
大语言模型部署完整指南:从0到1傻瓜式全流程梳理
大模型部署技术指南摘要 本指南系统性地介绍了大语言模型(LLM)的部署全流程,涵盖硬件评估、框架选择、API标准、模型下载和生产部署等核心环节。 硬件评估部分详细解析了显存计算公式,包括模型参数量、精度格式和KV缓存的影响,并提供了Llama-7B等主流模型的显存需求参考。 部署框架章节对比了vLLM、SGLang、FastChat等5种主流方案,重点分析了vLLM的PagedAttention技
内容概览
1. 硬件需求评估 (第一章)
- GPU内存计算核心公式及详细解释
- 不同精度格式对显存的影响
- 实际案例计算(Llama-7B)
- KV Cache内存占用计算
- 在线计算工具推荐
2. 部署框架详解 (第二章)
深入介绍了5个主流框架:
- vLLM: 高性能推理引擎,PagedAttention核心技术
- SGLang: 新一代框架,结构化输出,RadixAttention
- FastChat: LMSYS全栈平台,分布式架构
- 官方Transformers: 快速原型开发
- ModelScope: 中文模型优化
每个框架都包含安装、配置、使用示例和最佳实践
3. OpenAI API标准 (第三章)
/v1/chat/completions和/v1/completions端点详解- OpenAI Python SDK的
base_url自动路径拼接机制 - OpenAI风格API的生态价值
- 无缝迁移示例代码
4. 模型权重下载 (第四章)
- Hugging Face Hub: CLI和Python API方法
- ModelScope: 中国本土化方案
- Git LFS直接克隆
- 镜像加速(HF-Mirror)
- 缓存机制和文件结构
5. 生产环境部署 (第五章)
- Docker容器化最佳实践
- Kubernetes部署配置
- Prometheus监控指标
- 安全认证和速率限制
- 负载均衡架构(含Nginx配置)
6. 故障排查 (第六章)
- OOM问题解决
- 模型加载优化
- 延迟优化策略
7. 总结与最佳实践 (第七章)
- 部署检查清单
- 不同场景的框架选择建议
- 成本优化策略
一、硬件需求评估与计算
1.1 硬件需求的核心指标
部署大语言模型时,硬件需求主要取决于以下几个关键因素:
模型参数量(Parameters)
- 这是最直接影响硬件需求的因素
- 常见规模:7B、13B、70B、175B等
精度格式(Precision)
- FP32(全精度):每个参数占用4字节
- FP16/BF16(半精度):每个参数占用2字节
- INT8(8位量化):每个参数占用1字节
- INT4(4位量化):每个参数占用0.5字节
推理批次大小(Batch Size)
- 影响吞吐量和显存占用
- 需要在延迟和吞吐量之间权衡
序列长度(Sequence Length)
- 上下文窗口的大小(如2K、4K、8K、32K tokens)
- 更长的序列需要更多显存来存储KV Cache
1.2 显存需求计算公式
基础模型加载显存需求
模型权重显存 = 参数量 × 每参数字节数示例计算:
|
模型规模 |
FP32 |
FP16/BF16 |
INT8 |
INT4 |
|
7B |
28 GB |
14 GB |
7 GB |
3.5 GB |
|
13B |
52 GB |
26 GB |
13 GB |
6.5 GB |
|
70B |
280 GB |
140 GB |
70 GB |
35 GB |
|
175B |
700 GB |
350 GB |
175 GB |
87.5 GB |
KV Cache显存需求
KV Cache是Transformer架构中用于存储注意力机制中间结果的缓存,其大小计算公式为:
KV Cache显存 = 2 × 批次大小 × 序列长度 × 层数 × 隐藏层维度 × 每参数字节数以Llama-2-7B为例:
- 层数:32
- 隐藏层维度:4096
- 序列长度:4096 tokens
- 批次大小:1
- 精度:FP16(2字节)
KV Cache = 2 × 1 × 4096 × 32 × 4096 × 2 bytes
= 2,147,483,648 bytes
≈ 2 GB总显存需求估算
总显存需求 = 模型权重 + KV Cache + 激活值 + 梯度(训练时) + 优化器状态(训练时) + 开销对于推理场景,通常需要预留20-30%的额外显存作为操作缓冲。
推理显存估算公式:
推理显存 ≈ (模型权重 + KV Cache) × 1.2~1.31.3 硬件查询资源
官方文档和技术规格
- Hugging Face Model Cards
-
- 网址:https://huggingface.co/models
- 大多数开源模型的Model Card中都包含推荐的硬件配置
- Papers with Code
-
- 网址:https://paperswithcode.com
- 提供论文、代码和硬件需求的综合信息
- GPU规格对比
-
- NVIDIA官网:https://www.nvidia.com/en-us/data-center/
- 技术白皮书包含详细的显存、带宽、算力等参数
在线工具
模型显存计算器:https://app.linpp2009.com/zh/llm-gpu-memory-calculator
通过输入模型、计算精度、上下文长度、并发数即可得到所需显存。
1.4 常见模型的硬件需求参考
|
模型 |
参数量 |
FP16最小显存 |
推荐GPU |
备注 |
|
Llama-2-7B |
7B |
~16 GB |
RTX 4090, A5000 |
单卡可部署 |
|
Llama-2-13B |
13B |
~28 GB |
A100-40GB |
单卡可部署 |
|
Llama-2-70B |
70B |
~140 GB |
2×A100-80GB |
需要多卡 |
|
Mistral-7B |
7B |
~16 GB |
RTX 4090, A5000 |
单卡可部署 |
|
Mixtral-8x7B |
47B |
~94 GB |
2×A100-80GB |
MoE架构 |
|
GPT-3 |
175B |
~350 GB |
4×A100-80GB |
