- @qq_42878721
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在RAG系统的整体架构中,知识准备与索引构建阶段是决定系统性能的基石。这个阶段通常发生在离线环节,主要包括以下核心步骤:数据集构建与准备、文档解析与结构化、知识索引构建。

RAG系统自动化评估框架Ragas研究 Ragas是一个专门用于评估检索增强生成(RAG)系统的开源框架,采用"无参考评估"的创新范式。该框架通过分解评估维度、利用LLM作为评估器,解决了传统RAG评估面临的成本高、指标不适用等问题。 核心特点:1、 组件化评估:分别评估检索质量(精确度、召回率)和生成质量(忠实度、相关性) 。2、自动化流程:通过LLM-as-a-Judge机

摘要 本文系统分析了检索增强生成(RAG)中的组合检索技术。首先介绍了RAG系统的核心价值与工作流程,重点阐述了稀疏检索与密集检索两大技术路线。对于稀疏检索,详细解析了BM25算法的数学原理、参数设置和实际应用,并评估了其优缺点。在密集检索部分,探讨了双编码器架构的设计与实现,包括离线索引构建和在线查询处理流程。全文通过理论分析和技术对比,为构建高效RAG系统提供了全面的技术指南。

本文探讨了RAG系统中文档解析的关键性及技术演进。文档解析将非结构化文档转换为机器可理解格式,是RAG性能的基础。传统管道式架构模块化强但存在误差累积问题,而新兴视觉语言模型(VLM)虽能端到端解析却面临幻觉和计算成本挑战。文章重点分析了表格识别的多维挑战(如误检测、结构复杂性)及解决方案,包括多模态验证、后处理筛查和专用模型应用。混合架构结合了传统方法与VLM优势,成为当前主流趋势。文档解析质量

本文介绍了Tracing集成架构的完整链路,从用户请求到监控上报的全流程。架构分为四个阶段:1)工作流执行阶段通过事件监听记录执行数据;2)追踪任务异步入队阶段实现业务与监控解耦;3)定时聚合阶段每5秒批量处理100个任务;4)Celery异步上报阶段完成数据持久化和Langfuse云端上报。关键设计包括非侵入式事件监听、分布式追踪支持(external_trace_id)、全局内存队列实现快速入
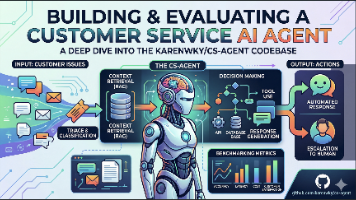
该系统通过425行代码实现了企业多部门文档的精准路由和对话式问答,并具备可观测性。核心创新在于利用LlamaCloud的托管LLM Router进行意图路由决策,仅需为每个知识库编写自然语言描述即可实现智能路由,无需训练分类器或维护规则表。
FastChat是一个开源的大语言模型服务平台,采用三层分布式架构设计,包含Controller、Worker和Server组件。Controller负责智能调度与负载均衡,支持抽奖和最短队列两种策略;Worker处理模型加载与推理,集成量化技术和多GPU并行;Server提供API兼容层和流式响应。系统采用心跳机制确保可靠性,支持多种部署模式,包括单机、多Worker和混合部署。该架构实现了控制

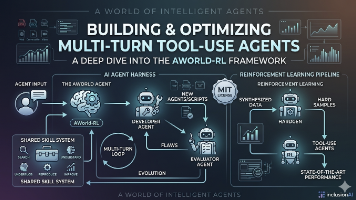
AWorld Train框架通过动态代码生成等技术,实现了LLM Agent训练系统与RL框架的无缝对接。其核心创新点包括:1、采用代码生成替代对象序列化,将Agent配置"烘焙"为Python源码文件,解决分布式环境下的跨进程通信问题2、设计精细的response_mask机制,确保训练信号仅作用于模型决策行为,避免环境反馈干扰3、实现完整的Agent训练闭环,支持从数据合成到评估的全流程自动化
本文介绍了RAG-Anything系统的核心技术,解决了传统RAG在多模态文档处理中的局限性。系统通过MinerU和Docling双解析引擎,将图表、表格、公式等非文本内容转化为知识图谱节点,并建立跨模态语义关联。创新性地采用模态感知实体化、双图索引和VLM二阶段查询等技术,显著提升了长文档多模态检索的准确性。工程实现上通过智能解析缓存、内容分离与切块策略优化处理效率,在科学问答、数据分析等任务上

系统通过三层向量池化策略(均值池化Prefetch+层次池化Rerank)解决了传统OCR方案在精度、布局语义和图表理解上的缺陷。核心技术亮点包括:1)将PDF页面渲染为图像直接处理,避免OCR损失;2)采用事件驱动架构和异步并发处理实现高效流水线;3)独创页级ID生成和向量存储策略,支持文档更新时零停机重建索引。系统特别设计了针对大规模文档集的优化方案,如多查询并行扩展、确定性UUID生成等,在