




- @oOBubbleX
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
企业数据分析面临数据分散、报表僵化、分析链路长等痛点,DataAgent(数据分析智能体)应运而生。它通过自然语言交互,基于企业数据资产自动完成问题拆解、指标计算、图表生成和结果解释,支持连续追问与分析沉淀,而不仅是一次性问答。与普通AI问数工具不同,DataAgent需具备统一指标口径、数据权限控制和可追溯分析过程等企业级能力。FineBINext等工具通过整合BI全链路,将AI生成的分析内容转

国产数据库风云:老牌与新贵的市场博弈 摘要:中国数据库市场正经历代际更迭,以达梦、人大金仓为代表的传统国产数据库厂商,与OceanBase等互联网背景的新锐力量形成鲜明对比。前者凭借政府订单和政策扶持积累20年行业经验,后者则依托互联网高并发场景和资本优势实现快速崛起。分析显示,两者差距主要体现在四大维度:服务场景差异导致技术路线分化(政务系统的稳态需求vs电商的高并发挑战)、组织驱动逻辑不同(订
本文探讨了企业财务管理报表自动化的三种主流解决方案及其适用场景。评测维度包括数据整合能力、报表灵活性、分摊透明度、分析深度和可维护性。用友ERP原生方案适合深度使用其生态的企业;自研Python方案适合需求简单的小团队但存在隐性成本;帆软财经数智化方案提供完整的数据-报表-分析闭环,适合中大型企业。选型需避免三大误区:忽视指标管理、轻视数据底座、忽略交接风险。建议企业根据发展阶段选择方案,复杂需求
这篇文章用通俗易懂的语言介绍了数据挖掘中的10个经典算法。首先将算法分为三类:找关系的关联分析、做分类的分类算法和自动分组的聚类算法。然后重点讲解了PageRank、Apriori、AdaBoost等入门算法,以及C4.5、朴素贝叶斯、SVM等分类算法和K-Means、EM等聚类算法的核心思想与实际应用场景。文章强调理解算法原理比死记硬背更重要,并建议结合具体业务需求选择合适的算法。最后指出数据准

数据库采集常用Sqoop等ETL工具,网络采集依赖爬虫技术,文件采集则需Flume等日志工具,三种方式常需并行实施。 预处理环节包含数据清理、集成、转换和规约四个步骤,确保后续分析的数据质量。存储环节需因地制宜:MPP架构适合结构化数据,Hadoop生态处理非结构化数据,一体机方案则提供开箱即用的便利。
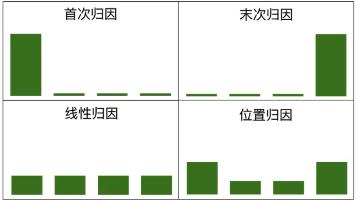
本文介绍了10种实用的数据分析方法,帮助挖掘数据价值。包括描述性分析、对比分析、漏斗分析、归因分析、同期群分析、聚类分析、回归分析、时间序列分析、AB测试、杜邦分析和ABC分析。每种方法都结合实际应用场景,如用户留存分析、营销效果评估、销售预测等,并强调要根据具体业务需求选择合适的方法。
云计算是一种按需租用计算资源的基础服务模式,解决了传统IT部署中的三大痛点:高初始投入成本、资源闲置浪费和扩展灵活性差。云服务分为三个层次:IaaS提供虚拟化基础设施,PaaS提供开发平台环境,SaaS提供开箱即用的软件服务。云计算的核心价值在于降低起步成本、实现弹性伸缩、提高系统可靠性、简化运维工作并加速创新周期。对于数据分析工作而言,云计算使临时获取强大计算能力成为可能,配合云端数据集成工具可

数据分析、数据统计与数据挖掘的核心区别在于应用目标和业务场景。数据统计重在验证数据规律(如A/B测试、假设检验),确保结论可靠;数据分析侧重业务问题拆解(如指标拆解、趋势分析),将数据转化为可执行方案;数据挖掘则从海量数据中发现隐藏模式(如预测模型、关联规则),支持自动化决策。企业应根据具体需求选择方法:经营复盘用数据分析,结论验证用数据统计,预测识别用数据挖掘。三者需协同使用,但落地优先级建议先
本文总结了10种实用数据分析方法,帮助从业者避免常见误区。核心观点强调:数据分析重在选对工具而非追求复杂模型。方法包括:描述性统计(基础分析)、EDA(探索数据特征)、假设检验(验证猜想)、回归分析(因果关系)、聚类分析(无监督分组)、相关分析(关联关系)、时间序列(趋势预测)、空间数据(地理分析)、生存分析(事件时间预测)和信度分析(测量工具评估)。每种方法均给出定义、用途和实操要点,并推荐使用
数据字典是一种对数据的定义和描述的集合,它包含了数据的名称、类型、长度、取值范围、业务含义、数据来源等详细信息。数据字典的主要作用如下:1. 对于数据开发者来说,数据字典包含了关于数据结构和内容的清晰指南,能够让开发者理解数据的含义和用途,从而更准确地进行数据开发和维护工作。2. 对于业务人员来说,数据字典可以帮助理解数据的业务含义,更好地进行数据分析和决策。比如,业务人员在查看销售报表时,可以通
