登录社区云,与社区用户共同成长
邀请您加入社区
Apache SkyWalking 通过全面拥抱 AI,已经从一款优秀的 APM 工具进化为一个智能的可观测性大脑。它通过智能异常检测、自动化根因分析、告警降噪以及与 LLM 的集成,极大地提升了运维效率,降低了 MTTR(平均修复时间)。对于任何希望构建现代化、智能化可观测性体系的技术团队来说,SkyWalking 的 AI 能力无疑是值得深入探索和应用的利器。
本文深入解析了Agent Loop(智能体循环)的概念和工作机制,它是驱动AI智能体自主完成任务的核心架构。Agent Loop由感知、思考、行动、观察四个阶段构成,形成一个"思考-行动-观察"的闭环。文章详细拆解了一个机票预订任务的循环执行过程,并阐述了关键设计要素:记忆管理、工具调用、循环控制和上下文窗口管理。最后介绍了ReAct、Plan-and-Execute和多Agent协作三种常见实现
AI Agent 交互技术对比:Function Calling、MCP与Skills 本文深入解析了三种主流AI Agent交互技术。Function Calling是LLM原生API能力,通过JSON Schema实现结构化函数调用,适合低延迟、固定工具集的场景。MCP是标准化开放协议,提供去中心化工具生态,支持动态发现和安全隔离,适用于构建通用AI平台。Skills是面向用户的任务封装,通过
文章摘要: MCP(Model Context Protocol)是Anthropic提出的开放标准协议,旨在为AI Agent提供统一、安全的外部工具与数据访问方式。它采用客户端-服务器架构,通过标准化接口实现模型与工具(如文件系统、数据库、API)的即插即用交互,解决传统定制化集成的高成本、低复用性问题。MCP的核心优势包括: 模块化:工具服务器独立部署,支持动态发现与调用; 安全性:权限隔离