需要多卡 |
|
Qwen-7B |
7B |
~16 GB |
RTX 4090, A5000 |
单卡可部署 |
|
ChatGLM3-6B |
6B |
~13 GB |
RTX 3090, A5000 |
单卡可部署 |
注意:
- 以上数据基于FP16精度和基本推理配置
- 实际需求会根据批次大小、序列长度和并发请求数波动
- 量化(INT8/INT4)可以显著降低显存需求,但可能轻微影响模型性能
二、主流部署框架详解
2.1 部署框架概览
大模型部署框架在过去几年快速发展,每个框架都有其特定的优势和适用场景:
2.2 Transformers原生部署
2.2.1 基本概念
Hugging Face的Transformers库是最广泛使用的LLM开发工具,提供了统一的接口来加载和使用各种预训练模型。
2.2.2 Tokenizer的深入理解
在Transformer架构中,tokenizer的作用远不止简单的文本切分:
Tokenizer的核心功能:
- 文本标准化(Normalization)
-
- 统一字符编码(Unicode规范化)
- 大小写转换
- 重音符号处理
- 预分词(Pre-tokenization)
-
- 将文本分割成词或字符
- 处理空格和标点符号
- 分词算法(Tokenization)
-
- BPE (Byte Pair Encoding):用于GPT系列
- WordPiece:用于BERT
- SentencePiece:用于T5、Llama
- Unigram:用于部分多语言模型
- 后处理(Post-processing)
-
- 添加特殊标记([CLS]、[SEP]、、等)
- 生成attention mask
- 生成token type IDs
- 编码映射
-
- 将tokens转换为model input IDs
- 维护词汇表(vocabulary)
与GPT-3的tiktoken对比:
|
特性 |
tiktoken (OpenAI) |
Transformers Tokenizer |
|
设计目的 |
API调用计费、速度优化 |
模型训练和推理的完整流程 |
|
功能范围 |
单纯编码解码 |
完整的预处理pipeline |
|
特殊标记 |
有限支持 |
完整支持模型所需的所有标记 |
|
配置灵活性 |
固定模式 |
高度可配置 |
2.2.3 基本部署代码
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 加载模型和tokenizer
model_path = "meta-llama/Llama-2-7b-chat-hf" # 或本地路径
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16, # 使用半精度节省显存
device_map="auto", # 自动分配设备
trust_remote_code=True # 某些模型需要
)
# 推理
def generate_response(prompt: str, max_new_tokens: int = 512):
# Tokenization
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generation
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.7,
top_p=0.9,
do_sample=True,
repetition_penalty=1.1
)
# Decode
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 使用示例
prompt = "What is artificial intelligence?"
response = generate_response(prompt)
print(response)2.2.4 优缺点分析
优点:
- 易于上手,文档完善
- 支持最广泛的模型
- 社区活跃,问题解决快
- 适合研究和原型开发
缺点:
- 推理性能较低
- 不支持高级优化(如PagedAttention)
- 并发处理能力有限
- 显存利用率不高
2.3 vLLM:高性能推理引擎
2.3.1 核心技术
vLLM是UC Berkeley开发的高性能LLM推理引擎,其核心创新是PagedAttention算法:
PagedAttention工作原理:
传统的KV Cache管理方式类似于操作系统的连续内存分配,容易产生内存碎片和浪费。PagedAttention借鉴了操作系统的虚拟内存和分页机制:
- 分块存储:将KV Cache分成固定大小的块(pages)
- 按需分配:只在需要时分配新的块
- 动态调整:支持不同序列长度共享物理块
- 高效复用:支持多个请求共享相同的KV Cache(如beam search)
性能提升:
- 吞吐量提升:相比HuggingFace Text Generation Inference提升2-4倍
- 显存利用率:提升到接近100%(传统方法仅20-40%)
- 延迟优化:通过连续批处理(Continuous Batching)降低延迟
2.3.2 部署示例
# 安装vLLM
# pip install vllm
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(
model="meta-llama/Llama-2-7b-chat-hf",
tensor_parallel_size=1, # GPU数量
dtype="float16",
max_model_len=4096, # 最大序列长度
gpu_memory_utilization=0.9 # GPU显存利用率
)
# 设置采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512
)
# 批量推理
prompts = [
"What is the capital of France?",
"Explain quantum computing in simple terms.",
"Write a Python function to calculate factorial."
