




- @weixin_46739757
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
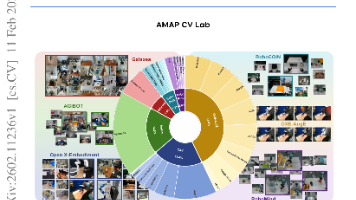
如何在不依赖私有数据和定制硬件的前提下,构建能跨多种机器人形态与任务泛化的能力统一的具身智能基础模型?论文提出ABot-M0框架,通过系统性数据整合(UniACT-dataset)、动作流形学习(AML)与双流感知架构,首次实现开源数据驱动的高性能、硬件无关具身操作模型。
如何在大型且复杂的AI Agent Harness代码库中,准确地将自然语言描述的修改需求定位到分散的源代码位置?论文提出了Harness Handbook,一种自动生成的以行为为中心的代码表征,结合行为引导的渐进式披露机制,显著提升了代码修改的定位准确性和规划质量。
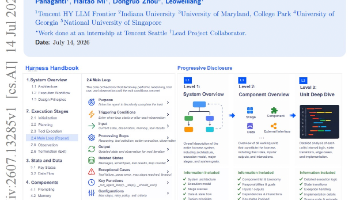
如何在大型且复杂的AI Agent Harness代码库中,准确地将自然语言描述的修改需求定位到分散的源代码位置?论文提出了Harness Handbook,一种自动生成的以行为为中心的代码表征,结合行为引导的渐进式披露机制,显著提升了代码修改的定位准确性和规划质量。
如何解决长周期具身智能体在推理执行、跨形态泛化及持久多模态记忆方面的缺失?论文提出ABot-AgentOS通用机器人代理操作系统,引入EmbodiedWorldBench基准及支持终身自进化的多模态图记忆系统。
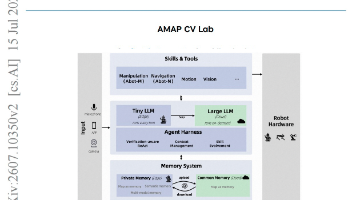
如何解决长周期具身智能体在推理执行、跨形态泛化及持久多模态记忆方面的缺失?论文提出ABot-AgentOS通用机器人代理操作系统,引入EmbodiedWorldBench基准及支持终身自进化的多模态图记忆系统。
如何解决主流E2M1格式在FP4预训练中因几何不对称导致的系统性收缩偏差及训练不稳定问题?论文揭示了非均匀格式的收缩偏差根源,提出基于均匀网格的UFP4配方,实现了全路径RHT并显著提升训练精度。
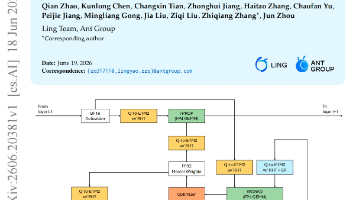
如何构建一个理论完备且组件必要的最小可行智能体技能优化流水线?论文提出SkillOpt-Lite极简框架,通过零阶优化与文件中心哲学实现比复杂基线更快更强的技能及脚手架自进化。
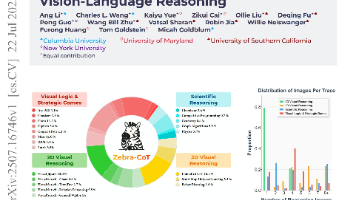
如何构建一个高质量的多模态数据集,以支持视觉与语言推理模型的训练?论文提出并发布了ZEBRA-COT数据集,包含182384个交错的文本和图像推理实例,有助于提高视觉推理模型的性能。
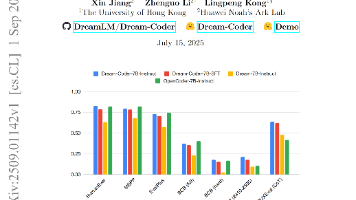
当前自回归模型在复杂编程场景下有局限性,如何利用离散扩散模型提升代码生成能力的挑战?论文提出了一种新的离散扩散语言模型——Dream-Coder 7B,强调其在代码生成中的灵活性和高效性,尤其在复杂任务上表现优异。
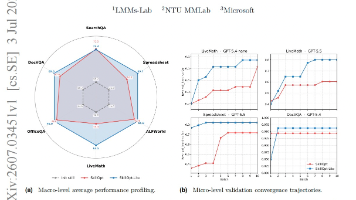
多模态大型语言模型(MLLM)在进行多模态推理时,如何分辨出来自感知、推理还是两者的整合的问题?论文提出了MATHLENS benchmark,旨在分离多模态推理中的感知、推理及其整合能力,提供了新方法以分析模型的性能。