《AI Agent前端开发避坑指南》摘要 本文记录了前端工程师开发企业级AI Agent的实战经验。作者从初期认为只需处理文本流式展示,到逐渐理解Agent作为复杂状态机的本质,总结了四大典型问题及解决方案:1)流式渲染性能优化;2)Markdown增量渲染策略;3)工具调用过程可视化;4)对话上下文管理。文章提出架构演进路径:从单体组件到分层设计,最终实现插件化扩展。核心启示包括:将后端数据视为
C++11引入的智能指针(unique_ptr、shared_ptr、weak_ptr)通过RAII(资源获取即初始化)理念自动化内存管理。weak_ptr则解决shared_ptr可能产生的循环引用问题。优先选择unique_ptr而非shared_ptr,除非需要共享所有权;悬空指针是指向已释放内存区域的指针。在智能指针出现前,开发者通常采用手动管理方式:在释放内存后立即将指针置为nullpt
面向对象(OOP)思想是构建复杂系统的重要基础。通过class定义类时,需识别对象属性(Attribute)与行为(Method)。例如设计一个Student类,包含学号、成绩等属性及计算平均分的方法。继承和多态特性可简化代码层级。比如定义BaseCalculator类作为基础计算器,派生的AdvancedCalculator可扩展三角函数功能,同时兼容父类接口。---
摘要: 本文探讨了将大型语言模型DeepSeek-7B部署到资源受限的边缘设备和嵌入式系统的挑战与解决方案。通过模型剪枝、量化(如INT8/FP16)、硬件适配及推理引擎优化(如ONNXRuntime、TensorRT),显著降低了模型的内存占用和计算需求。结合ARM NEON指令集优化和内存管理策略,实现了在嵌入式平台(如NVIDIA Jetson、ARM Cortex-A72)上的高效推理,延
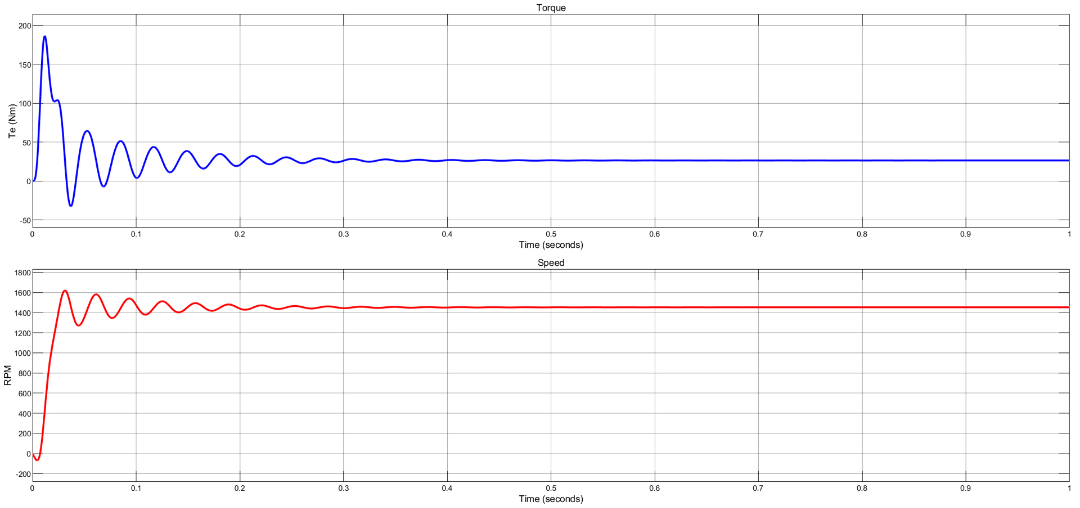
前0.5秒电流直接飙到48A,是额定值的6.4倍,跟实测数据误差在3%以内。转矩曲线在0.8秒完成收敛,转差率稳定在0.03左右,说明磁链观测器设计到位了。特别是带PID控制环的时候,时间步长设到1e-5秒,12秒的启动过程仿真能在30秒内跑完。Three_Phase_Induction_Motor:基于MATLAB/Simulink的三相感应电机动态数学建模仿真模型。Three_Phase_In