]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Generated: {output.outputs[0].text}")
print("-" * 50)2.3.3 OpenAI兼容API服务
vLLM提供了OpenAI兼容的API服务器:
# 启动vLLM服务器
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1客户端调用:
from openai import OpenAI
# 连接到vLLM服务器
client = OpenAI(
api_key="EMPTY", # vLLM不需要API key
base_url="http://localhost:8000/v1"
)
# 使用标准OpenAI接口
response = client.chat.completions.create(
model="meta-llama/Llama-2-7b-chat-hf",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is machine learning?"}
],
temperature=0.7,
max_tokens=512
)
print(response.choices[0].message.content)2.4 SGLang:高效的结构化生成
2.4.1 核心特性
SGLang(Structured Generation Language)是由LMSYS团队开发的框架,专注于:
- RadixAttention:更高效的KV Cache共享机制
- 结构化生成:支持JSON、正则表达式等约束生成
- 高级控制流:支持条件分支、循环等编程结构
RadixAttention vs PagedAttention:
|
特性 |
PagedAttention (vLLM) |
RadixAttention (SGLang) |
|
Cache管理 |
基于分页 |
基于前缀树(Radix Tree) |
|
共享粒度 |
固定大小的页 |
可变长度的前缀 |
|
适用场景 |
通用推理 |
有大量公共前缀的场景 |
|
典型应用 |
一般对话 |
Few-shot learning、RAG |
2.4.2 部署代码
import sglang as sgl
# 初始化runtime
runtime = sgl.Runtime(
model_path="meta-llama/Llama-2-7b-chat-hf",
tp_size=1
)
# 定义结构化生成函数
@sgl.function
def multi_turn_qa(s, questions):
s += sgl.system("You are a helpful assistant.")
for q in questions:
s += sgl.user(q)
s += sgl.assistant(sgl.gen("answer", max_tokens=256))
# 执行
state = multi_turn_qa.run(
questions=[
"What is Python?",
"How is it different from Java?",
"Give me a code example."
],
runtime=runtime
)
# 输出结果
for i, answer in enumerate(state["answer"]):
print(f"Answer {i+1}: {answer}")2.4.3 约束生成示例
@sgl.function
def extract_json(s, text):
s += sgl.user(f"Extract structured information from: {text}")
s += sgl.assistant(sgl.gen(
"json_output",
max_tokens=512,
regex=r'\{[^\}]*\}' # JSON格式约束
))
# 使用
state = extract_json.run(
text="John Doe, 30 years old, lives in New York, works as a software engineer.",
runtime=runtime
)2.5 FastChat:集成式聊天机器人解决方案
2.5.1 架构设计
FastChat由LMSYS团队开发,提供完整的聊天机器人部署方案: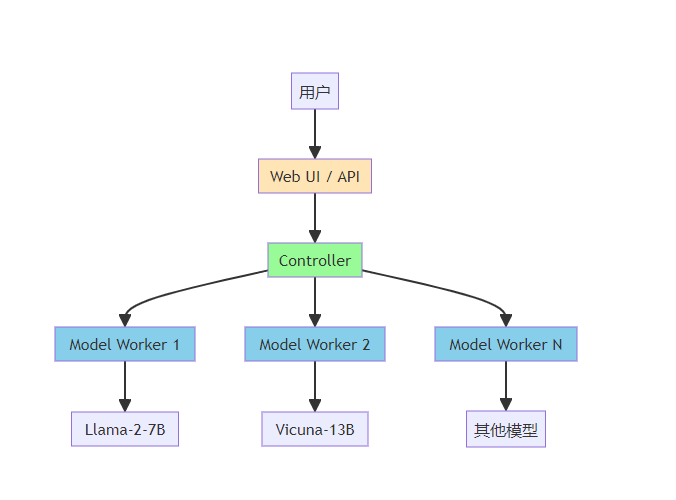
2.5.2 部署步骤
# 1. 安装FastChat
pip install "fschat[model_worker,webui]"
# 2. 启动Controller(负责协调)
python -m fastchat.serve.controller --host 0.0.0.0 --port 21001
# 3. 启动Model Worker(加载模型)
python -m fastchat.serve.model_worker \
--model-path meta-llama/Llama-2-7b-chat-hf \
--controller http://localhost:21001 \
--worker-address http://localhost:31000 \
--host 0.0.0.0 \
--port 31000
# 4. 启动OpenAI API服务器
python -m fastchat.serve.openai_api_server \
--controller-address http://localhost:21001 \
--host 0.0.0.0 \
--port 8000
# 5. 启动Web UI(可选)
python -m fastchat.serve.gradio_web_server \
--controller http://localhost:21001 \
--port 78602.5.3 多模型部署
FastChat支持同时部署多个模型:
# Worker 1: Llama-2-7B
python -m fastchat.serve.model_worker \
--model-path meta-llama/Llama-2-7b-chat-hf \
--controller http://localhost:21001 \
--worker-address http://localhost:31000 \
--port 31000
# Worker 2: Vicuna-13B
python -m fastchat.serve.model_worker \
--model-path lmsys/vicuna-13b-v1.5 \
--controller http://localhost:21001 \
--worker-address http://localhost:31001 \
--port 310012.6 ModelScope:阿里云开源平台
2.6.1 平台特点
ModelScope是阿里云推出的模型托管和部署平台,特别适合中文模型:
- 集成大量中文优化模型(Qwen、ChatGLM、Baichuan等)
- 提供模型微调和评估工具
- 支持一键部署到云端
- 国内访问速度快
2.6.2 使用示例
# 安装
pip install modelscope
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import snapshot_download
# 方法1:直接加载
model_dir = "qwen/Qwen-7B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
)
# 方法2:先下载再加载
model_dir = snapshot_download("qwen/Qwen-7B-Chat", cache_dir="./models")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto")
# 推理
response, history = model.chat(
tokenizer,
"你好,请介绍一下人工智能",
history=None
)
print(response)2.7 框架对比与选择
|
框架 |
适用场景 |
性能 |
易用性 |
生态 |
|
Transformers |
研究、原型开发 |
⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
|
vLLM |
生产环境、高吞吐 |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
