登录社区云,与社区用户共同成长
邀请您加入社区
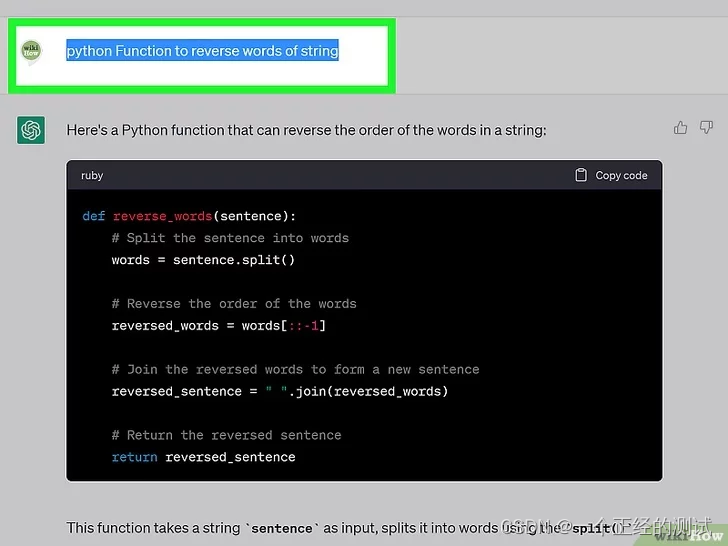
Selenium 是一个用于自动化测试的开源框架。它提供了多种工具和库,用于模拟用户在不同浏览器和操作系统上的行为,并且可用于测试网页应用程序。
摘要:软件测试从业者向AI算法转型面临机遇与挑战。AI算法岗位需求旺盛且薪资优厚,测试人员在逻辑分析和问题排查方面具备天然优势。本文提出7个月转型路径:1-2月建立数学基础和Python技能;3-4月通过实践掌握机器学习算法;5-6月进阶学习深度学习和大模型;第7个月优化简历并准备面试。关键要避免认知偏差、脱离实践和缺乏工程思维等陷阱,建议结合测试场景开发AI应用案例,突出测试+AI的复合优势,最
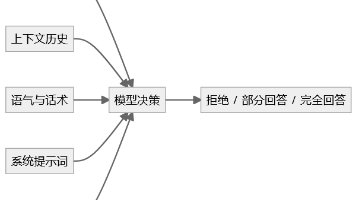
PNAS 这篇论文最值得我们警惕的地方,不是“大模型被人类话术骗了”这个表面结论。大模型的安全边界,会受到语言策略、上下文关系和交互过程影响。这意味着,AI 系统不能只靠几条规则、几个敏感词、一个安全 Prompt 就放心上线。对测试人来说,下一阶段的核心任务不是简单问一句:“模型会不会拒绝?而是要追问:换一种说法还会拒绝吗?多聊几轮还会拒绝吗?用户伪装成专家还会拒绝吗?模型接入工具后还会拒绝吗?
回归测试工具包括 Playwright、Lost Pixel、CueCast、Selenium、Ranorex、Katalon Studio 和 TestComplete。从开源/商业、代码/零代码、Web/桌面/移动等维度对比适用场景,帮助团队根据技术能力、测试范围和维护成本选择合适的回归测试方案。
混合同错位(cross-record hallucination 或 cross-record mixup)指模型在处理一批合同记录时,把 A 合同的 URL、B 合同的内容、C 合同的业务场景混在一起输出。这意味着:如果你给模型一次性输入了 200 条合同,模型不会理解“这是 200 条独立样本”,它会认为这是“一个巨大的语料库”,并在其中“寻找它认为合理的关联”。你之前遇到的这段就是典型“混合
Selenium是Thought Works公司开发的一套基于web应用的自动化测试工具,直接运行在浏览器中,模拟用户操作。它可以被用于单元测试、集成测试、回归测试、系统测试、冒烟测试、验收测试,并且可以运行在各种浏览器和操作系统上。目前使用selenium的人群大概有两大类吧,一类是软件测试工程师,他们可以通过selenium来实现自动化的测试,以提高回归测试的效率,降低人员的执行成本。
## 九、总结与建议| 场景 | 推荐工具 | 原因 ||------|---------|------|| 爬虫/数据采集 | Playwright | 反检测能力强、并发性能好 || 自动化测试 | Playwright | 跨浏览器支持、自动等待 || 快速原型 | Puppeteer | Node.js生态、轻量 || 企业级测试 | Selenium | 语言生态丰富、社区成熟 || A
AI写代码的速度,早就超过了人类维护测试脚本的速度。本文部分内容参考了霍格沃兹测试开发学社整理的相关技术资料,主要涉及软件测试、自动化测试、测试开发及 AI 测试等内容,侧重测试实践、工具应用与工程经验整理。传统测试脚本的抽象层次是“操作”,AI框架的抽象层次是“业务目标”。结果就是:CI上30%的失败是flaky测试,不是真正的bug。QA Wolf用多个专门的AI agent分工协作:有的识别
若配置-e、-E则须配置-b来指定应用。
兼容性问题:部分API在鸿蒙不同版本中存在差异,需在测试中动态适配。性能瓶颈:高频操作可能导致UI卡顿,需结合Profiler工具优化。
程序在运行时会不会出现未响应,或者终止异常操作等,还有一些属于鸿蒙系统独有特色功能的测试,比如流转测试,关注好流转交互一致性、跨端迁移功能、多端协同功能等。