语义缓存可节省 15-40% 的重复调用费用,自适应路由可在不降低质量的前提下将成本降低 30-50%,Context 压缩可减少 20-35% 的输入 Token。将这些技术与预算熔断、实时监控相结合,才能将 AI 成本从不可控的黑盒变为可管理、可优化的工程资产。:多部门共用 API Key,成本分摊引发内部矛盾AI FinOps(Financial Operations for AI)正是解决
监控工具买了一堆,系统为何依然总崩溃?传统配置管理与资源监控缺乏全局拓扑与 AI 赋能,导致故障排查成本高昂。本文介绍智象科技如何将统一监控、ADS 自动发现与深度学习算法融合,打造全新的运维 AI 数智人。不仅颠覆了传统 CMDB 复杂查询的门槛,更实现一句话查全量资产、AI 自动推演故障根因并生成修复脚本,全面赋能企业降本增效。
学习大数据处理工具时发现理解数据库和数据仓库两个概念的重要性,这里进行一个总结。
在云栖大会的ODPS分论坛上,阿里云MaxCompute迎来了十五周年的重大技术发布。从云原生到AI原生,MaxCompute正式宣告迈入一个全新的发展阶段,推出AI原生数据仓库核心能力,构建面向AI时代的大数据基础设施。
大家好!在之前的分享中,我们对程序化广告的不少关键领域有了深入了解。今天咱们继续深入探索程序化广告行业,一起学习算法优化以及DSP系统实例相关知识,希望能和大家共同进步,在这个领域掌握更多实用技能。
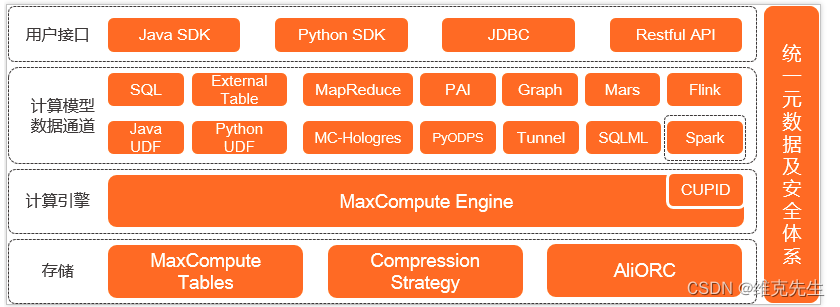
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。ETLCloud是一款零代码ETL工具,可以快速对接上百种数据源和应用系统,无需编码即可快速完成数据同步和传输,企
这两天有兴趣学习了下阿里的maxcompute大数据,随便谈谈自己的感受。