|
SGLang |
结构化生成、RAG |
⭐⭐⭐⭐⭐ |
⭐⭐⭐ |
⭐⭐⭐ |
|
FastChat |
聊天机器人、多模型 |
⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
|
ModelScope |
中文模型、快速部署 |
⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
选择建议:
- 快速原型:Transformers + Gradio
- 生产部署(英文为主):vLLM + OpenAI API
- 结构化输出需求:SGLang
- 中文应用:ModelScope + FastChat
- 多模型服务:FastChat + vLLM backend
三、OpenAI API标准与兼容性
3.1 OpenAI API的标准路径
OpenAI定义的API端点已成为业界事实标准。理解这些端点对于构建兼容的服务至关重要。
3.1.1 核心端点
Chat Completions(主要端点)
POST https://api.openai.com/v1/chat/completions这是最常用的端点,用于多轮对话:
{
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"temperature": 0.7,
"max_tokens": 150
}Completions(传统端点)
POST https://api.openai.com/v1/completions用于单次文本补全,现已较少使用:
{
"model": "gpt-3.5-turbo-instruct",
"prompt": "Once upon a time",
"max_tokens": 50
}Embeddings(向量化端点)
POST https://api.openai.com/v1/embeddings用于获取文本的向量表示:
{
"model": "text-embedding-ada-002",
"input": "The quick brown fox jumps over the lazy dog"
}Models(模型列表)
GET https://api.openai.com/v1/models列出所有可用模型。
3.1.2 完整的API URL结构
https://api.openai.com/v1/{endpoint}
└─────┬─────┘ └┬┘ └───┬───┘
Base URL Version Endpoint组成部分:
- Base URL:
https://api.openai.com - API Version:
/v1- 当前版本号 - Endpoint: 具体的功能路径
3.2 OpenAI Python SDK的路径处理
3.2.1 SDK的自动拼接机制
OpenAI Python SDK(version 1.0+)内部自动处理路径拼接:
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="sk-...",
base_url="https://api.openai.com/v1" # 可选,默认就是这个
)
# SDK内部会自动拼接完整路径
# client.chat.completions.create()
# -> POST https://api.openai.com/v1/chat/completions
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello"}]
)3.2.2 自定义Base URL
对于自部署的模型服务(如vLLM、FastChat),可以修改base_url:
# 连接到本地vLLM服务
client = OpenAI(
api_key="EMPTY", # 本地服务通常不需要key
base_url="http://localhost:8000/v1" # 自定义base URL
)
# SDK会将端点拼接到自定义base URL后面
# -> POST http://localhost:8000/v1/chat/completions
response = client.chat.completions.create(
model="meta-llama/Llama-2-7b-chat-hf",
messages=[{"role": "user", "content": "Hello"}]
)3.2.3 SDK源码解析
OpenAI SDK内部的路径构建逻辑(简化版):
class OpenAI:
def __init__(self, api_key, base_url="https://api.openai.com/v1"):
self.api_key = api_key
self.base_url = base_url.rstrip('/') # 移除末尾斜杠
def _build_url(self, endpoint):
"""构建完整URL"""
# 确保endpoint以/开头
if not endpoint.startswith('/'):
endpoint = '/' + endpoint
# 拼接base_url和endpoint
return f"{self.base_url}{endpoint}"
def _request(self, method, endpoint, **kwargs):
"""发送HTTP请求"""
url = self._build_url(endpoint)
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 实际的HTTP请求
response = requests.request(
method=method,
url=url,
headers=headers,
**kwargs
)
return response3.3 OpenAI风格(OpenAI-Compatible)的意义
3.3.1 什么是OpenAI风格
"OpenAI-Compatible"或"OpenAI-Style API"是指遵循OpenAI API规范的接口设计,包括:
- 端点路径一致性
-
- 使用相同的URL结构(/v1/chat/completions等)
- 请求格式一致性
-
- 相同的JSON schema
- 相同的参数命名和类型
- 响应格式一致性
-
- 相同的返回结构
- 相同的错误处理方式
- 认证方式一致性
-
- Bearer token认证
- API key管理
3.3.2 OpenAI风格的优势
1. 无缝迁移
使用OpenAI API的应用可以零代码或最小改动迁移到自部署模型:
# 原本使用OpenAI GPT-4
client = OpenAI(
api_key="sk-...",
base_url="https://api.openai.com/v1"
)
# 迁移到自部署的Llama-2(只需改base_url)
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1"
)
# 其余代码完全不变
response = client.chat.completions.create(...)2. 生态兼容
大量工具和框架支持OpenAI API,采用相同风格即可直接集成:
- LangChain
- LlamaIndex
- AutoGPT
- Semantic Kernel
- Haystack
示例:LangChain集成
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
# 使用自部署模型
llm = ChatOpenAI(
model_name="meta-llama/Llama-2-7b-chat-hf",
openai_api_base="http://localhost:8000/v1",
openai_api_key="EMPTY"
)
# 正常使用LangChain功能
response = llm([HumanMessage(content="Hello!")])3. 统一的开发体验
团队可以使用相同的SDK和工具,降低学习成本:
# 统一的接口,不同的后端
def get_llm_client(backend="openai"):
if backend == "openai":
return OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://api.openai.com/v1"
)
elif backend == "vllm":
return OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1"
