




- @ju7ran
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
更多AI大模型开发都在这>><< >><<

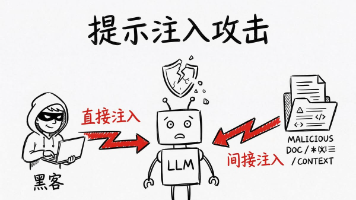
摘要:OWASP更新大语言模型(LLM)十大安全威胁,提示注入攻击位居榜首,黑客可通过直接或间接方式劫持AI系统。敏感信息泄露风险大幅上升,攻击者可提取模型中的机密数据。供应链漏洞、数据投毒等威胁同样严重,可能引发错误决策或植入恶意代码。防御措施包括AI防火墙、访问控制、数据清洗和渗透测试等组合方案。随着AI能力提升,安全风险同步增加,企业需立即采取行动防范潜在攻击。
OpenAI最新发布的GPT 5.4展现出惊人的能力跃迁,测试显示其能轻松完成3D建模、音乐创作、医学影像分析等复杂任务。该模型在70%的专业任务上超越人类专家,数学物理能力尤为突出,但存在较高幻觉率问题。支持100万token的超大上下文窗口,编程能力业界领先。目前该模型已向付费用户开放,标志着AI能力的边界正在快速扩展,可能彻底改变专业工作方式。

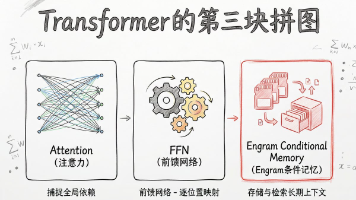
DeepSeek发布重磅论文提出Engram组件,为Transformer架构引入第三个核心模块。Engram作为条件记忆机制,能快速识别和检索多词元模式,避免传统架构中重复构建特征的计算冗余。研究团队通过精细实验设计证明,Engram与MOE分别代表条件记忆和条件计算两个不同的稀疏性维度,最佳配置是将20-25%稀疏容量分配给Engram。机制分析显示,Engram能显著提升模型早期层的表现,在
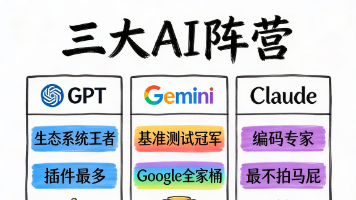
AI世界真相:ChatGPT等应用只是"门",背后是GPT等核心模型在运作。三大主流AI阵营各有优势:OpenAI的GPT-5.2是全能选手,Google的Gemini深度整合办公生态,Anthropic的Claude擅长编程推理。开源模型如DeepSeek、Llama让用户实现"从租到有"的转变。AI正从聊天转向代理模式,能直接执行多步骤任务。建议根据需求
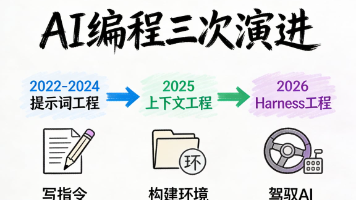
OpenAI 团队在总结他们的工作时说了这么一句话,我们现在最大的挑战在于设计环境、反馈循环和控制系统。换句话说,他们不写代码,他们写的是规则。Stripe 的工程师也不写代码,他们设计的是 Blueprint,确定性节点和 Agentic 节点的混合编排,全程管控 AI 的执行流程。这说明什么?这说明一个根本性的变化,工程师的价值,或者说程序员的价值,正在从写代码的人变成设计让 Agent 可靠
摘要:为解决AI代理孤岛化问题,行业推出A2A和MCP两大协议。A2A(代理对代理协议)通过标准简历机制和JSON RPC 2.0实现代理间通信,支持多种数据类型和流式更新;MCP(模型上下文协议)则标准化代理与外部资源的连接方式,分为Host、Server和资源三层架构。两者互补使用可构建完整AI协作生态,让开发者更专注业务逻辑,促进AI工具智能化协同。这些基础协议如同互联网早期的TCP/IP,
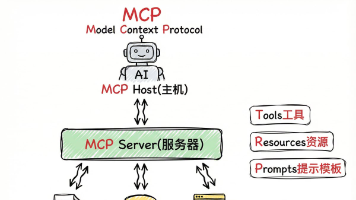
**摘要:**AI虽能回答各种知识性问题,但在执行具体任务时常出错,关键在于缺乏"程序性知识"。技能文件(skill.md)通过YAML头部和操作说明,教会AI按特定流程工作。系统采用渐进式加载避免资源浪费,与MCP、RAG等技术互补,形成类似人类记忆的认知结构。但需警惕技能文件中潜在的恶意脚本风险。该开放标准已被多个AI平台采用,使AI从"会背书"真正转变
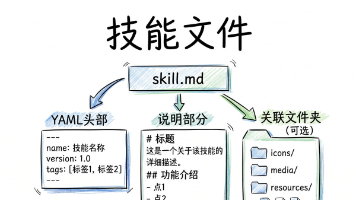
AI编程圈热议的Skill技术正引发行业变革。Skill是AI Agent的一种功能,通过一个包含SKILL.md文件的文件夹,让AI记住用户的工作习惯和流程。它解决了AI"情景性失忆"问题,将经验打包成标准化知识包。创建Skill有三种方式:直接导入他人分享的、对话式创建或手动编写。使用时可通过显式或隐式调用触发特定技能。这项技术不仅适用于编程,还能提升各类重复性工作效率,如

DeepSeek发布重磅论文提出Engram组件,为Transformer架构引入第三个核心模块。Engram作为条件记忆机制,能快速识别和检索多词元模式,避免传统架构中重复构建特征的计算冗余。研究团队通过精细实验设计证明,Engram与MOE分别代表条件记忆和条件计算两个不同的稀疏性维度,最佳配置是将20-25%稀疏容量分配给Engram。机制分析显示,Engram能显著提升模型早期层的表现,在