数据仓库、数据湖、流批一体,终于有大神讲清楚了!作者:蒋晓伟(量仔) 阿里云研究员金晓军(仙隐)阿里云高级技术专家摘要:数据仓库,数据湖,包括Flink社区提的流批一体,它们到底能解决什么问题?今天将由阿里云研究员从解决业务问题出发,将问题抽丝剥茧,从技术维度娓娓道来:为什么你需要数据湖或者数据仓库解决方案?它的核心难点与核心问题在哪?如果想稳定落地,系统设计该怎么做?一、业务背景1.1 典型实时
最绝的是工况识别模块,用动态时间规整算法匹配驾驶模式,比固定规则识别率高了两成。包含燃料电池汽车的燃料电池动力源功率选型,驱动电机参数匹配选型,蓄电池参数匹配选型,主减速比匹配,以满足最高车速,最大爬坡度,百公里加速时间等动力性要求。包含燃料电池汽车的燃料电池动力源功率选型,驱动电机参数匹配选型,蓄电池参数匹配选型,主减速比匹配,以满足最高车速,最大爬坡度,百公里加速时间等动力性要求。然后根据参数
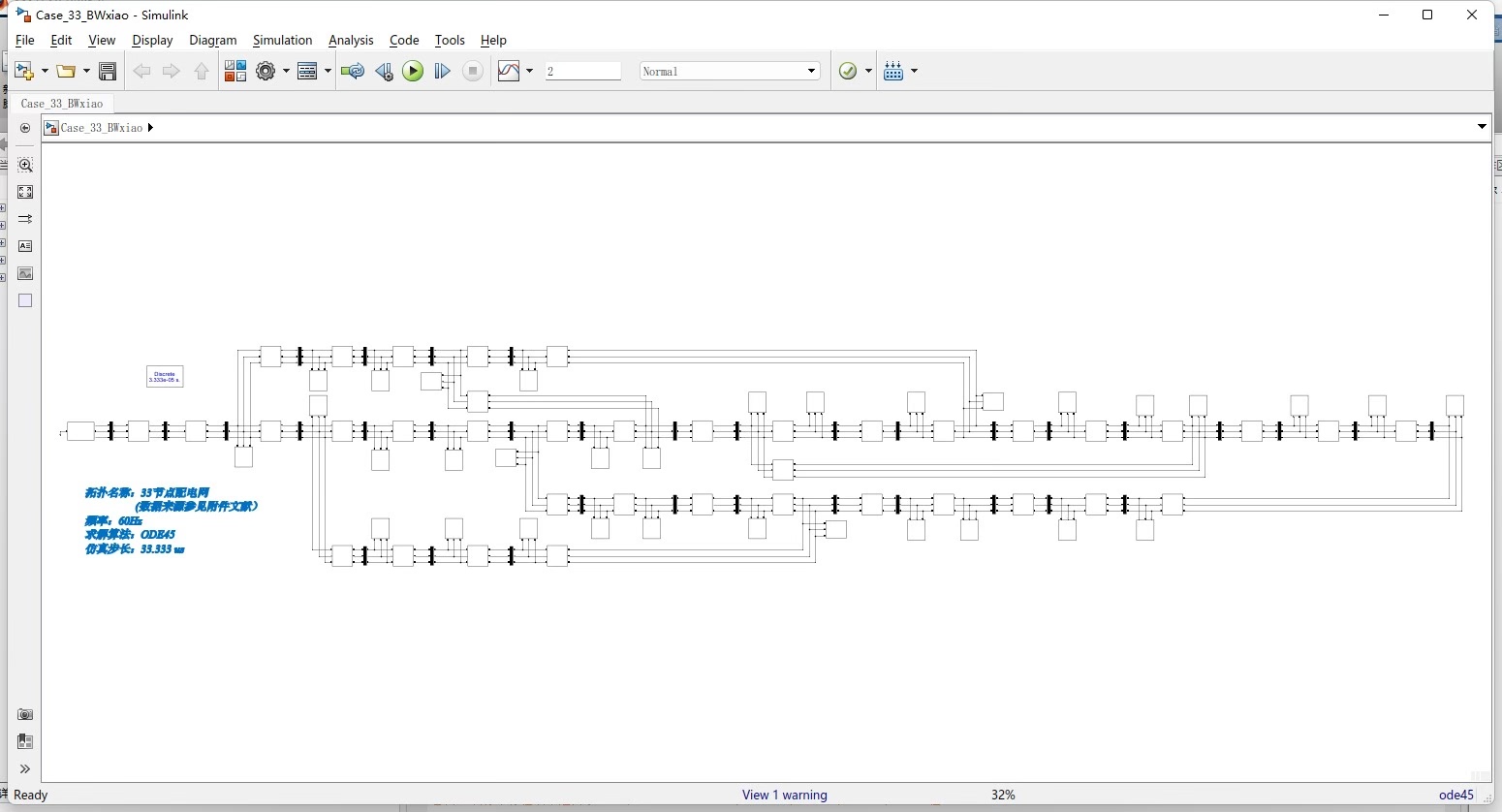
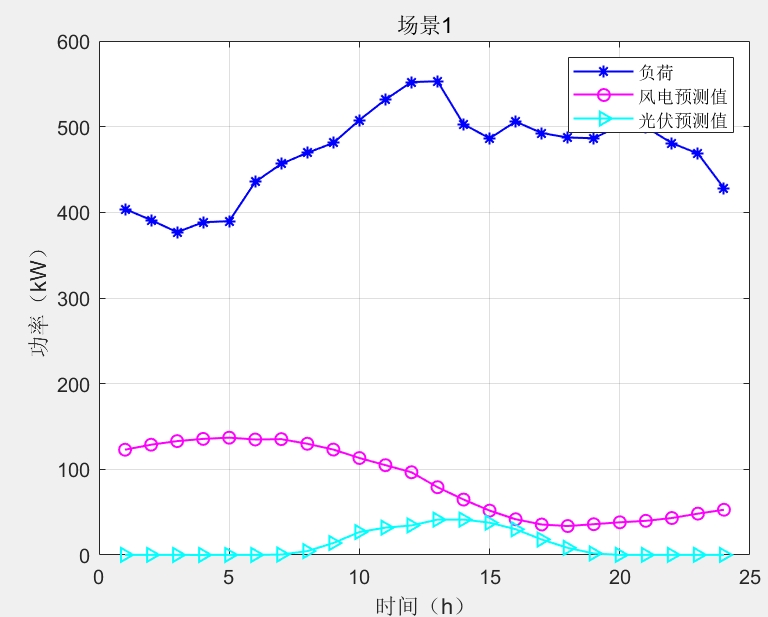
IEEE33节点配电系统是国际上广泛采用的标准测试系统,它能够很好地模拟实际配电网的运行特性。该系统包含33个节点、38条线路,具有丰富的网络拓扑结构和负荷分布特点,特别适合用于配电网潮流计算和可再生能源并网研究。通过本次研究,我们成功构建了一个基于Simulink的IEEE33节点配电网模型,并对其运行特性进行了深入分析。该模型不仅能够实现节点电压电流数据的实时采集,还为风光能源并网研究提供了良
那个Excel里的红色警告单元格不是摆设,超了标还硬上的,轻则性能打折,重则直接放烟花——别问我是怎么知道的。1.Excell设计程序,可以了解这个电机是怎么设计出来的,已知功率转矩等,计算电机的体积,叠厚,匝数等。1.Excell设计程序,可以了解这个电机是怎么设计出来的,已知功率转矩等,计算电机的体积,叠厚,匝数等。2.Maxwell参数化仿真模型:可以学习参数化仿真模型,有限元结果可查看。2