)
elif backend == "azure":
return OpenAI(
api_key=os.getenv("AZURE_API_KEY"),
base_url=f"https://{resource}.openai.azure.com/openai/deployments/{deployment}"
)
# 使用时只需指定backend
client = get_llm_client(backend="vllm")3.3.3 实现OpenAI兼容API
如果要为自己的模型实现OpenAI兼容接口,需要遵循以下规范:
基本框架(使用FastAPI)
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Optional
import time
import uuid
app = FastAPI()
class Message(BaseModel):
role: str
content: str
class ChatCompletionRequest(BaseModel):
model: str
messages: List[Message]
temperature: Optional[float] = 0.7
max_tokens: Optional[int] = 512
stream: Optional[bool] = False
class ChatCompletionResponse(BaseModel):
id: str
object: str = "chat.completion"
created: int
model: str
choices: List[dict]
usage: dict
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
# 模型推理逻辑
response_text = your_model_generate(
request.messages,
temperature=request.temperature,
max_tokens=request.max_tokens
)
# 构建OpenAI格式响应
return ChatCompletionResponse(
id=f"chatcmpl-{uuid.uuid4().hex}",
created=int(time.time()),
model=request.model,
choices=[{
"index": 0,
"message": {
"role": "assistant",
"content": response_text
},
"finish_reason": "stop"
}],
usage={
"prompt_tokens": count_tokens(request.messages),
"completion_tokens": count_tokens(response_text),
"total_tokens": count_tokens(request.messages) + count_tokens(response_text)
}
)
@app.get("/v1/models")
async def list_models():
return {
"object": "list",
"data": [
{
"id": "your-model-name",
"object": "model",
"created": int(time.time()),
"owned_by": "organization"
}
]
}3.4 流式响应(Streaming)
OpenAI API支持流式响应,这对于改善用户体验至关重要:
# 客户端启用streaming
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Write a story"}],
stream=True # 启用流式响应
)
# 逐token接收并显示
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end='', flush=True)服务端实现(FastAPI + SSE)
from fastapi.responses import StreamingResponse
import json
@app.post("/v1/chat/completions")
async def chat_completions(request: ChatCompletionRequest):
if request.stream:
return StreamingResponse(
stream_generator(request),
media_type="text/event-stream"
)
else:
# 非流式响应
return normal_response(request)
async def stream_generator(request):
"""生成SSE格式的流式响应"""
for token in model_generate_stream(request.messages):
chunk = {
"id": f"chatcmpl-{uuid.uuid4().hex}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": request.model,
"choices": [{
"index": 0,
"delta": {"content": token},
"finish_reason": None
}]
}
yield f"data: {json.dumps(chunk)}\n\n"
# 发送结束标记
yield "data: [DONE]\n\n"四、模型权重下载与管理
4.1 主要模型托管平台
4.1.1 Hugging Face Hub
特点:
- 全球最大的开源模型社区
- 模型数量最多,质量高
- 支持Git LFS,便于版本管理
- 提供模型卡片和详细文档
下载方式1:使用transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
# 自动下载到默认缓存目录(~/.cache/huggingface/)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# 指定缓存目录
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
cache_dir="./models"
)下载方式2:使用huggingface-cli
# 安装huggingface_hub
pip install huggingface_hub
# 登录(部分模型需要)
huggingface-cli login
# 下载整个模型仓库
huggingface-cli download meta-llama/Llama-2-7b-chat-hf \
--local-dir ./models/llama-2-7b-chat \
--local-dir-use-symlinks False
# 下载特定文件
huggingface-cli download meta-llama/Llama-2-7b-chat-hf \
pytorch_model.bin \
--local-dir ./models/llama-2-7b-chat下载方式3:使用Git LFS
Git Large File Storage(Git LFS)是一种用于处理大文件的工具,在 Hugging Face 下载大模型时,通常需要安装 Git LFS,主要的原因是:Git 本身并不擅长处理大型文件,因为在 Git 中,每次我们提交一个文件,它的完整内容都会被保存在 Git 仓库的历史记录中。但对于非常大的文件,这种方式会导致仓库变得庞大而且低效。而 Git LFS, 就不会直接将它们的内容存储在仓库中。相反,它存储了一个轻量级的“指针”文件,它本身非常小,它包含了关于大型文件的信息(如其在服务器上的位置),但不包含文件的实际内容。当我们需要访问或下载这个大型文件时,Git LFS 会根据这个指针去下载真正的文件内容。
实际的大文件存储在一个单独的服务器上,而不是在 Git 仓库的历史记录中。所以如果不安装 Git LFS 而直接从 Hugging Face 或其他支持 LFS 的仓库下载大型文件,通常只会下载到一个包含指向实际文件的指针的小文件,而不是文件本身。安装完成后,需要初始化 Git LFS。这一步是必要的,因为它会设置一些必要的钩子。Git 钩子(hooks)是 Git 提供的一种强大的功能,允许在特定的重要动作(如提交、推送、合并等)发生时自动执行自定义脚本。这些钩子是在 Git 仓库的 .git/hooks 目录下的脚本,可以被配置为在特定的 Git 命令执行前后触发。钩子可以用于各种自动化任务,比如:
