显著优于基础模型,但在复杂任务中仍落后人类专家40%
【摘要】本研究针对大型语言模型(LLMs)在理解"废话学"(Drivelology)这种表面无意义但隐含深层语义的语言现象时的局限性,构建了包含1200余例多语言样本的基准数据集DRIVELHUB。通过分类、生成和推理三项任务测试发现,当前最优模型DeepSeekV3在分类任务中仅达81.67%准确率,且所有模型在复杂推理任务中表现显著下降,暴露出LLMs在语用理解、文化背景解