应用测试的核心环节,旨在验证应用的功能是否符合需求规格说明。测试需覆盖用户交互、业务逻辑、数据流等关键场景,确保应用在鸿蒙系统上的稳定性和正确性。这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!1. 准备测试设备:使用真机进行测试,确保设备系统版本与目标应用兼容。1. 用户界面测试:验证页面跳转、控件响应(如按钮
ChatGPT 可以通过纠正错误、简化复杂的想法和消除错误来清理现有代码。为了节省开发人员的时间,请使用 ChatGPT 为您的应用程序创建脚手架、模板和样板代码。ChatGPT 确实会犯错误,因此它不能替代软件工程师。在实施之前始终测试 ChatGPT 代码。
建立一个只读类型的链接由于未知对方何时回复,可以把等待响应时间设置长一点
当然,postman 毕竟不是专业的性能测试工具,这些性能数据和指标需要我们自己计算,只适合用来顺手检测一下性能,对服务器的处理能力有个大概印象。然后,点击右下方的 runner 运行器,把需要测试的接口拖动到左侧展示框,在右侧设置。iterations 表示请求发起次数,Delay 表示请求间隔时间,点击运行。运行后,可以查看实时的响应结果,我们可以根据响应时间判断服务器的处理性能。
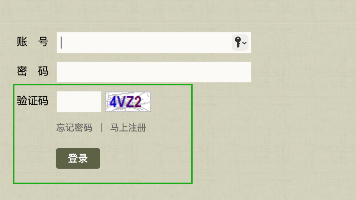
本文介绍了利用Python技术实现文字型验证码自动登录的方法。通过Selenium模拟浏览器操作,结合OpenCV图像处理和pytesseract光学字符识别技术,从古诗文网验证码中提取文字内容。文章详细展示了从截图预处理到验证码识别的完整流程,包括均值漂移平滑、灰度转化、二值化处理等关键步骤,最终实现自动化登录。特别说明了直接抓取验证码URL的局限性,强调必须通过页面截图方式来确保验证码一致性。
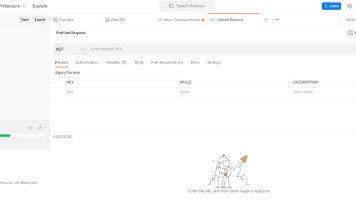
我们在做测试的过程中,都会多次请求接口,都会把接口保存下来,方便下次直接请求,节省时间不用每次都重新输入,我们一起看下如何保存接口会话。
运行集合测试,可以看到我们结果符合我们的预期,Request1 和 Request3 通过测试,Request2 被跳过,Request4 仍被执行。Done…
将jmeter extras目录下的ant-jmeter-1.1.1.jar文件拷贝到ant安装目录下的lib文件夹中,该包相当于是ant和jmeter连接的桥梁,作用是使Ant运行时能够找到"org.programmerplanet.ant.taskdefs.jmeter.JMeterTask"这个类,从而成功触发jmeter脚本。配置全局工具,进入manage jenkins --global
postman是一个非常不错的接口测试工具,不管是对于测试,还是后台开发以及前端开发。图形化,模块化,可配置化,使用起来也很直观和方便。这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取。
其中selenium+驱动+浏览器的工作原理,是通过selenium编写自动化脚本代码,然后运行该代码会发送给驱动,驱动就会根据这些请求去操控浏览器,最后浏览器执行完返回给驱动,驱动再将结果返回给脚本,实现自动化。其中前面的"webdriver.***.driver"中,***可以选择对应的浏览器名字,比如是edge的就用edge,是chrome的就用chrome,后面就是浏览器驱动下载的文件路径
我们也可以查看构建成功后的图形构建过程
info 命令:提供比man还要详细的帮助手册linux的帮助中看到命令后面中括号里面的内容 一般都是可选的注意 :并不是所有的工具都有这些帮助。
1)响应返回数据有问题,数据从数据库查询得到,猜测是否数据库本身数据就错了。查库确认,入库时bidding就存为5,而且发现之前的所有数据都为5。猜测表设计问题!