shap分析代码案例,多个机器学习模型+shap解释性分析的案例,做好的多个模型和完整的shap分析拿去直接运行,含模型之间的比较评估。类别预测和数值预测的案例代码都有,类别预测用到的6个模型是(catboost、xgboost、knn、logistic、bayes,svc),数值预测用到的6个模型是(线性回归、随机森林、xgboost、lightgbm、支持向量机、knn)在机器学习领域,模型的
基于模型预测MPC实现的车速控制,控制目标为燃油汽车,采用上下层控制器控制,上层mpc产生期望的加速度,下层采用自抗扰ADRC控制产生期望的节气门开度和制动压力,同时该算法可直接用于代码生成(可做实车试验实验),后续可以用于车速需求的控制(如acc,轨迹跟踪等)。有对应复现资料。在自动驾驶领域,车速的精准控制一直是研究重点。今天咱们来聊聊基于模型预测MPC实现的燃油汽车车速控制,这可是个有趣又实用
本程序模型通过“两阶段目标函数+矩阵化约束”的设计,构建了逻辑清晰、可扩展性强的电热系统鲁棒优化框架。第一阶段控制微燃机启停成本,第二阶段优化实时运行成本,7类核心约束确保设备安全与能量平衡,多场景变量设计支持不确定性分析。模型可直接用于后续求解器开发(如MATLAB+CPLEX),为电热综合能源系统的高效、经济、稳定运行提供数学支撑。两阶段鲁棒优化模型 多场景。
电机的电动势常数Ce=(额定电压-电枢电流×电阻)/额定转速,这里假设额定电流5A,得Ce=(24-5×0.5)/2000×9.55≈0.11V/(rad/s)。碰到震荡别慌,把积分时间翻倍试试,往往有奇效。本模型基于power system模块搭建,包括直流电机模块、三相对称电源、同步6脉冲触发器、转速环、电流环、PI控制、负载、测量模块、示波器等。本模型基于power system模块搭建,包
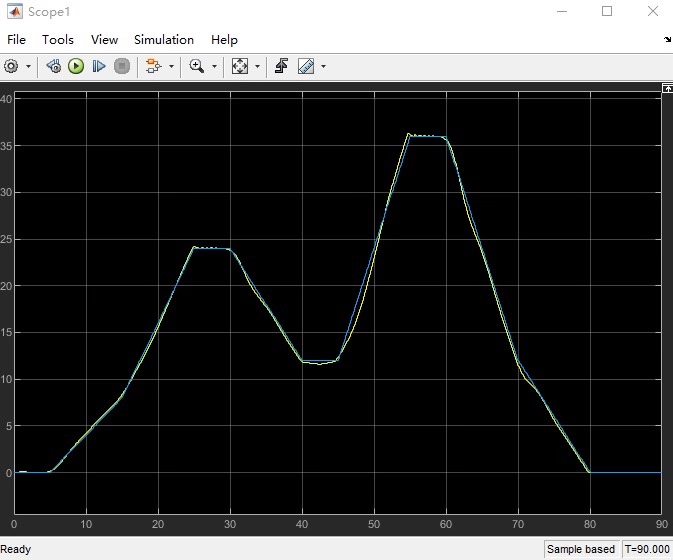
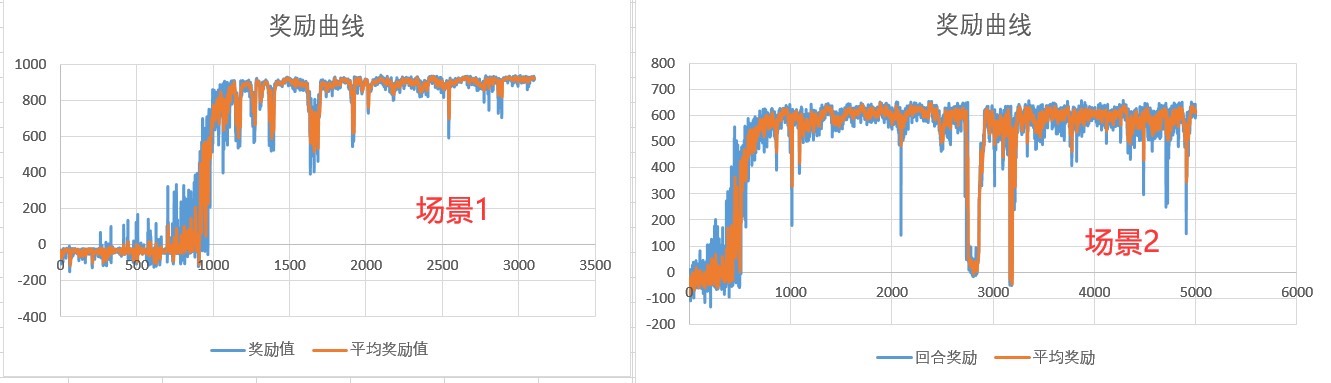
