




- @Gefangenes
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Room是Google官方推荐使用的数据库,相比较某些优秀数据库框架来说,不用过于担心某天库会停止维护,且访问数据库非常流畅,并且提供了与常规的ORM框架一样,通过添加编译期注解来进行表和字段的配置,譬如@Database、@Dao、@Entity、@Query、@Insert、@Update、@Detele等的注解,可以使用简单代码实现相比以前SQLite更复杂的代码的效果,这点儿有点儿类似于j

所谓深度神经网络的优化算法,即用来更新神经网络参数,并使损失函数最小化的算法。优化算法对于深度学习非常重要,如果说网络参数初始化(模型迭代的初始点)能够决定模型是否收敛,那优化算法的性能则直接影响模型的训练效率。了解不同优化算法的原理及其超参数的作用将使我们更有效的调整优化器的超参数,从而提高模型的性能。本文的优化算法特指: 寻找神经网络上的一组参数 θ,它能显著地降低损失函数 J(θ),该损失函

本文使用Python实现了PCA算法,并使用ORL人脸数据集进行了测试并输出特征脸,简单实现了人脸识别的功能。PCA可以实现简单的人脸识别。
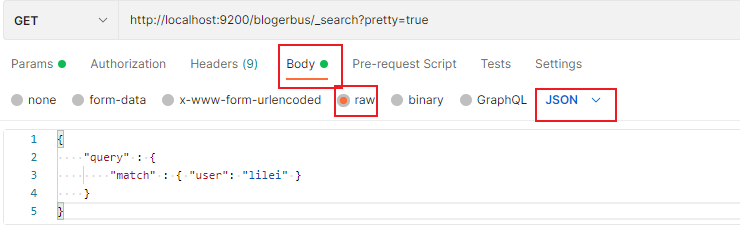
Elasticsearh 是elastic.co公司开发的分布式搜索引擎。Elasticsearch(简称ES)是一个开源的分布式、高度可扩展的全文搜索和分析引擎。它能够快速、近乎实时的存储、搜索和分析大量数据。适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型数据。它通常为具有复杂搜索功能的应用提供底层搜索技术。当然,它也可以用来实现分布式数据存储、日志统计、分析、系统监控、地
在计算机中,字节序指的是在存储器中,多字节数据的字节存放顺序。大小端是计算机体系结构中的一个概念,用于表示在多字节数据类型中,字节的顺序。在不同的计算机体系结构中,字节顺序可能不同。一些处理器将最高位字节存储在地址最低的位置,这被称为“大端字节序”(高位字节排放在内存的低地址端,低位字节排放在内存的高地址端),而另一些处理器将最低位字节存储在地址最低的位置,这被称为“小端字节序”(低位字节排放在内

GPT4All支持多种不同大小和类型的模型,用户可以按需选择。序号模型许可介绍1商业许可基于GPT-J,在全新GPT4All数据集上训练2非商业许可基于Llama 13b,在全新GPT4All数据集上训练3商业许可基于GPT-J,在v2 GPT4All数据集上训练。4商业许可基于GPT-J,在v1 GPT4All数据集上训练5商业许可基于GPT-J,在v0 GPT4All数据集上训练6非商业许可。
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。它由一系列的C函数和少量C++类构成,同时提供Python、Java和MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。# 导入OpenCV库import cv2# 打印OpenCV版本4.5.2OpenCV的设计目标是提供一套简单而且可扩展的计算机视
Jaeger是受到 Dapper 和 OpenZipkin 启发的由 Uber Technologies 作为开源发布的分布式跟踪系统,兼容 OpenTracing 以及 Zipkin 追踪格式,目前已成为 CNCF 基金会的开源项目。其前端采用React语言实现,后端采用GO语言实现,适用于进行链路追踪,分布式跟踪消息传递,分布式事务监控、问题分析、服务依赖性分
HarmonyOS API 17正式发布,DevEco新增多项重要特性。本次更新支持创建API 17应用,并首次提供折叠手机和2in1设备模拟器支持。重点改进包括:新增34个ACL权限管理功能(其中2个为新权限),实现自动签名申请;优化WebView调试功能,支持自动监听进程转发端口;系统能力增强,新增窗口尺寸指定、AREngine深度估计、2in1设备适配优化等功能;引入FileManagerS
HarmonyOS中的"Want"是一个用于定义和控制应用程序之间通信的基本概念。它可以用来描述一个应用程序对某个特定操作的需求或意愿,比如获取某个设备的位置信息、访问某个传感器的数据等。使用"Want"可以实现应用程序之间的无缝协作和互操作。通过定义和使用"Wants",应用程序可以根据自身的需求发送请求,并且可以接收和处理其他应用程序发送的请求。这种机制能够促进应用程序之间的交互和共享,并且使