登录社区云,与社区用户共同成长
邀请您加入社区
DBA会被AI取代吗?通过实测KES MCP Server的9个工具,发现AI已能完成数据库结构查看、SQL分析、索引建议、健康检查等核心DBA工作。虽然AI分析速度远超人工(5秒vs5分钟),但当前仍需DBA把关决策。未来AI将成为DBA的高效助手,而非完全替代者。关键在于DBA如何利用这些工具提升效率,专注于更高价值的架构设计和优化工作。
文章摘要: KES数据库推出基于MCP协议的AI调优方案,实现自然语言交互优化数据库性能。该方案通过MCP Server桥接IDE和KES数据库,支持9大工具集:数据库结构探索、SQL执行分析、运行状态检查和假设索引验证。采用五层架构设计,提供三种传输方式适应不同场景,并内置严格安全机制(Restricted模式)。方案解决了开发者频繁切换工具的痛点,使AI能直接查看数据库状态并给出优化建议,如自
【摘要】Claude3.5Sonnet与GPT-4o在SQL优化场景表现对比显著:前者索引推荐准确率93.4%,擅长解析复杂执行计划(如识别索引失效原因),但长SQL响应稍慢;后者多数据库语法转换更快,但嵌套查询分析偶现偏差。实战案例显示,Claude能有效解决函数导致索引失效问题,如将日期函数查询优化为范围扫描。使用建议:深度优化选Claude3.5($3/百万Tokens输入),语法迁移用GP
AI驱动的代理式DBA的崛起,代表着企业技术领域的又一决定性时刻。它不仅能在更短时间内完成相同任务,更将重新定义一切可能。我亲身经历了这段旅程,从传统DBA工作到在实际环境中部署智能体。我可以自信地说,数据基础设施的未来将告别手动、被动和脆弱性,全面迎接自我优化、自我修复与设计层面可靠性的新时代。这是一个人类创造力与机器精度相结合的新阶段。请各位DBA不必担心,这绝非职业发展的终点,而是又一激动人
好的,请看以“C++性能优化现代代码中的内存管理与并发编程实战”为主题的文章。
结合搜索结果及国产数据库适配场景的实际需求,目前主流的可分为「数据库建模工具」「智能问答平台」「AI 驱动的数据库管理工具」「全流程开发助手」四大类,以下详细展开每类工具的特性、适配能力,并通过对比表格明确差异,方便按需选择。
他还谈到,AI智能体的兴起正在改变开发者构建软件的方式,以及他们对数据库的新需求。这一举措折射出大型科技公司正在兴起的成本控制趋势——各家企业寻求降低对外部 AI 供应商的依赖,同时控制持续攀升的基础设施成本。EDB 将其 EDB Postgres AI 平台定位为应对多种挑战的替代方案,适用于以下场景:并发负载下查询性能下降、面临 Broadcom 或云厂商续约条款不利,以及因合规或数据主权要求
EXPLAIN是SQL优化的核心工具,但很多人只看type和key,忽略了Extra列——它才是执行计划里信息密度最高的部分。Using index和Using index condition有什么区别?Using temporary和Using filesort同时出现意味着什么?本文逐一拆解Extra列中8个最常见的性能信号,帮助读者从“看EXPLAIN”升级到“读懂EXPLAIN”。
从一次生产故障复盘出发,对比主从复制、共享存储集群、分布式三种高可用架构方案的适用场景与取舍,结合实战经验给出选型决策框架
OceanBase和金仓KingbaseES都是主流国产数据库,都有信创认证,都宣称兼容Oracle。但在实际选型中,两条技术路线的差异直接影响迁移成本和后续运维。本文从架构路线、生态兼容、多模能力、迁移成本、运维复杂度、行业积累六个维度对比两款产品,帮助读者根据自身场景做出正确选择。
完美指南|如何使用 ODBC 进行无代理 Oracle 数据库监控?
文档数据库是NoSQL数据库的重要类型之一,以文档为基本存储单元,支持嵌套结构、动态字段与灵活模式。相比传统关系型数据库,它无需预先定义严格表结构,允许同一集合内文档拥有不同字段,大幅缩短开发周期,提升业务响应效率。典型适用场景包括内容管理系统、用户行为分析、物联网设备日志聚合、个性化推荐引擎、实时消息元数据管理等。据DB-Engines 2024年4月统计,文档数据库在新建互联网应用中的采用率持