直接上实战,手把手教你在Matlab里搭建仿真环境,最后实现前车加速减速咱都能稳稳跟住的效果。训练完直接用测试脚本看效果,建议在性能好的电脑上跑,CPU占用会飚到70%以上。这个指数衰减的安全惩罚实测效果比线性惩罚好三倍不止,舒适度惩罚系数0.2是调了二十多次参数试出来的黄金值。上图可见前车(红线)在25秒时速度从20降到15,自车(蓝线)在1.2秒内完成速度匹配,没有出现明显顿挫。这个0.5秒的
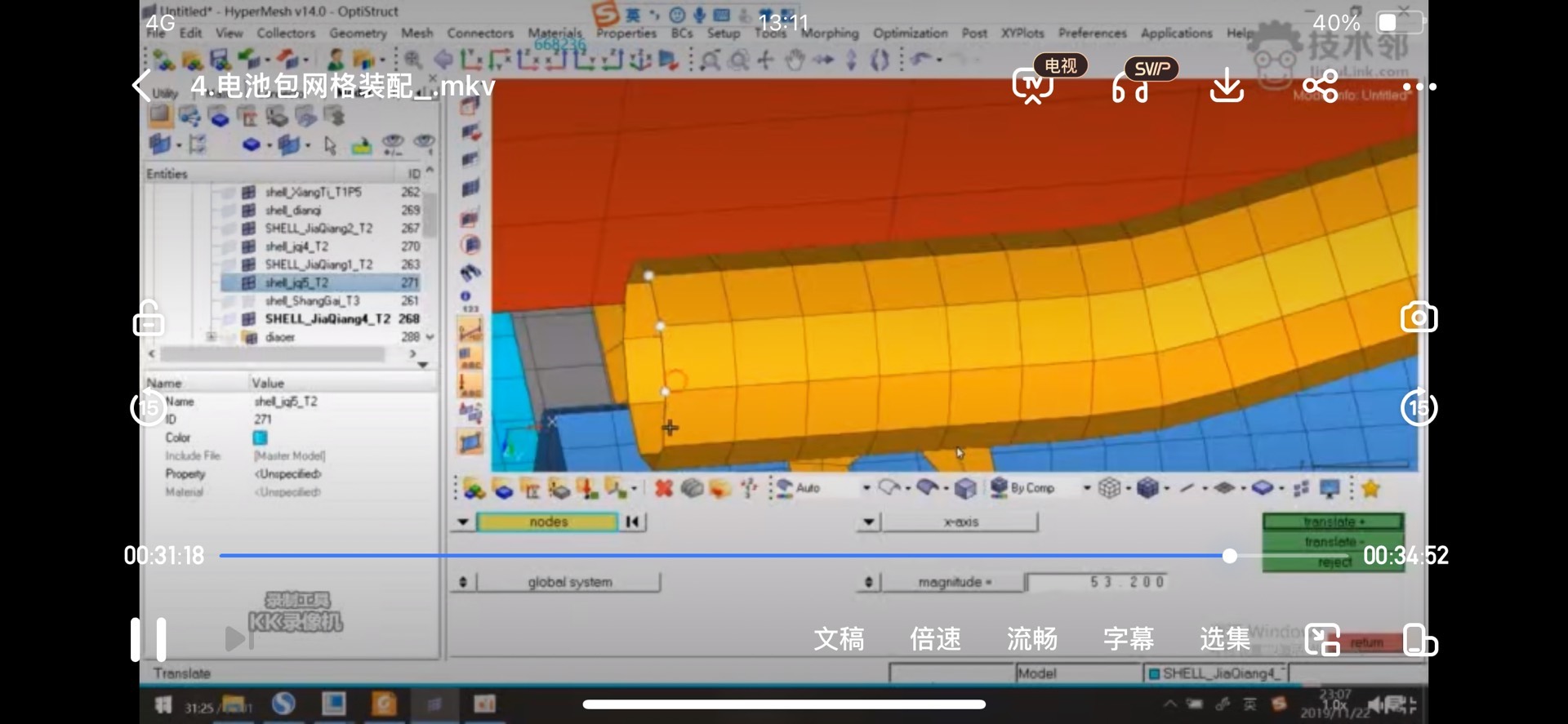
电池包结构仿真核心课程(2024新版)该套视频为本人及团队从众多相关视频中挑选整理而出,并添加了一些团队元素,该套视频实属电池仿真领域的精华。想学习电池包仿真的小伙伴,有这一套视频就够了,不需要再看那些描述的天花乱坠的视频,市场上相关视频鱼龙混杂,没有经验的人很难分辨良次,本人及团队已经替小伙伴们筛选过了,小伙伴可以进一步了解。大概目录如下:电池包模型简化与hypermesh网格划分-全套视频-6
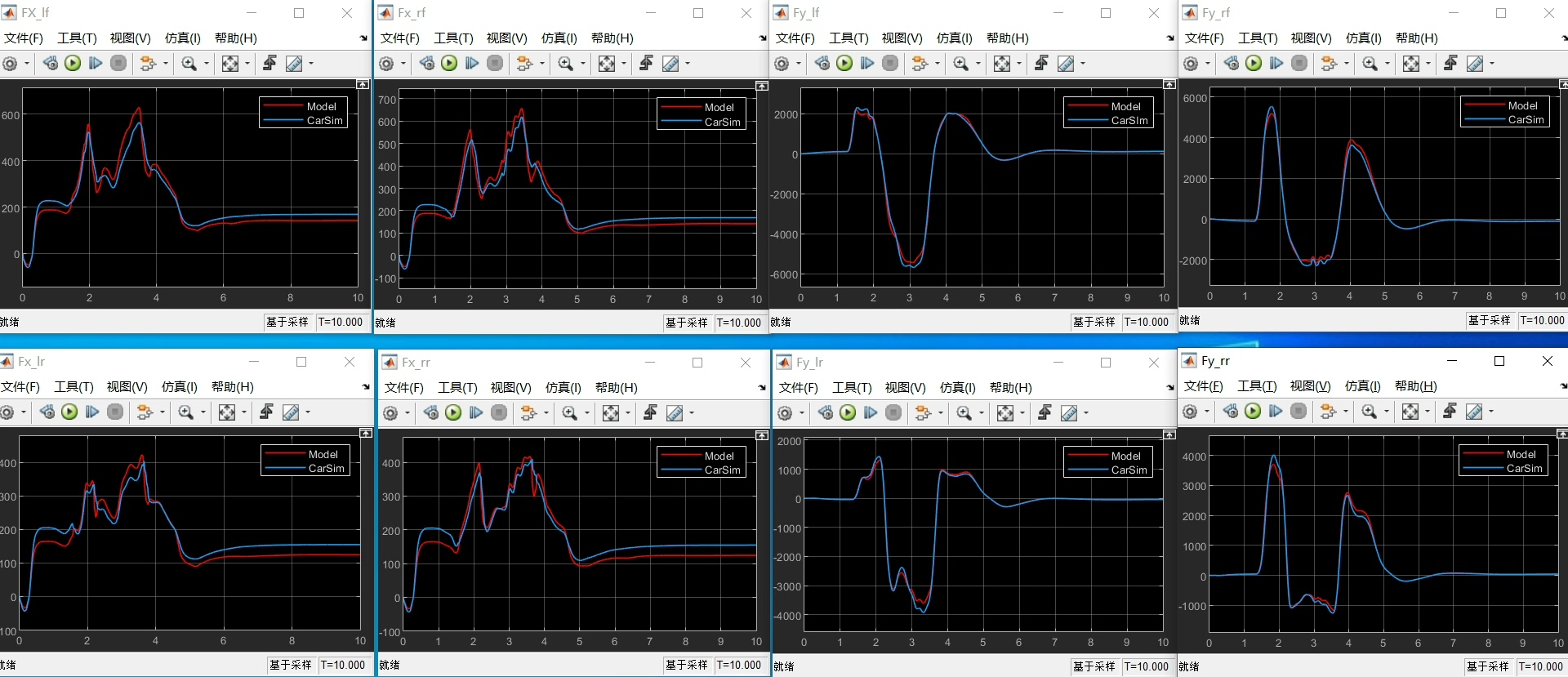
Dugoff轮胎模型验证1.软件: MATLAB 2018以上;2.商品介绍: 基于两种Dugoff轮胎模型公式搭建Simulink模型,对模型输出的纵、横向轮胎力和纵、横向归一化轮胎力,进行CarSim对比验证。本商品进行了三种极限工况下的验证,工况设置:(1)双移线,145 km/h,0.85高附路面;(2)双移线,100 km/h,0.5高附路面;(3)双移线,50 km/h,0.30高附路
横向MPC控制器以建立的三自由度车辆动力学模型为基础,轮胎模型处于线性区间,然后结合模型预测控制结构特性,利用状态轨迹法对所建立的非线性动力学模型进行线性化,同时为了与轨迹规划结合将其离散化采样控制,从而实现横向控制,车辆参考轨迹为离散的五次多项式采样点,离散点控制。自动驾驶横纵向控制,纵向采用PID控制,横向采用MPC控制,纵向PID不同于传统的烂到家的油门刹车标定表PID控制器控制前轴左右车轮