- 代码检查: 在提交之前自动运行代码质量检查或测试,如果检查失败,可以阻止提交。
- 自动化消息: 在提交或推送后发送通知或更新任务跟踪系统。
- 自动备份: 在推送到远程仓库之前自动备份仓库。
- 代码风格格式化: 自动格式化代码以符合团队的代码风格标准。
# 安装git-lfs这个工具
sudo apt-get install git-lfs
# 初始化 Git LFS
# 初始化git lfs,会设置一些在上传或下载大文件是必要的操作,如在提交之前检查是否有大文件被 Git 正常跟踪,而不是通过 Git LFS 跟踪,从而防止大文件意外地加入到 Git 仓库中。(pre-commit 钩子)或者在合并后,确保所有需要的 LFS 对象都被正确拉取(post-merge)等。
git lfs install
# 克隆模型仓库
git clone https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
# 部分下载(只下载特定文件)
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
cd Llama-2-7b-chat-hf
git lfs pull --include="*.bin,*.safetensors"下载方式4:Python编程式下载
from huggingface_hub import snapshot_download, hf_hub_download
# 下载整个模型
snapshot_download(
repo_id="meta-llama/Llama-2-7b-chat-hf",
local_dir="./models/llama-2-7b-chat",
local_dir_use_symlinks=False,
resume_download=True # 支持断点续传
)
# 下载单个文件
hf_hub_download(
repo_id="meta-llama/Llama-2-7b-chat-hf",
filename="pytorch_model.bin",
local_dir="./models/llama-2-7b-chat"
)4.1.2 ModelScope(魔搭社区)
特点:
- 阿里云支持,国内访问快
- 大量中文优化模型
- 集成训练和部署工具
下载方式1:使用modelscope库
from modelscope import snapshot_download
# 下载完整模型
model_dir = snapshot_download(
'qwen/Qwen-7B-Chat',
cache_dir='./models',
revision='v1.0.0' # 指定版本
)
# 下载特定文件
from modelscope.hub.file_download import model_file_download
model_file_download(
model_id='qwen/Qwen-7B-Chat',
file_path='pytorch_model.bin',
cache_dir='./models'
)下载方式2:使用Git
# 安装Git LFS
git lfs install
# 克隆模型
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git下载方式3:使用modelscope命令行工具
# 安装
pip install modelscope
# 下载模型
modelscope download --model qwen/Qwen-7B-Chat --local_dir ./models/qwen-7b4.1.3 其他平台
Google Cloud Storage(部分开源模型)
# 使用gsutil
gsutil -m cp -r gs://bucket-name/model-path ./local-pathAWS S3
# 使用aws cli
aws s3 sync s3://bucket-name/model-path ./local-path4.2 模型文件格式
4.2.1 常见格式对比
|
格式 |
文件扩展名 |
特点 |
适用场景 |
|
PyTorch |
.bin, .pt |
原生PyTorch格式 |
PyTorch模型训练和推理 |
|
SafeTensors |
.safetensors |
安全、快速加载 |
生产环境推荐 |
|
GGUF |
.gguf |
量化友好,CPU推理优化 |
llama.cpp等CPU推理 |
|
ONNX |
.onnx |
跨框架标准 |
多框架部署 |
|
TensorFlow |
.h5, .pb |
TensorFlow格式 |
TensorFlow生态 |
4.2.2 SafeTensors详解
SafeTensors是Hugging Face推出的新格式,具有以下优势:
安全性:
- 不执行任意代码(PyTorch的pickle可能有安全风险)
- 可以在不加载整个文件的情况下检查内容
性能:
- 加载速度比PyTorch快2-3倍
- 支持零拷贝加载(mmap)
- 更小的内存峰值
兼容性:
# 转换PyTorch到SafeTensors
from safetensors.torch import save_file, load_file
# 保存
state_dict = model.state_dict()
save_file(state_dict, "model.safetensors")
# 加载
state_dict = load_file("model.safetensors")
model.load_state_dict(state_dict)4.3 权重量化与压缩
4.3.1 量化类型
后训练量化(Post-Training Quantization, PTQ)
不需要重新训练,直接对权重进行量化:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
# 4-bit量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # 使用NormalFloat4
bnb_4bit_use_double_quant=True, # 双重量化
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
quantization_config=bnb_config,
device_map="auto"
)量化感知训练(Quantization-Aware Training, QAT)
在训练过程中模拟量化效果,获得更好的性能。
4.3.2 常用量化工具
GPTQ(Generative Pre-trained Transformer Quantization)
# 安装auto-gptq
pip install auto-gptq
# 使用预量化模型
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized(
"TheBloke/Llama-2-7B-Chat-GPTQ",
device="cuda:0",
use_triton=True
)AWQ(Activation-aware Weight Quantization)
pip install autoawq
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_quantized(
"TheBloke/Llama-2-7B-Chat-AWQ",
fuse_layers=True
)4.3.3 量化效果对比
|
量化方法 |
显存占用 |
推理速度 |
精度损失 |
适用场景 |
|
FP16 |
基准 |
基准 |
无 |
足够显存时 |
|
INT8 |
-50% |
+20% |
最小 |
平衡性能和资源 |
|
GPTQ 4-bit |
-75% |
+30% |
很小 |
显存受限 |
|
AWQ 4-bit |
-75% |
+40% |
很小 |
追求速度 |
|
NF4 (bitsandbytes) |
-75% |
+10% |
很小 |
易用性优先 |
4.4 模型缓存管理
4.4.1 缓存目录结构
Hugging Face默认缓存结构:
~/.cache/huggingface/
├── hub/
│ ├── models--meta-llama--Llama-2-7b-chat-hf/
│ │ ├── blobs/
│ │ │ ├── 7c62c8d... (实际模型文件)
│ │ │ └── abc123d...
