




- @m0_58581576
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
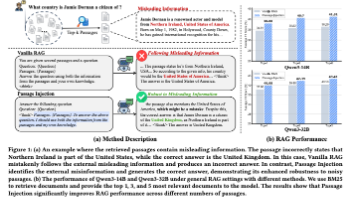
检索增强生成(RAG)已广泛应用于为大型语言模型(LLM)引入外部知识,以应对知识密集型任务。然而,检索到的段落中往往存在噪声(即低质量内容),严重削弱了 RAG 的效果。提升 LLM 对这种噪声的鲁棒性,对于增强 RAG 系统的可靠性至关重要。近期研究赋予 LLM 强大的推理与自我反思能力,使其能够发现并纠正推理过程中的错误。
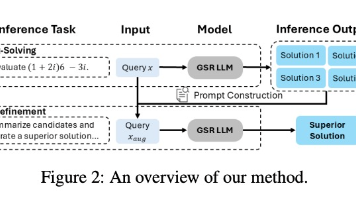
为了进一步增强大语言模型(LLM)解决复杂、多步推理问题的能力,测试时缩放(TTS)方法已受到广泛关注。现有方法(如 Best-of-N 和多数投票)受限于候选回答的质量——当所有候选都错误时,它们也无法给出正确解;而引入额外模型来挑选最佳回答则会显著增加部署成本。
WordPecker:开源AI语言学习工具颠覆传统背词方式 这个名为WordPecker的开源项目通过AI技术革新语言学习体验。它将智能导师、场景对话和视觉联想融为一体,提供: 智能场景化学习:通过图片情境和真实对话练习词汇 自动生词管理:在互动中智能识别并记录生词 多模式训练:支持5种练习方式及跨语言学习 完全开源免费:支持本地部署保障数据隐私 项目提供Docker一键部署方案,适合各类用户。相
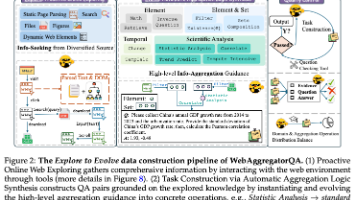
**摘要:本研究提出"Explore to Evolve"范式,构建了首个同时支持信息检索(IS)和聚合(IA)的WebAggregatorQA数据集,并开发了WebAggregator系列模型。关键发现:1)现有AI模型在信息聚合任务上表现薄弱,Claude-3.7-sonnet在WebAggregatorQA上仅达28%准确率;2)基于SmolAgents框架训练的WebA
阿里开源Logics-Parsing文档解析模型,能理解文档逻辑结构并精准提取内容。该模型在复杂文档处理上表现优异,支持嵌套表格、手写公式、化学结构式等专业内容识别,输出结构化HTML结果。性能碾压同类工具,在中文表格识别准确率达86.6%,化学结构式错误率仅51.9%。三步即可完成安装使用,适用科研、数据分析等多个场景。目前完全开源,支持商业化应用,为专业文档处理提供了高效解决方案。

【PPT制作神器Presenton开源上线】这款本地部署的AI工具能自动生成专业演示文稿,支持多种模型自由组合(如GPT-4、Llama等),完美适配企业品牌模板。3分钟即可通过Docker部署,数据完全私有,还能用API批量生成。相比付费工具,它更安全灵活,支持PPTX/PDF导出,彻底告别排版熬夜。项目正在快速迭代,现已开放GitHub下载,是职场人士和学术工作者的效率利器。
尽管大型语言模型(LLMs)在自然语言理解方面表现出色,但它们在检索任务中的应用一直未被充分利用。我们提出了Search-R3,这是一个新颖的框架,通过使LLMs将其推理过程的直接输出生成为搜索嵌入向量,从而解决了这一限制。

《开源AI伴侣Airi爆火:技术+情感的双重革命》 GitHub开源项目Airi两周内斩获5K星,成为现象级"电子伴侣"。这款基于大语言模型的AI突破传统聊天机器人局限,具备动态人格建模、长期记忆和情境感知能力,能根据用户习惯提供个性化陪伴。其开源特性允许开发者高度定制人格参数,已有"东北唠嗑版"等创意变体走红。Airi的走红折射出Z世代对情感陪伴的刚需与A

摘要:DocuTranslate是一款基于大模型的开源翻译工具,突破传统翻译格式错乱的局限,支持PDF、Word、Excel等10+文件格式,完美保留原文表格、公式和代码结构。工具具有术语表自动生成、OCR扫描识别、局域网共享等特色功能,支持本地离线部署和API调用。提供40M轻量安装包,3步即可完成配置,适用于科研文献、商务合同、视频字幕等多种场景,实测翻译效率提升300%。项目持续更新,已在G

VoxCPM开源语音合成模型引发热议,仅需几秒音频即可高精度克隆人声,完美复刻音色、语气和发音细节。该模型采用端到端扩散自回归架构,支持中英双语零样本克隆和语境感知合成,能自动调整新闻播报、诗歌朗诵等不同场景的语音风格。实测显示其错误率低于1.93%,相似度超72%,在普通显卡上即可速度是实时5倍。项目提供Python库、命令行和网页交互三种使用方式,适合各类用户。目前已在社区引发AI voice