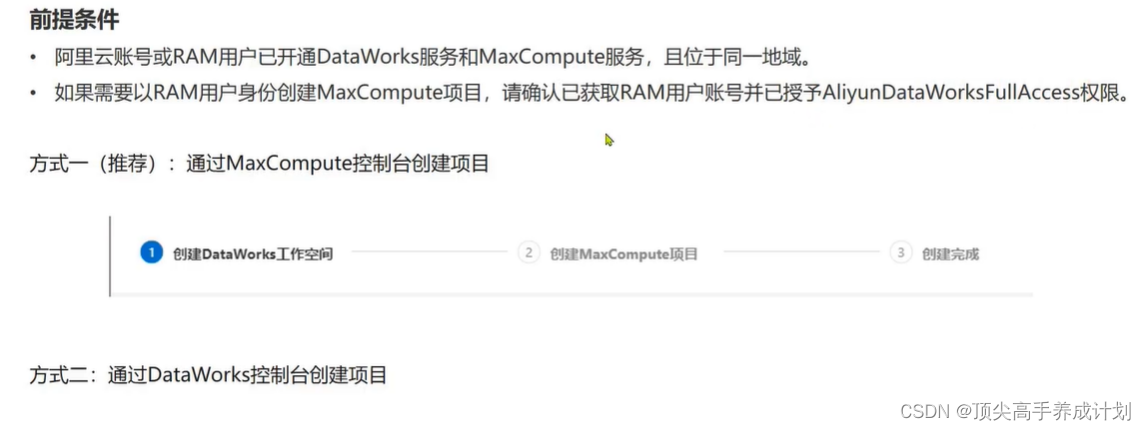
ACP(MaxCompute篇)-MaxCompute开发工具
MaxCompute报错处理方案摘要:报错可能由lxml版本限制、依赖缓存问题或环境不一致导致。解决方法是指定安装lxml旧版本(<6)并重新安装tqdm包,命令为/home/tops/bin/pip3 install "lxml<6" simple-salesforce。此操作能促使pip重新解析依赖,选择兼容版本,避免编译错误,确保环境一致性。新版lxml可能引
odps数据同步到oracle{“job”: {“setting”: {“speed”: {“channel”: 5}},“content”: [{“reader”: {“name”: “odpsreader”,“parameter”: {“accessId”: “accessId”,“accessKey”: “accessKey”,“project”: “targetProjectName”,“
MaxCompute 是面向分析的企业级SaaS模式云数据仓库,以Serberless框架提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效的分析处理海量数据。MaxCompute和DataWorks一起向用户提供完善的ETL和数仓管理能力,以及SQL、MR、Graph等多种经典的分布式计算模型,能够更快速的解决用户海量数据计
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,提供离线和流式数据的接入,支持大规模数据计算及查询加速能力。MaxCompute适用于100 GB以上规模的存储及计算需求,最大可达EB级别,适用于大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。