│ │ ├── refs/
│ │ │ └── main
│ │ └── snapshots/
│ │ └── commit_hash/
│ │ ├── config.json -> ../../blobs/7c62c8d...
│ │ └── pytorch_model.bin -> ../../blobs/abc123d...
└── modules/4.4.2 缓存清理
from huggingface_hub import scan_cache_dir
# 扫描缓存
cache_info = scan_cache_dir()
# 查看占用空间
print(f"Total size: {cache_info.size_on_disk_str}")
print(f"Number of repos: {len(cache_info.repos)}")
# 清理特定模型
delete_strategy = cache_info.delete_revisions(
"meta-llama/Llama-2-7b-chat-hf@main"
)
delete_strategy.execute()
# 清理所有缓存
import shutil
shutil.rmtree("~/.cache/huggingface/hub")4.5 离线部署策略
对于生产环境,推荐完全离线部署:
4.5.1 预下载清单
#!/bin/bash
# download_models.sh
# 设置代理(如果需要)
export HF_ENDPOINT=https://hf-mirror.com
# 下载模型列表
models=(
"meta-llama/Llama-2-7b-chat-hf"
"meta-llama/Llama-2-13b-chat-hf"
"mistralai/Mistral-7B-Instruct-v0.2"
)
for model in "${models[@]}"; do
echo "Downloading $model..."
huggingface-cli download "$model" \
--local-dir "./models/$(basename $model)" \
--local-dir-use-symlinks False
done4.5.2 离线加载
import os
# 禁用在线检查
os.environ["TRANSFORMERS_OFFLINE"] = "1"
os.environ["HF_DATASETS_OFFLINE"] = "1"
# 从本地路径加载
model = AutoModelForCausalLM.from_pretrained(
"./models/Llama-2-7b-chat-hf",
local_files_only=True # 强制只使用本地文件
)五、生产环境部署最佳实践
5.1 性能优化
5.1.1 批处理策略
# 动态批处理
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf")
# vLLM会自动进行批处理优化
prompts = [f"Prompt {i}" for i in range(100)]
outputs = llm.generate(prompts, sampling_params)5.1.2 多卡部署
# Tensor并行
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
tensor_parallel_size=4, # 使用4张GPU
dtype="float16"
)
# Pipeline并行(适合超大模型)
llm = LLM(
model="meta-llama/Llama-2-70b-chat-hf",
pipeline_parallel_size=2,
tensor_parallel_size=2 # 共4张GPU
)5.2 监控与日志
import time
from prometheus_client import Counter, Histogram, start_http_server
# Prometheus指标
request_count = Counter('llm_requests_total', 'Total requests')
request_duration = Histogram('llm_request_duration_seconds', 'Request duration')
@request_duration.time()
def generate_with_metrics(prompt):
request_count.inc()
start_time = time.time()
response = model.generate(prompt)
latency = time.time() - start_time
print(f"Latency: {latency:.2f}s")
return response
# 启动Prometheus endpoint
start_http_server(9090)5.3 负载均衡与扩展
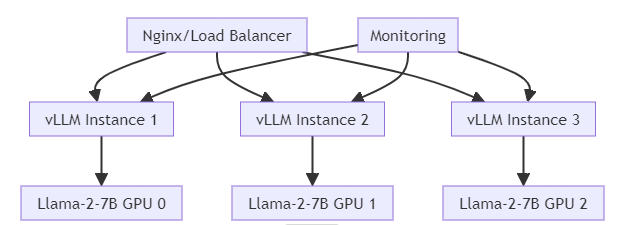
Nginx配置示例:
upstream llm_backend {
least_conn; # 最少连接数负载均衡
server 127.0.0.1:8000 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8001 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8002 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
location /v1/ {
proxy_pass http://llm_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_connect_timeout 300s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
}
}5.4 安全性考虑
5.4.1 输入验证