为了帮助大家构建稳固的数据库防线,本文将从实战角度出发,梳理监控的核心逻辑,并为大家盘点目前市面上最值得拥有的7款数据库监控利器。
实测SQL Server到异构数据库的6款同步工具,从功能、性能、国产兼容性三个维度横向对比。含千万级数据迁移案例和10条避坑清单,附信创环境选型决策框架
Oracle数据库密码有效期的调整
国产数据库选型和迁移是一条完整链路。本文上半部分讲选型评估(兼容性、生态、TCO三个维度),下半部分讲迁移落地(评估→适配→迁移→验证→上线五步法),附迁移工具链实战数据和避坑清单。
KSQL Developer是一款多数据库管理工具,支持KingbaseES、Oracle、MySQL、SQLServer等多种数据库。通过可视化界面,用户可以便捷地管理数据库对象(如表、视图、存储过程等),实现跨平台数据库操作。工具提供版本选择功能,满足不同开发需求。官方下载地址为https://www.kingbase.com.cn/download.html#tool。
金仓数据库KingbaseES 发挥全新潜能——kdbvector在领域中的应用举例关键字:向量索引、文本搜索、图像识别、推荐系统、视频搜索、人大金仓、KingbaseESkebvector发挥全新潜能随着数据规模的不断增长和复杂度的提升,我们对于高效处理和准确分析数据的需求也与日俱增,在这个信息爆炸的时代,如何快速找到我们所需要的信息、识别图像视频和提供个性化推荐已经成为众多行业的重要挑战之一。
ZCBUS内置高性能CDC实时捕获技术,精准对接该铁路票务综合服务平台票务系统、列车调度系统、站点运维系统、北斗定位系统等多源异构平台,无需繁琐配置,即可实现全量+增量数据的实时采集——无论是余票裂变更新、候补订单变动、列车晚点信息、客流数据波动,还是列车实时定位、站点接驳动态,均能在0-10秒内完成捕获与汇聚,从源头保障前端、中端、后端数据的实时同步,为三级机构数据上下联动奠定基础,彻底解决传统
本文为墨天轮社区整理的2021年9月国产数据库大事件和重要产品发布消息。
达梦数据库基础篇--数据库管理工具
转移linux根目录下的Oracle数据文件
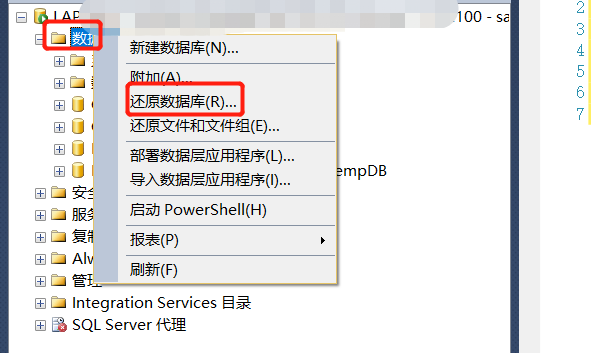
此处默认的数据库是:Gsy_RS_2020,改为要还原的数据库,所以应更改为:Gsy_TestNew。6、选择【文件】标签,勾选【将所有文件重新定位到文件夹】对话框,重新选择mdf和ldf文件。5、打开【还原数据库】对话框,在【选项】标签,更改数据库,此处选择要还原的数据库名称。3、新建一个空的数据库,比如Gsy_TestNew,将备份的数据库还原到这个新的库上。7、选择【选项】标签,勾选【覆盖现
一查执行计划,二看索引情况,三想业务场景,四测优化方案(重要的事情说三遍!!!测试!测试!一定要测试优化效果!准备好这些知识点,下次面试官问你SQL调优时,你可以微笑着反问:“您想听索引优化、执行计划分析还是实战案例?” 😎。
增删改数据添加数据(INSERT)1). 给指定字段添加数据2). 给全部字段添加数据3). 批量添加数据修改数据(UPDATE)删除数据(DELETE)查询数据基本查询(不带任何条件)1). 查询多个字段2). 字段设置别名3). 去除重复记录条件查询常用的比较运算符常用的逻辑运算符1、BETWEEN ... AND ... 在某个范围之内(含最小、最大值)2、IN(...) 在in之后的列表中
dba
——dba
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 MCP技术社区
MCP技术社区




 DeepSeek技术社区
DeepSeek技术社区

 AI Agent技术社区
AI Agent技术社区


 智能体开发者社区
智能体开发者社区


 2048 AI社区
2048 AI社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DAMO开发者矩阵
DAMO开发者矩阵