Postman 是一个功能强大且易用的 API 测试工具,无论是初学者还是经验丰富的开发者,都能从中受益。掌握 Postman 的基本操作和高级特性,能够显著提升你的 API 开发和测试效率。
Serenity BDD是2026年推荐的开源测试框架,在Selenium基础上提供增强功能。核心优势包括自动生成详细HTML报告(含截图和需求追溯)、支持BDD工具(Cucumber/JBehave)、并行测试能力、API+UI混合测试等。项目采用Maven配置,标准结构包含features、pages、steps等目录。关键实践包括现代化页面对象模式(智能等待/AJAX处理)、Screenpl
链表里存储谁调用了这个对象信息,就是引用链指向这个被引用者。每个对象维护一个引用链。如果引用链指向着为空了,说明没有人调用这个对象,那么就可以被回收了。
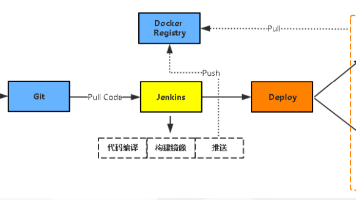
本文介绍了GitLabCI与OWASPZAP的集成方案,通过Docker容器实现自动化安全扫描。核心内容包括:1)技术架构,展示从代码提交到漏洞跟踪的完整流程;2)详细配置指南,涵盖环境准备、CI配置和扫描策略定制;3)关键问题解决方案,如认证扫描和误报处理;4)进阶功能,包括漏洞自动跟踪和质量门禁控制。实施效果显示,该方案能显著缩短漏洞修复周期(14天→3天),降低高危漏洞泄漏率(17%→2.3
核心技术包括分层架构设计、统一响应处理、全局异常拦截、登录权限校验、事务管理等解决方案设计。
本项目展示了如何利用开源工具构建企业级 E2E 监控解决方案。通过模拟真实用户行为,我们能够比传统 API 监控更早发现前端问题,为用户提供更好的体验保障。项目特点高度可配置:轻松扩展新的监控区域和模块资源优化:Headless 模式 + 内存优化参数生产就绪:完善的错误处理、重试机制和告警集成对于有类似多区域 SaaS 平台监控需求的团队,此方案具有很好的参考价值。
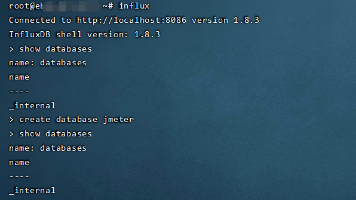
本文介绍了一个基于JMeter、Grafana和InfluxDB的性能测试监控平台搭建方案。通过Docker容器化部署这三个工具,实现性能测试数据的实时采集、存储和可视化展示。具体步骤包括:1)安装InfluxDB 1.8.3并创建数据库;2)部署Grafana用于数据可视化;3)通过Dockerfile构建JMeter 5.4.3镜像,配置测试文件挂载路径。该方案可帮助团队快速搭建智能化性能测试
selenium
——selenium
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 AI编程社区
AI编程社区



 EazyDevelop社区
EazyDevelop社区




 智能体开发者社区
智能体开发者社区


 HarmonyOS开发者社区
HarmonyOS开发者社区