import re
from fastapi import HTTPException
def validate_prompt(prompt: str) -> str:
# 长度限制
if len(prompt) > 8000:
raise HTTPException(status_code=400, detail="Prompt too long")
# 注入攻击检测
dangerous_patterns = [
r"<script>",
r"javascript:",
r"eval\(",
]
for pattern in dangerous_patterns:
if re.search(pattern, prompt, re.IGNORECASE):
raise HTTPException(status_code=400, detail="Invalid prompt")
return prompt5.4.2 速率限制
from slowapi import Limiter
from slowapi.util import get_remote_address
limiter = Limiter(key_func=get_remote_address)
@app.post("/v1/chat/completions")
@limiter.limit("10/minute") # 每分钟10次
async def chat_completions(request: Request, body: ChatRequest):
# 处理逻辑
pass六、故障排查与常见问题
6.1 显存溢出(OOM)
症状:
RuntimeError: CUDA out of memory解决方案:
- 降低批次大小
- 使用量化(INT8/INT4)
- 减少最大序列长度
- 启用梯度检查点(训练时)
- 使用多卡分布式
6.2 加载速度慢
优化方法:
- 使用SafeTensors格式
- 使用本地SSD存储
- 启用模型预加载
- 使用mmap加载
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True # 降低CPU内存占用
)6.3 推理延迟高
诊断步骤:
- 检查GPU利用率(
nvidia-smi) - 分析瓶颈(计算 vs 内存带宽)
- 优化KV Cache管理
- 考虑使用更高效的推理引擎(vLLM/TensorRT-LLM)
七、总结与展望
7.1 部署框架选择决策树
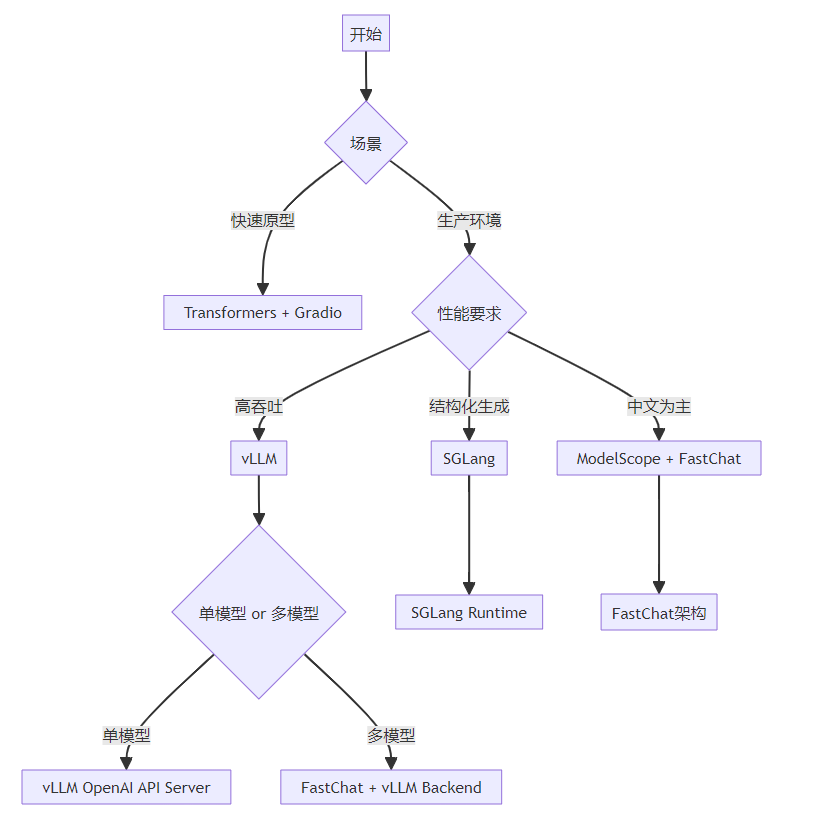
7.2 未来趋势
- 模型压缩技术
-
- 更高效的量化算法
- 知识蒸馏和剪枝
- 混合精度训练
- 推理优化
-
- Flash Attention 3
- Speculative Decoding
- Multi-Query Attention (MQA)
- 部署标准化
-
- OpenAI API成为事实标准
- ONNX Runtime对LLM的优化
- 跨平台统一部署方案
- 边缘部署
-
- 量化模型在移动设备运行
- WebAssembly支持
- 端云协同推理
参考文献
- vLLM: Easy, Fast, and Cheap LLM Serving
-
- 介绍PagedAttention技术和vLLM架构
- https://github.com/vllm-project/vllm
- Hugging Face Transformers Documentation
-
- Transformers库官方文档,包含模型加载和tokenizer详解
- https://huggingface.co/docs/transformers
- OpenAI API Reference
-
- OpenAI官方API文档,定义了API标准规范
- https://platform.openai.com/docs/api-reference
- FastChat: An Open Platform for Training, Serving, and Evaluating LLM
-
- FastChat的设计理念和部署指南
- https://github.com/lm-sys/FastChat
- SGLang: Efficient Execution of Structured Language Model Programs
-
- 介绍RadixAttention和结构化生成技术
- https://github.com/sgl-project/sglang
- ModelScope Documentation
-
- 魔搭社区官方文档
- https://modelscope.cn/docs
- SafeTensors: Simple, Safe Way to Store and Distribute Tensors
-
- SafeTensors格式的技术细节
- https://github.com/huggingface/safetensors
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
-
- GPTQ量化算法论文
- https://arxiv.org/abs/2210.17323
- AWQ: Activation-aware Weight Quantization for LLM Compression
-
- AWQ量化技术
- https://arxiv.org/abs/2306.00978
- LLM Inference Performance Engineering
-
- NVIDIA关于LLM推理优化的技术白皮书
- https://developer.nvidia.com/blog/
- Papers with Code: Language Models
- Llama 2: Open Foundation and Fine-Tuned Chat Models
-
- Meta的Llama 2技术报告
- https://arxiv.org/abs/2307.09288
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)