前情提要:当前Spark 版本为2.4.5写数据到阿里云OSS1、编写Spark 代码 - 写OSSpublic class SparkODPS2OSS4 {public static void main(String[] args) {SparkSession spark = SparkSession.builder().appName("ODPS2OSS")// 可访问O
缓慢变化维(Slowly Changing Dimensions)缓慢变化维是维度技术中用于描述维度变化情况的一种分类。什么是SDC?在现实的实施中先说一下缓慢变化维的概念。缓慢变化维(Slowly Changing Dimensions)指的是:维度中的某一个或某几个属性不是固定不变,会随着时间的推移发生低频次改变。打个比方,小李在魔都奋斗多年,成功买房落户,那么小李的户籍地址就会发生变化;如果
[yyyy-mm-dd] 表示今天{yyyy-mm-dd} 表示昨天[yyyy-mm-dd-1] 表示昨天{yyyy-mm-dd-1} 表示前天{yyyy-mm-dd-1/48} 表示前天,{}日期调度参数不支持用-1/24、-1/48这些[yyyy-mm-dd-1/48] 表示今天定时时间的前半小时,支持用-1/24、-1/48这些...
阿里云常见报错及解决方案
可以看出是由于数据类型导致的,这里count之后数据类型为bigint。有两种解决方案,一种是重新建表,数据类型为bigint。另一种是用cast进行数据类型的转换。在执行插入语句时,出现了如下错误。查看我们的建表时数据类型为int。
odps
——odps
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区
 智能体开发者社区
智能体开发者社区

 AI Agent技术社区
AI Agent技术社区



 DAMO开发者矩阵
DAMO开发者矩阵

 CSDN-OPC开发者社区
CSDN-OPC开发者社区

 AtomGit开源社区
AtomGit开源社区


 腾讯云开发者社区
腾讯云开发者社区













 魔乐社区
魔乐社区